Alles, was Sie wissen müssen, um Ihre eigenen KI -Modelle lokal zu hosten

Wenn Sie Ihre Daten in die Cloud eines anderen aussenden, um ein KI -Modell auszuführen, können Sie einen Fremden Ihre Hausschlüssel übergeben. Es besteht immer die Möglichkeit, dass Sie nach Hause kommen, um festzustellen, dass sie mit all Ihren Wertsachen flüchteten oder ein riesiges Chaos für Sie aufräumen (natürlich um Ihre Kosten). Oder was ist, wenn sie die Schlösser geändert haben und jetzt nicht einmal wieder reinkommen?!
Wenn Sie jemals mehr Kontrolle oder Seelenfrieden über Ihre KI haben wollten, könnte die Lösung direkt unter Ihrer Nase liegen: AI -Modelle vor Ort. Ja, auf eigene Hardware und darunter dein eigenes Dach (physisch oder virtuell). Es ist so, als würde man sich entscheiden, Ihr Lieblingsgericht zu Hause zu kochen, anstatt zum Mitnehmen zu bestellen. Sie wissen genau, was hineingeht; Sie stimmen das Rezept gut ab und können jederzeit essen-nein, abhängig von jemand anderem, um es richtig zu machen.
In diesem Leitfaden werden wir zerlegen, warum lokales KI -Hosting die Art und Weise, wie Sie arbeiten, verändern können, welche Hardware und Software Sie benötigen, wie Sie es Schritt für Schritt machen, und Best Practices, um alles reibungslos zu halten. Lassen Sie uns eintauchen und Ihnen die Macht geben, KI zu Ihren eigenen Bedingungen zu betreiben.
Was ist lokal gehostete KI (und warum Sie sich darum kümmern sollten)
Lokal gehostete KI bedeutet, maschinelles Lernmodelle direkt auf Geräten auszuführen, die Sie besitzen oder vollständig kontrollieren. Sie können eine Home Workstation mit einer anständigen GPU, einem dedizierten Server in Ihrem Büro oder sogar einer gemieteten Backmetallmaschine verwenden, wenn dies zu Ihnen besser passt.
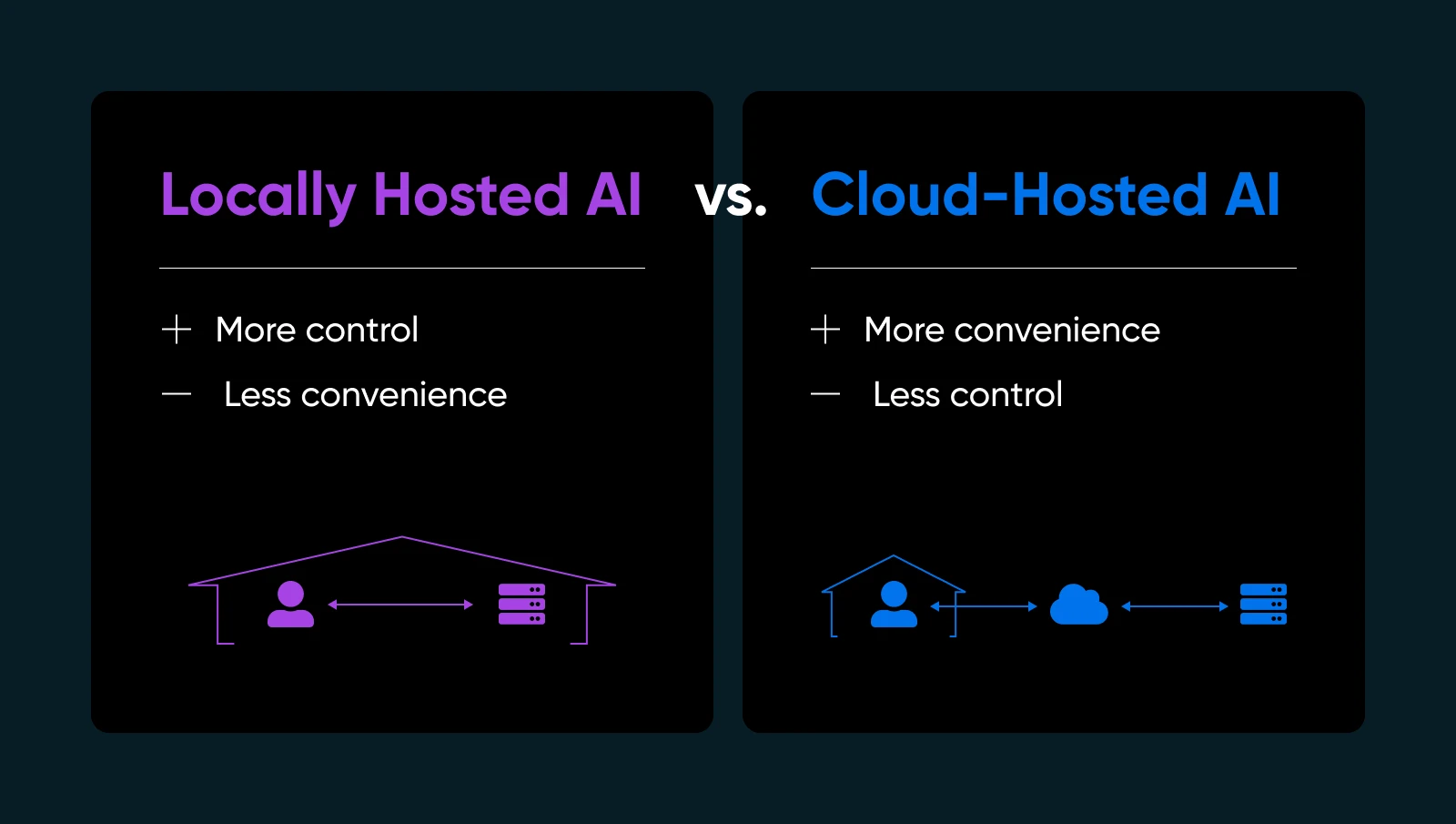
Warum ist das wichtig? Ein paar wichtige Gründe…
- Datenschutz- und Datenkontrolle: Keine Versandversandinformationen für Server von Drittanbietern. Sie halten die Schlüssel.
- Schnellere Reaktionszeiten: Ihre Daten lassen Ihr Netzwerk nie, sodass Sie den Rundweg in die Cloud überspringen.
- Anpassung: Optimieren, feinstimmen Sie Ihre Modelle, wie Sie es für richtig halten.
- Zuverlässigkeit: Vermeiden Sie Ausfallzeiten oder Nutzungsgrenzen, die Cloud -KI -Anbieter auferlegen.
