So verwenden Sie Python zum Testen von SEO-Theorien (und warum Sie das tun sollten)

Bei der Arbeit an Websites mit viel Datenverkehr können Sie durch die Umsetzung von SEO-Empfehlungen ebenso viel verlieren wie gewinnen.
Das Abwärtsrisiko einer fehlgeschlagenen SEO-Implementierung kann durch den Einsatz von Modellen des maschinellen Lernens zum Vorabtesten der Rankingfaktoren in Suchmaschinen gemindert werden.
Abgesehen von den Vortests ist der Split-Test die zuverlässigste Methode zur Validierung von SEO-Theorien, bevor die Entscheidung getroffen wird, ob die Implementierung auf der gesamten Website eingeführt wird oder nicht.
Wir gehen die erforderlichen Schritte durch, wie Sie Python zum Testen Ihrer SEO-Theorien verwenden.
Wählen Sie Rangpositionen
Eine der Herausforderungen beim Testen von SEO-Theorien besteht in der großen Stichprobengröße, die erforderlich ist, damit die Testergebnisse statistisch gültig sind.
Split-Tests – populär gemacht durch Will Critchlow von SearchPilot – bevorzugen verkehrsbasierte Kennzahlen wie Klicks, was in Ordnung ist, wenn Ihr Unternehmen großflächig betrieben wird oder viel Verkehr hat.
Wenn Ihre Site nicht über diesen beneidenswerten Luxus verfügt, ist der Datenverkehr als Ergebnismetrik wahrscheinlich ein relativ seltenes Ereignis, was bedeutet, dass die Durchführung und Prüfung Ihrer Experimente zu lange dauern wird.
Betrachten Sie stattdessen die Rankingpositionen. Bei kleinen und mittleren Unternehmen, die wachsen möchten, werden die Seiten häufig für Zielschlüsselwörter gerankt, die noch nicht hoch genug ranken, um Traffic zu generieren.
Während des Testzeitraums gibt es für jeden Datenzeitpunkt, z. B. Tag, Woche oder Monat, wahrscheinlich mehrere Rangpositionsdatenpunkte für mehrere Schlüsselwörter. Im Vergleich zur Verwendung einer Verkehrsmetrik (die wahrscheinlich viel weniger Daten pro Seite und Datum enthält) reduziert sich bei Verwendung der Rangposition der erforderliche Zeitraum zum Erreichen einer Mindeststichprobengröße.
Daher eignet sich die Rangposition hervorragend für kleinere Kunden, die SEO-Split-Tests durchführen möchten und so viel schneller Erkenntnisse gewinnen können.
Die Google Search Console ist Ihr Freund
Wenn Sie sich für die Verwendung von Rangpositionen in Google entscheiden, ist die Verwendung der Datenquelle in der Google Search Console (GSC) eine unkomplizierte (und praktischerweise kostengünstige) Entscheidung – vorausgesetzt, sie ist eingerichtet.
GSC eignet sich hier gut, da es über eine API verfügt, mit der Sie im Laufe der Zeit Tausende von Datenpunkten extrahieren und nach URL-Zeichenfolgen filtern können.
Auch wenn die Daten möglicherweise nicht die reine Wahrheit sind, sind sie zumindest konsistent, was gut genug ist.
Fehlende Daten ergänzen
GSC meldet nur Daten für URLs mit Seiten. Sie müssen daher Zeilen für Daten erstellen und die fehlenden Daten einfügen.
Die verwendeten Python-Funktionen wären eine Kombination aus „merge()“ (denken Sie an die SVERWEIS-Funktion in Excel), die zum Hinzufügen fehlender Datenzeilen pro URL und zum Ausfüllen der Daten verwendet wird, die für die fehlenden Daten dieser URLs eingegeben werden sollen.
Bei den Verkehrsmetriken ist dieser Wert Null, während er bei den Ranglistenpositionen entweder der Medianwert ist (wenn Sie davon ausgehen, dass die URL einen Rang hatte, als keine Impressionen generiert wurden) oder 100 (wenn Sie davon ausgehen, dass sie keinen Rang hatte).
Der Code ist hier angegeben.
Überprüfen Sie die Verteilung und wählen Sie ein Modell aus
Die Verteilung beliebiger Daten stellt deren Beschaffenheit dar, und zwar in Bezug darauf, wo der beliebteste Wert (Modus) für eine gegebene Metrik, beispielsweise die Rangposition (in unserem Fall die gewählte Metrik), für eine gegebene Stichprobenpopulation liegt.