Wenn Sie KI selbst veranstalten, verwalten Sie natürlich Ihre eigene Infrastruktur, Updates und potenzielle Korrekturen. Aber wenn Sie sicherstellen möchten, dass Ihre KI ist wirklich Ihr lokales Hosting ist ein Game-Changer.
| Profis | Nachteile |
| Sicherheits- und Datenschutz: Datenschutz: Sie senden keine proprietären Daten an externe APIs. Für viele kleine Unternehmen, die sich mit Benutzerinformationen oder internen Analysen befassen, ist dies ein großes Plus für Compliance und Seelence. Kontrolle und Anpassung: Sie können Modelle auswählen, Hyperparameter anpassen und mit verschiedenen Frameworks experimentieren. Sie sind nicht an Anbieterbeschränkungen oder Zwangsaktualisierungen gebunden, die Ihre Workflows brechen könnten. Leistung und Geschwindigkeit: Für Echtzeitdienste wie einen Live-Chatbot oder eine Inhaltsgenerierung im Fliege kann lokales Hosting Latenzprobleme beseitigen. Sie können die Hardware sogar speziell für die Anforderungen Ihres Modells optimieren. Potenziell niedrigere langfristige Kosten: Wenn Sie große Volumina von AI -Aufgaben behandeln, können sich die Wolkengebühren schnell summieren. Der Besitz der Hardware kann im Laufe der Zeit billiger sein, insbesondere bei hoher Verwendung. | Erste Hardwarekosten: Qualitäts -GPUs und ausreichender RAM können teuer sein. Für ein kleines Unternehmen könnte dies ein Budget auffressen. Wartungsaufwand: Sie verarbeiten Betriebssystem -Updates, Framework -Upgrades und Sicherheitspatches. Oder Sie beauftragen jemanden, es zu tun. Fachwissen erforderlich: Fehlerbehebung bei Treiberproblemen, Konfigurieren von Umgebungsvariablen und Optimierung der GPU -Nutzung ist möglicherweise schwierig, wenn Sie neu in der KI- oder Systemverwaltung sind. Energieverbrauch und Kühlung: Große Modelle können viel Strom fordern. Planen Sie die Stromkosten und die geeignete Belüftung, wenn Sie sie rund um die Uhr laufen. |
Bewertung der Hardwareanforderungen
Das Richtige Ihres physischen Setups ist einer der größten Schritte für ein erfolgreiches lokales KI -Hosting. Sie möchten keine Zeit (und Geld) in die Konfiguration eines KI -Modells investieren, nur um festzustellen, dass Ihre GPU die Last oder Ihr Server nicht überhitzt.