Die Verteilung gibt außerdem Aufschluss darüber, wie nahe die übrigen Datenpunkte am Mittelpunkt (Mittelwert oder Median) liegen, d. h. wie weit die Rangpositionen im Datensatz gestreut (oder verteilt) sind.
Dies ist von entscheidender Bedeutung, da es die Wahl des Modells bei der Auswertung Ihres SEO-Theorietests beeinflusst.
Mit Python kann dies sowohl visuell als auch analytisch erfolgen; visuell durch Ausführen des folgenden Codes:
ab_dist_box_plt = (ggplot(ab_expanded.loc[ab_expanded['position'].between(1, 90)],aes(x = 'position')) geom_histogram(alpha = 0.9, bins = 30, fill = "#b5de2b") geom_vline(xintercept=ab_expanded['position'].median(), color="red", alpha = 0.8, size=2) labs(y = '# Frequency n', x = 'nGoogle Position') scale_y_continuous(labels=lambda x: ['{:,.0f}'.format(label) for label in x]) #coord_flip() theme_light() theme(legend_position = 'bottom',axis_text_y =element_text(rotation=0, hjust=1, size = 12),legend_title = element_blank()))ab_dist_box_plt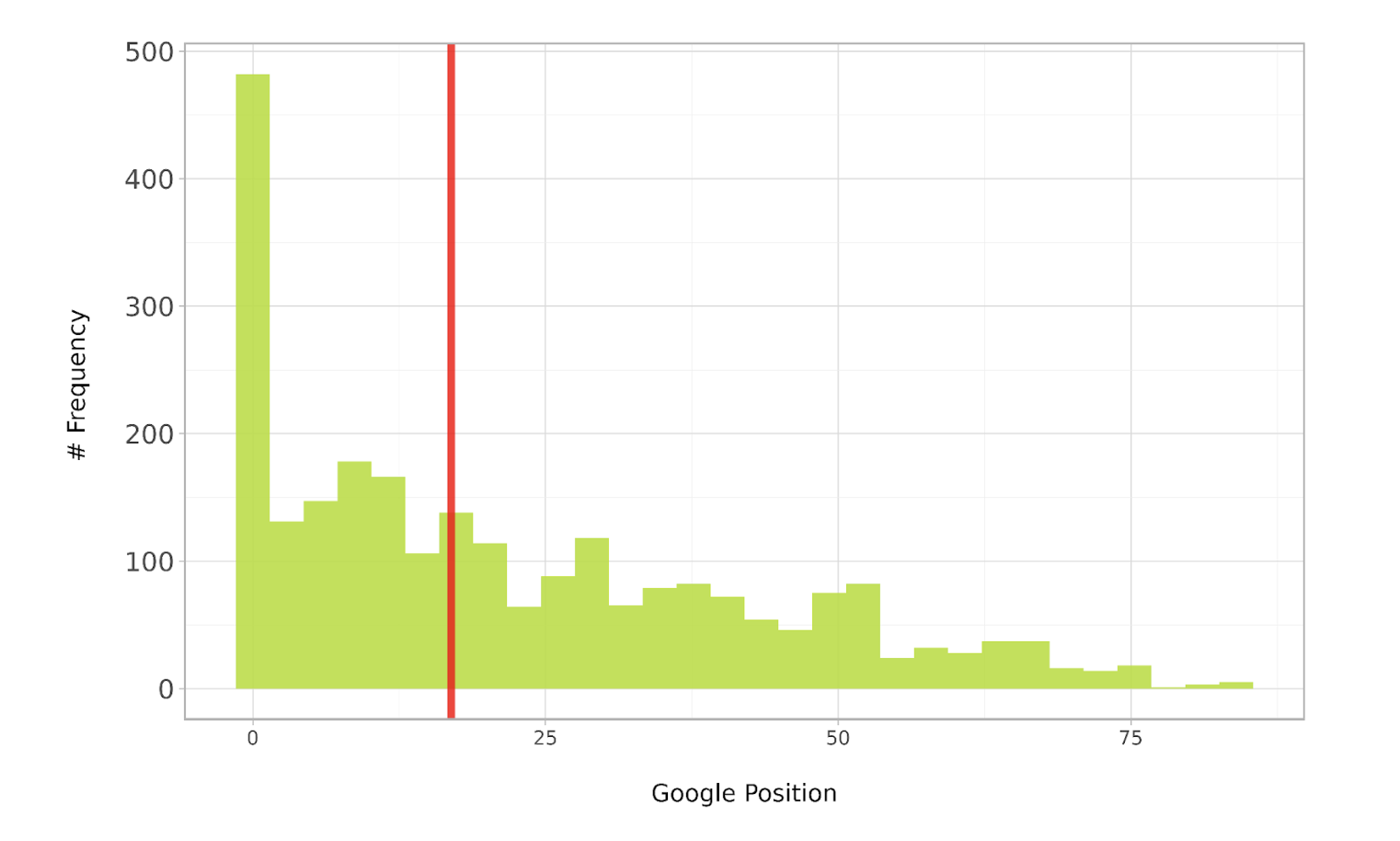 Bild vom Autor, Juli 2024
Bild vom Autor, Juli 2024Das obige Diagramm zeigt, dass die Verteilung positiv schief ist (denken Sie an einen nach rechts zeigenden Spieß), was bedeutet, dass die meisten Schlüsselwörter auf den höheren Positionen rangieren (links von der roten Mittellinie angezeigt).
Nun wissen wir, welche Teststatistik wir verwenden müssen, um zu erkennen, ob die SEO-Theorie weiterverfolgt werden sollte. In diesem Fall gibt es eine Auswahl an Modellen, die für diese Art der Verteilung geeignet sind.
Mindeststichprobengröße
Das ausgewählte Modell kann auch zur Bestimmung der erforderlichen Mindeststichprobengröße verwendet werden.
Die erforderliche Mindeststichprobengröße stellt sicher, dass alle beobachteten Unterschiede zwischen den Gruppen (sofern vorhanden) real sind und nicht auf Zufall beruhen.
Das heißt, der Unterschied als Ergebnis Ihres SEO-Experiments oder Ihrer Hypothese ist statistisch signifikant und die Wahrscheinlichkeit, dass der Test den Unterschied korrekt meldet, ist hoch (die sogenannte Power).
Dies würde durch die Simulation einer Anzahl von Zufallsverteilungen erreicht, die sowohl für Test als auch für Kontrolle dem obigen Muster entsprechen und durch die Durchführung von Tests.
Der Code ist hier angegeben.
Beim Ausführen des Codes sehen wir Folgendes:
(0.0, 0.05) 0(9.667, 1.0) 10000(17.0, 1.0) 20000(23.0, 1.0) 30000(28.333, 1.0) 40000(38.0, 1.0) 50000(39.333, 1.0) 60000(41.667, 1.0) 70000(54.333, 1.0) 80000(51.333, 1.0) 90000(59.667, 1.0) 100000(63.0, 1.0) 110000(68.333, 1.0) 120000(72.333, 1.0) 130000(76.333, 1.0) 140000(79.667, 1.0) 150000(81.667, 1.0) 160000(82.667, 1.0) 170000(85.333, 1.0) 180000(91.0, 1.0) 190000(88.667, 1.0) 200000(90.0, 1.0) 210000(90.0, 1.0) 220000(92.0, 1.0) 230000Um es genauer zu beschreiben, stellen die Zahlen im folgenden Beispiel Folgendes dar:
(39.333,: Anteil der Simulationsläufe oder Experimente, bei denen Signifikanz erreicht wird, d.h. Konsistenz des Erreichens von Signifikanz und Robustheit.
1.0) : Statistische Power, die Wahrscheinlichkeit, dass der Test die Nullhypothese korrekt ablehnt, d.h. das Experiment ist so konzipiert, dass bei diesem Stichprobengrößenniveau ein Unterschied korrekt erkannt wird.
60000: sample size
Das Obige ist interessant und für Nicht-Statistiker möglicherweise verwirrend. Einerseits legt es nahe, dass wir 230.000 Datenpunkte (bestehend aus Rangdatenpunkten während eines Zeitraums) benötigen, um eine 92-prozentige Chance zu haben, SEO-Experimente zu beobachten, die statistische Signifikanz erreichen. Andererseits erreichen wir mit 10.000 Datenpunkten statistische Signifikanz – was also sollten wir tun?
Die Erfahrung hat mich gelehrt, dass Signifikanz vorzeitig erreicht werden kann. Sie sollten daher eine Stichprobengröße anstreben, die wahrscheinlich mindestens 90 % der Zeit Bestand hat – wir werden 220.000 Datenpunkte benötigen.
Dies ist ein wirklich wichtiger Punkt, denn nachdem ich einige SEO-Teams in Unternehmen geschult hatte, beklagten sich alle darüber, dass sie schlüssige Tests durchgeführt hatten, die bei der Einführung der erfolgversprechenden Teständerungen nicht die gewünschten Ergebnisse erbrachten.