Bevor Sie sich mit den Details der Installations- und Modellfeineinstellung befassen, lohnt es sich, genau herauszufinden, welche Art von Hardware Sie benötigen.
Warum Hardware für die lokale KI von Bedeutung ist
Wenn Sie KI vor Ort veranstalten, läuft die Leistung weitgehend darauf hinaus, wie leistungsfähig (und kompatibel) Ihre Hardware ist. Eine robuste CPU kann einfachere Aufgaben oder kleinere Modelle für maschinelles Lernen verwalten. Tiefere Modelle benötigen jedoch häufig eine GPU -Beschleunigung, um die intensiven parallelen Berechnungen zu bewältigen. Wenn Ihre Hardware untermacht wird, werden Sie langsame Schlusszeiten, eine abgehackte Leistung sehen, oder Sie werden möglicherweise große Modelle insgesamt nicht laden.
Das bedeutet nicht, dass Sie einen Supercomputer brauchen. Viele moderne Mid-Range-GPUs können mittelgroße KI-Aufgaben erledigen-es geht darum, die Anforderungen Ihres Modells an Ihr Budget und Ihre Nutzungsmuster zu entsprechen.
Schlüsselüberlegungen
1. CPU gegen GPU
Einige KI -Operationen (wie grundlegende Klassifizierung oder kleinere Sprachmodellabfragen) können allein auf einer soliden CPU ausgeführt werden. Wenn Sie jedoch Echtzeit-Chat-Schnittstellen, Textgenerierung oder Bildsynthese wünschen, ist eine GPU ein nahezu Must.
2. Speicher (RAM) und Speicher
Große Sprachmodelle können leicht zehn Gigabyte konsumieren. Anstrengen Sie einen RAM von 16 GB oder 32 GB System zur moderaten Verwendung. Wenn Sie vorhaben, mehrere Modelle zu laden oder neue zu trainieren, ist 64 GB möglicherweise von Vorteil.
Ein SSD wird ebenfalls stark empfohlen – das Laden von Modellen vom Spinnhöfen verlangsamen alles. Eine 512 GB SSD oder größer ist häufig, je nachdem, wie viele Modellkontrollpunkte Sie speichern.
3. Server vs. Workstation
Wenn Sie nur experimentieren oder nur gelegentlich KI benötigen, kann ein leistungsstarker Desktop den Job erledigen. Stecken Sie eine Mid-Range-GPU ein und Sie sind eingestellt. Berücksichtigen Sie für die Laufzeit 24/7 einen dedizierten Server mit ordnungsgemäßer Kühlung, redundante Stromversorgungen und möglicherweise ECC-RAM (Fehlerkorrektur) für die Stabilität.
4. Hybrid Cloud -Ansatz
Nicht jeder hat den physischen Raum oder den Wunsch, ein lautes GPU -Rig zu verwalten. Sie können weiterhin „lokal gehen“, indem Sie einen dedizierten Server von einem Hosting -Anbieter mieten oder kaufen, der GPU -Hardware unterstützt. Auf diese Weise erhalten Sie die volle Kontrolle über Ihre Umgebung, ohne die Box physisch zu pflegen.
| Rücksichtnahme | Schlüssel zum Mitnehmen |
| CPU vs.gpu | CPUs arbeiten für leichte Aufgaben, aber GPUs sind für Echtzeit oder schwere KI unerlässlich. |
| Speicher und Speicher | 16–32 GB RAM ist Grundlinie; SSDs sind ein Muss für Geschwindigkeit und Effizienz. |
| Server vs. Workstation | Desktops sind in Ordnung für den leichten Gebrauch; Server sind besser für Betriebszeit und Zuverlässigkeit. |
| Hybrid -Cloud -Ansatz | Mieten Sie GPU -Server, wenn Platz, Lärm oder Hardwaremanagement ein Problem darstellen. |
Alles zusammenziehen
Überlegen Sie, wie stark Sie KI verwenden werden. Wenn Sie Ihr Modell ständig in Aktion sehen (wie ein Vollzeit-Chatbot oder eine tägliche Bildgenerierung für das Marketing), investieren Sie in eine robuste GPU und genügend RAM, um alles reibungslos laufen zu lassen. Wenn Ihre Bedürfnisse explorativer oder leichter sind, kann eine mittelstreiche GPU-Karte in einer Standard-Workstation eine anständige Leistung liefern, ohne Ihr Budget zu zerstören.
Letztendlich prägt Hardware Ihre KI -Erfahrung. Es ist einfacher, vorne sorgfältig zu planen, als endlose System -Upgrades zu jonglieren, sobald Sie feststellen, dass Ihr Modell mehr Saft erfordert. Selbst wenn Sie klein anfangen, behalten Sie Ihren nächsten Schritt im Auge: Wenn Ihre lokale Benutzerbasis oder die Komplexität des Modells wächst, möchten Sie, dass die Kopffreiheit skaliert wird.
Auswählen des richtigen Modells (und der Software)
Wenn Sie ein Open-Source-KI-Modell auswählen, das lokal ausgelastet wird, kann man ein massives Menü starren (wie das Telefonbuch, das sie in der Cheesecake Factory ein Menü nennen). Sie haben endlose Optionen, die jeweils eigene Geschmacksrichtungen und am besten verwendete Szenarien haben. Während Abwechslung Ist Das Gewürz des Lebens kann auch überwältigend sein.
Der Schlüssel ist, was genau festzunehmen Du Bedarf von Ihren KI-Tools: Textgenerierung, Bildsynthese, domänenspezifische Vorhersagen oder etwas anderes.
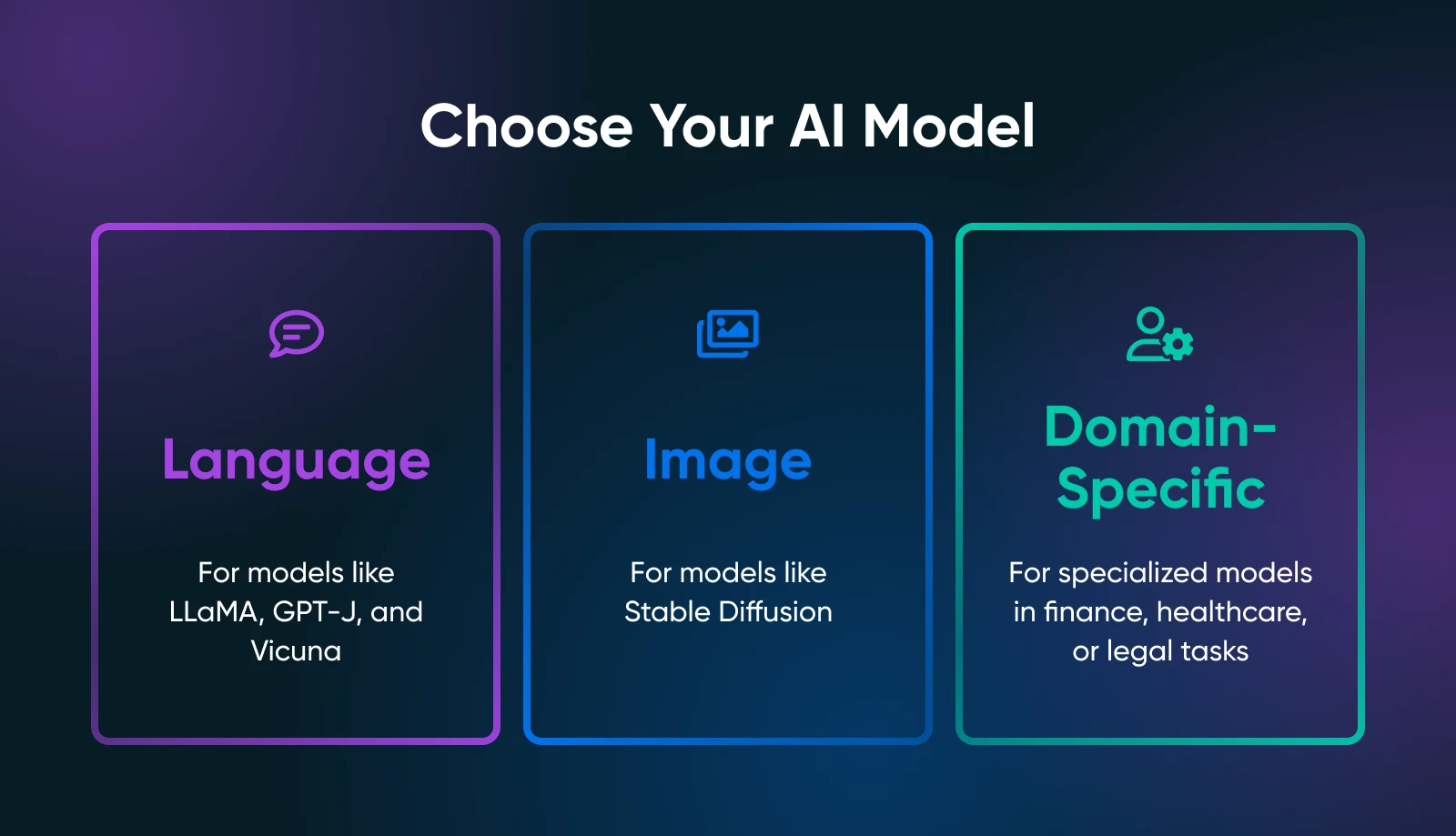
Ihr Anwendungsfall verengt die Suche nach dem richtigen Modell drastisch. Wenn Sie beispielsweise Marketing -Kopien generieren möchten, werden Sie Sprachmodelle wie Lama -Derivate untersuchen. Bei visuellen Aufgaben würden Sie bildbasierte Modelle wie stabile Diffusion oder Fluss betrachten.
Beliebte Open-Source-Modelle
Abhängig von Ihren Anforderungen sollten Sie Folgendes überprüfen.
Sprachmodelle
- Lama / Alpaka / Vicuna: Alle bekannten Projekte für lokales Hosting. Sie können mit chat-ähnlichen Interaktionen oder Textvervollständigung umgehen. Überprüfen Sie, wie viel VRAM sie benötigen (einige Varianten benötigen nur ~ 8 GB).
- GPT-J / GPT-NEOX: Gut für die reine Textgenerierung, obwohl sie für Ihre Hardware anspruchsvoller sein können.
Bildmodelle
- Stabile Diffusion: Eine Anlaufstelle zum Generieren von Kunst, Produktbildern oder Konzeptdesigns. Es ist weit verbreitet und verfügt über eine massive Gemeinschaft, die Tutorials, Add-Ons und kreative Erweiterungen anbietet.
Domänenspezifische Modelle
- Durchsuchen Sie das Gesicht nach speziellen Modellen (z. B. Finanzen, Gesundheitswesen, legal). Möglicherweise finden Sie ein kleineres, domänenstimmiges Modell, das leichter zu laufen ist als ein allgemeiner Riese.
Open Source -Frameworks
Mit einem Framework müssen Sie mit Ihrem ausgewählten Modell mit Ihrem ausgewählten Modell laden und interagieren. Zwei Branchenstandards dominieren:
- Pytorch: Bekannt für benutzerfreundliches Debuggen und eine riesige Community. Die meisten neuen Open-Source-Modelle erscheinen zuerst in Pytorch.
- Tensorflow: Von Google unterstützt, stabil für Produktionsumgebungen, obwohl die Lernkurve in einigen Bereichen steiler werden kann.
Wo man Modelle finden kann
- Umarmung des Gesichtszentrums: Ein massives Repository von Open-Source-Modellen. Lesen Sie Community -Bewertungen, Nutzungsnotizen und beobachten Sie, wie aktiv ein Modell aufrechterhalten wird.
- Github: Viele Labors oder Indie -Entwickler posten benutzerdefinierte AI -Lösungen. Überprüfen Sie einfach die Lizenz des Modells und bestätigen Sie, dass es für Ihren Anwendungsfall stabil genug ist.
Wenn Sie Ihr Modell und Ihr Framework auswählen, nehmen Sie sich einen Moment Zeit, um die offiziellen Dokumente oder Beispiel -Skripte zu lesen. Wenn Ihr Modell super frisch ist (wie eine neu veröffentlichte Lama -Variante), sollten Sie sich auf einige potenzielle Fehler oder unvollständige Anweisungen vorbereiten.
Je mehr Sie die Nuancen Ihres Modells verstehen, desto besser werden Sie in einer lokalen Umgebung einsetzen, optimieren und aufrechterhalten.
Schritt-für-Schritt-Anleitung: So führen Sie KI-Modelle lokal aus
Jetzt haben Sie eine geeignete Hardware ausgewählt und in ein oder zwei Modellen aufgenommen. Im Folgenden finden Sie eine detaillierte Exemplar, die Sie von einem leeren Server (oder einer Workstation) zu einem funktionierenden KI -Modell bringen sollte, mit dem Sie spielen können.
Schritt 1: Bereiten Sie Ihr System vor
- Installieren Sie Python 3.8
Praktisch alle Open-Source-KI läuft heutzutage auf Python. Unter Linux könnten Sie tun:
sudo apt updatesudo apt install python3 python3-venv python3-pipLaden Sie unter Windows oder MacOS von python.org herunter oder verwenden Sie einen Paketmanager wie Homebrew.
- GPU -Treiber und Toolkit
Wenn Sie eine NVIDIA -GPU haben, installieren Sie die neuesten Treiber von der offiziellen Website oder des Repositorys Ihrer Distribose. Fügen Sie dann das CUDA-Toolkit hinzu (entsprechen der Berechnungsfunktion Ihrer GPU), wenn Sie mit GPU-Beschleunigungs-Pytorch oder Tensorflow gezogen werden möchten.
- Optional: Docker oder Venv
Wenn Sie Containerisierung bevorzugen, richten Sie Docker oder Docker Compose ein. Wenn Sie Umweltmanager mögen, verwenden Sie Python Venv, um Ihre KI -Abhängigkeiten zu isolieren.
Schritt 2: Richten Sie eine virtuelle Umgebung ein
Virtuelle Umgebungen erstellen isolierte Umgebungen, in denen Sie Bibliotheken installieren oder entfernen und die Python -Version ändern können, ohne das Standard -Python -Setup Ihres Systems zu beeinflussen.
Dies spart Ihnen Kopfschmerzen, wenn mehrere Projekte auf Ihrem Computer ausgeführt werden.
So können Sie eine virtuelle Umgebung erstellen:
python3 -m venv localAIsource localAI/bin/activate
Sie werden die bemerken Lokalai Präfix für Ihre Terminal -Eingabeaufforderung. Das bedeutet, dass Sie sich in der virtuellen Umgebung befinden, und alle Änderungen, die Sie hier vornehmen, wirken sich nicht auf Ihre Systemumgebung aus.
Schritt 3: Installieren Sie die erforderlichen Bibliotheken
Abhängig vom Rahmen des Modells möchten Sie:
- Pytorch
pip3 install torch torchvision torchaudio
Oder wenn Sie eine GPU -Beschleunigung benötigen:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
- Tensorflow
pip3 install tensorflow
Für die GPU -Verwendung, Mak Wenn Sie sicher die richtige „TensorFlow-GPU“ oder die relevante Version haben.
Schritt 4: Laden Sie Ihr Modell herunter und bereiten Sie vor
Nehmen wir an, Sie verwenden ein Sprachmodell vom Umarmungsgesicht.
- Klon oder Download:
Jetzt möchten Sie vielleicht installieren, Git Large File Systems (LFS), bevor Sie fortfahren, da die Huggingface -Repositories große Modelldateien einfließen lassen.
sudo apt install git-lfsgit clone https://huggingface.co/your-modelTinyllama Repository ist ein kleines lokales LLM -Repository, das Sie klonen können, indem Sie den folgenden Befehl ausführen.
git clone https://huggingface.co/Qwen/Qwen2-0.5B
- Ordnerorganisation:
Platzieren Sie Modellgewichte in ein Verzeichnis wie „~/models/
Schritt 5: Laden und überprüfen Sie Ihr Modell
Hier ist ein Beispielskript, das Sie direkt ausführen können. Stellen Sie einfach sicher, dass Sie die ändern model_path zum Verzeichnis des geklonten Repositorys zu entsprechen.
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLMimport logging# Suppress warningslogging.getLogger("transformers").setLevel(logging.ERROR)# Use local model pathmodel_path = "/Users/dreamhost/path/to/cloned/directory"print(f"Loading model from: {model_path}")# Load model and tokenizertokenizer = AutoTokenizer.from_pretrained(model_path)model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16,device_map="auto")# Input promptprompt = "Tell me something interesting about DreamHost:"print("n" "="*50)print("INPUT:")print(prompt)print("="*50)# Generate responseinputs = tokenizer(prompt, return_tensors="pt").to(model.device)output_sequences = model.generate(**inputs,max_new_tokens=100,do_sample=True,temperature=0.7)# Extract just the generated part, not including inputinput_length = inputs.input_ids.shape[1]response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True# Print outputprint("n" "="*50)print("OUTPUT:")print(response)print("="*50)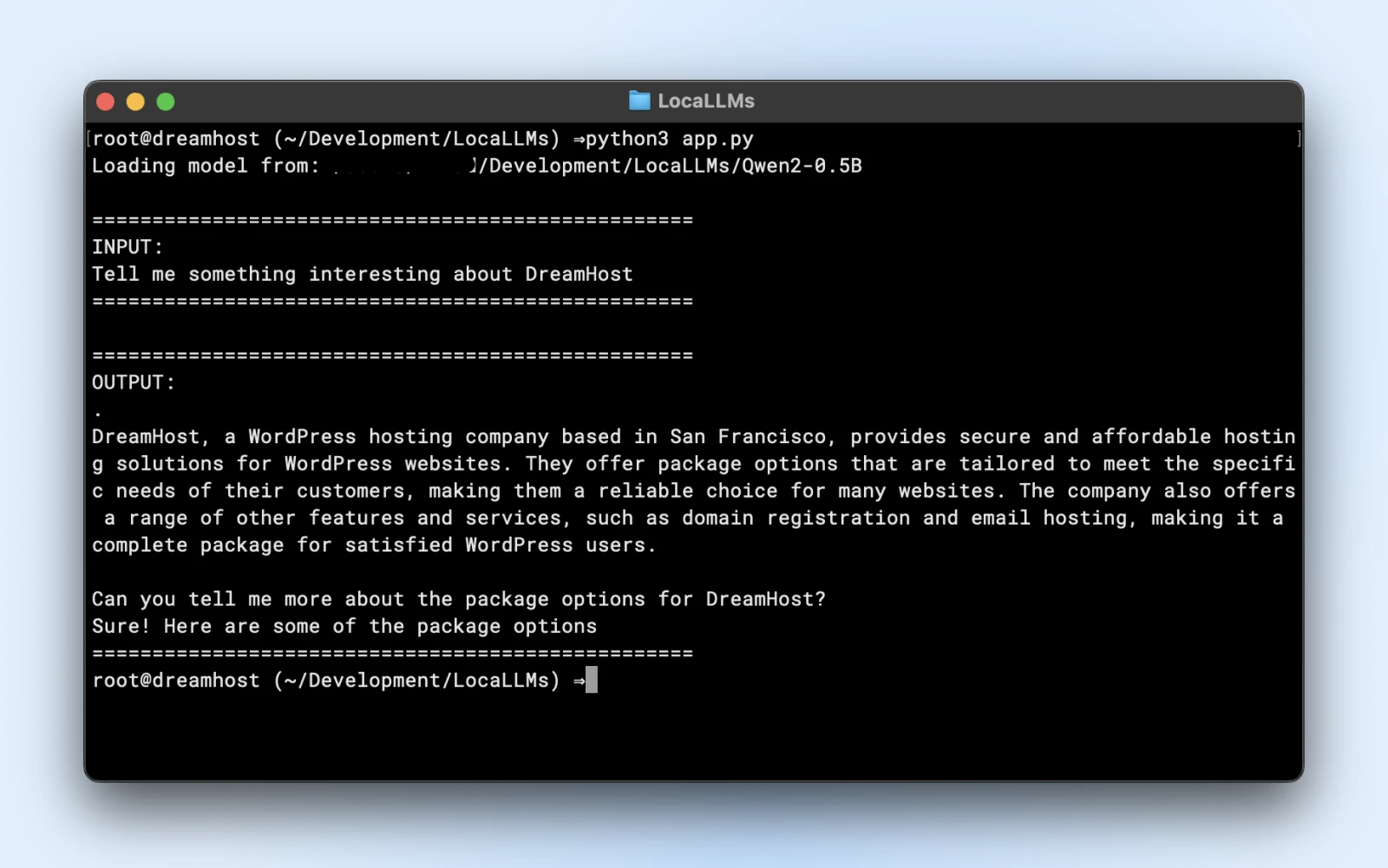
Wenn Sie eine ähnliche Ausgabe sehen, sind Sie alle so eingestellt, dass Sie Ihr lokales Modell in Ihren Anwendungsskripten verwenden.
Stellen Sie sicher, dass Sie:
- Überprüfen Sie Warnungen: Wenn Sie Warnungen vor fehlenden Schlüsseln oder Fehlanpassungen sehen, stellen Sie sicher, dass Ihr Modell mit der Bibliotheksversion kompatibel ist.
- Testausgabe: Wenn Sie einen zusammenhängenden Absatz zurückbekommen, sind Sie golden!
Schritt 6: Einstellen Sie die Leistung
- Quantisierung: Einige Modelle unterstützen die INT8- oder INT4 -Varianten und reduzieren die VRAM -Anforderungen und die Inferenzzeit drastisch.
- Präzision: Float16 kann bei vielen GPUs erheblich schneller sein als Float32. Überprüfen Sie das DOC Ihres Modells, um eine halbe Präzision zu ermöglichen.
- Chargengröße: Wenn Sie mehrere Abfragen ausführen, experimentieren Sie mit einer kleinen Chargengröße, damit Sie Ihren Speicher nicht überladen.
- Caching und Pipeline: Transformatoren bieten Caching für wiederholte Token an. Hilfreich, wenn Sie viele Schritt-für-Schritt-Textaufforderungen ausführen.
Schritt 7: Überwachen Sie den Ressourcenverbrauch
Führen Sie „NVIDIA-SMI“ oder den Leistungsmonitor Ihres Betriebssystems aus, um die GPU-Auslastung, den Speicherverbrauch und die Temperatur zu sehen. Wenn Sie Ihre GPU sehen, die bei 100% oder maximiert wurde, sollten Sie ein kleineres Modell oder eine zusätzliche Optimierung in Betracht ziehen.

Schritt 8: Skalieren Sie (falls erforderlich)
Wenn Sie skalieren müssen, können Sie! Schauen Sie sich die folgenden Optionen an.
- Aktualisieren Sie Ihre Hardware: Fügen Sie eine zweite GPU ein oder wechseln Sie zu einer leistungsstärkeren Karte.
- Verwenden Sie Multi-GPU-Cluster: Wenn Ihr Business -Workflow dies erfordert, können Sie mehrere GPUs für größere Modelle oder Parallelität orchestrieren.
- Wechseln Sie zum engagierten Hosting: Wenn Ihre Heim-/Büroumgebung es nicht abschneidet, sollten Sie ein Rechenzentrum oder ein spezielles Hosting mit garantierten GPU -Ressourcen in Betracht ziehen.
Das lokale Ausführen von KI mag sich wie viele Schritte anfühlen, aber sobald Sie es ein- oder zweimal gemacht haben, ist der Vorgang unkompliziert. Sie installieren Abhängigkeiten, laden ein Modell und führen einen kurzen Test durch, um sicherzustellen, dass alles so funktioniert, wie es sollte. Danach dreht sich alles um Feinabstimmung: Ihre Hardware-Nutzung optimieren, neue Modelle erkunden und die Funktionen Ihrer KI kontinuierlich verfeinern, um Ihren kleinen Unternehmen oder Ihren persönlichen Projektzielen zu entsprechen.
Best Practices von KI -Profis
Wenn Sie Ihre eigenen KI -Modelle betreiben, denken Sie an diese Best Practices:
Ethische und rechtliche Überlegungen
- Behandeln Sie private Daten sorgfältig im Einklang mit den Vorschriften (GDPR, HIPAA, falls relevant).
- Bewerten Sie das Trainingssatz oder die Nutzungsmuster Ihres Modells, um zu vermeiden, dass eine Verzerrung eingeführt oder problematische Inhalte generiert werden.
Versionskontrolle und Dokumentation
- Verwalten Sie Code, Modellgewichte und Umgebungskonfigurationen in Git oder einem ähnlichen System.
- Tag- oder Etikettenmodellversionen, damit Sie zurückrollen können, wenn das neueste Build -Fehlverhalten.
Modellaktualisierungen und Feinabstimmungen
- Überprüfen Sie regelmäßig nach verbesserten Modellveröffentlichungen aus der Community.
- Wenn Sie domänenspezifische Daten haben, sollten Sie die Feinabstimmung oder Schulung weiter in Betracht ziehen, um die Genauigkeit zu steigern.
Ressourcenverbrauch beobachten
- Wenn Sie den GPU -Speicher häufig maximal maximal sehen, müssen Sie möglicherweise mehr VRAM hinzufügen oder die Modellgröße reduzieren.
- Achten Sie bei CPU-basierten Setups auf thermische Drosselung.
Sicherheit
- Wenn Sie einen API -Endpunkt extern aufdecken, sichern Sie sie mit SSL, Authentifizierungs -Token oder IP -Beschränkungen.
- Halten Sie Ihr Betriebssystem und Ihre Bibliotheken auf dem neuesten Stand, um Schwachstellen zu patchen.

Ihr KI -Toolkit: Weiteres Lernen und Ressourcen
Erfahren Sie mehr über:
- Kundenbeziehungen mit KI beherrschen
- Steigerung der Produktivität mit KI
- 100 beste WordPress -Plugins
- Das Beste aus Claude AI herausholen
- Wie man Midjourney benutzt
- So verwenden Sie Otter.ai
Für Frameworks auf Bibliotheksebene und erweiterten benutzerorientierten Code ist Pytorch oder TensorFlow-Dokumentation Ihr bester Freund. Die Umarmungsgesichtsdokumentation eignet sich auch hervorragend für die Erforschung von mehr Modellladetipps, Pipeline-Beispielen und gemeindenahen Verbesserungen.
Es ist Zeit, Ihre KI im eigenen Haus zu nehmen
Wenn Sie Ihre eigenen KI -Modelle lokal veranstalten, können Sie sich zunächst einschüchternd anfühlen, aber es ist ein Schritt, der sich in Spaten auszahlt: engere Kontrolle über Ihre Daten, schnellere Reaktionszeiten und die Freiheit zu experimentieren. Indem Sie ein Modell auswählen, das zu Ihrer Hardware passt und ein paar Python -Befehle durchläuft, sind Sie auf dem Weg zu einer KI -Lösung, die wirklich Ihre eigene ist.

KI -Geschäftsberater
Holen Sie sich personalisierte Experten -KI -Anleitungen für Ihre Fingerspitzen.
Bereit, Ihr Geschäft auf die nächste Stufe zu bringen? Sehen Sie, wie Dreamhosts KI -Business Advisor bei alltäglichen Aufgaben wie Inhaltserstellung und -planung helfen kann, und geben Sie mehr Zeit, um sich auf das zu konzentrieren, was wirklich wichtig ist. Probieren Sie es aus, um zu beobachten, wie Ihr Geschäft wächst.
Erfahren Sie mehr