Das oben beschriebene Verfahren erspart Ihnen also den ganzen Kummer, die Zeit- und Ressourcenverschwendung sowie den Glaubwürdigkeitsschaden, der dadurch entsteht, dass Sie die Mindeststichprobengröße nicht kennen und die Tests zu früh abbrechen.
Zuweisen und Implementieren
Vor diesem Hintergrund können wir nun mit der Zuweisung von URLs zwischen Test und Kontrolle beginnen, um unsere SEO-Theorie zu testen.
In Python verwenden wir die np.where()-Funktion (Denken Sie an die erweiterte WENN-Funktion in Excel), wo wir mehrere Optionen haben, unsere Themen zu partitionieren, entweder nach URL-Zeichenfolgenmuster, Inhaltstyp, Schlüsselwörtern im Titel oder anderen, je nach der SEO-Theorie, die Sie validieren möchten.
Verwenden Sie den hier angegebenen Python-Code.
Streng genommen würden Sie dies ausführen, um im Rahmen eines neuen Experiments künftig Daten zu sammeln. Sie könnten Ihre Theorie jedoch auch rückblickend testen, vorausgesetzt, dass es keine anderen Änderungen gab, die mit der Hypothese interagieren und die Gültigkeit des Tests ändern könnten.
Das sollten Sie im Hinterkopf behalten, denn es handelt sich dabei in gewisser Weise um eine Annahme!
Prüfen
Sobald die Daten erfasst wurden oder Sie sicher sind, dass Sie über die historischen Daten verfügen, können Sie den Test ausführen.
In unserem Fall der Rangposition werden wir aufgrund seiner Verteilungseigenschaften wahrscheinlich ein Modell wie den Mann-Whitney-Test verwenden.
Wenn Sie jedoch eine andere Metrik verwenden, wie etwa Klicks, die beispielsweise Poisson-verteilt ist, dann benötigen Sie ein völlig anderes statistisches Modell.
Der Code zum Ausführen des Tests ist hier angegeben.
Nach dem Ausführen können Sie die Ausgabe der Testergebnisse ausdrucken:
Mann-Whitney U Test Test ResultsMWU Statistic: 6870.0P-Value: 0.013576443923420183Additional Summary Statistics:Test Group: n=122, mean=5.87, std=2.37Control Group: n=3340, mean=22.58, std=20.59Das Obige ist das Ergebnis eines von mir durchgeführten Experiments, das die Wirkung kommerzieller Zielseiten mit unterstützenden Blog-Leitfäden mit internen Links zu den ersteren im Vergleich zu nicht unterstützten Zielseiten zeigte.
In diesem Fall haben wir gezeigt, dass durch Content Marketing unterstützte Angebotsseiten im Durchschnitt einen um 17 Positionen höheren Google-Rang (22,58 – 5,87) aufweisen. Auch der Unterschied ist mit 98 % signifikant!
Wir brauchen jedoch mehr Zeit, um mehr Daten zu erhalten – in diesem Fall weitere 210.000 Datenpunkte. Wie bei der aktuellen Stichprobengröße können wir nur sicher sein, dass die SEO-Theorie in <10 % der Fälle reproduzierbar ist.
Split-Tests können Fähigkeiten, Wissen und Erfahrung demonstrieren
In diesem Artikel haben wir den Prozess zum Testen Ihrer SEO-Hypothesen durchlaufen und dabei die Denk- und Datenanforderungen zur Durchführung eines gültigen SEO-Tests behandelt.
Inzwischen ist Ihnen vielleicht klar geworden, dass es beim Entwerfen, Ausführen und Auswerten von SEO-Tests viel zu berücksichtigen gibt. Mein Videokurs „Data Science für SEO“ geht viel tiefer (mit mehr Code) auf die Wissenschaft der SEO-Tests ein, einschließlich Split A/A und Split A/B.
Als SEO-Experten halten wir bestimmte Kenntnisse möglicherweise für selbstverständlich, beispielsweise den Einfluss von Content-Marketing auf die SEO-Leistung.
Kunden hingegen stellen unser Wissen häufig in Frage. Daher können Split-Test-Methoden äußerst praktisch sein, um Ihre SEO-Fähigkeiten, Kenntnisse und Erfahrungen unter Beweis zu stellen!
Mehr Ressourcen:
- Verwenden von Python, um der C-Suite die Homepage-Weiterleitung zu erklären (oder eine beliebige SEO-Best Practice)
- Was Data Science für Site-Architekturen leisten kann
- Eine Einführung in Python und maschinelles Lernen für technisches SEO
Vorgestelltes Bild: UnderhilStudio/Shutterstock





