Beschriftet: Eine neue Welle von Bemühungen zur Kennzeichnung von KI-Inhalten

Das neue Öl bedeutet weder Daten noch Aufmerksamkeit. Es sind Worte. Das Unterscheidungsmerkmal bei der Erstellung von KI-Modellen der nächsten Generation ist der Zugriff auf Inhalte bei der Normalisierung von Rechenleistung, Speicher und Energie.
Doch das Netz wird bereits zu klein, um den Hunger nach neuen Modellen zu stillen.
Einige Führungskräfte und Forscher sagen, dass der Bedarf der Branche an hochwertigen Textdaten innerhalb von zwei Jahren das Angebot übersteigen könnte, was möglicherweise die Entwicklung von KI verlangsamt.1
Selbst die Feinabstimmung scheint nicht so gut zu funktionieren wie der einfache Bau leistungsstärkerer Modelle. Eine Microsoft-Fallstudie zeigt, dass effektive Eingabeaufforderungen ein fein abgestimmtes Modell um 27 % übertreffen können.2
Wir haben uns gefragt, ob die Zukunft aus vielen kleinen, fein abgestimmten oder ein paar großen, allumfassenden Modellen bestehen wird. Es scheint das Letztere zu sein.
Ohne Datenstrategie gibt es keine KI-Strategie.
Da sie auf der Suche nach mehr qualitativ hochwertigen Inhalten für die Entwicklung der nächsten Generation großer Sprachmodelle (LLMs) sind, beginnen Modellentwickler, für natürliche Inhalte zu bezahlen und ihre Bemühungen zur Kennzeichnung synthetischer Daten wieder aufzunehmen.
Für Content-Ersteller jeglicher Art könnte dieser neue Geldfluss den Weg zu einem neuen Content-Monetarisierungsmodell ebnen, das Anreize für Qualität schafft und das Web besser macht.
 Bildquelle: Lyna™
Bildquelle: Lyna™Steigern Sie Ihre Fähigkeiten mit den wöchentlichen Experteneinblicken von Growth Memo. Kostenlos abonnieren!
KYC: KI
Wenn Inhalte das neue Öl sind, sind soziale Netzwerke Bohrinseln. Google investiert jährlich 60 Millionen US-Dollar in die Nutzung von Reddit-Inhalten, um seine Modelle zu trainieren und Reddit-Antworten oben in der Suche anzuzeigen. Pennies, wenn Sie mich fragen.
Neal Mohan, CEO von YouTube, hat kürzlich eine klare Botschaft an OpenAI und andere Modellentwickler gesendet, dass Schulungen auf YouTube ein No-Go sind, und verteidigt die riesigen Ölreserven des Unternehmens.
Die New York Times, die derzeit eine Klage gegen OpenAI führt, veröffentlichte einen Artikel, in dem es hieß, OpenAI habe Whisper entwickelt, um Modelle auf YouTube-Transkripten zu trainieren, und Google verwende Inhalte von allen seinen Plattformen, wie Google Docs- und Maps-Rezensionen, um seine KI zu trainieren Modelle.
Anbieter generativer KI-Daten wie Appen oder Scale AI rekrutieren (menschliche) Autoren, um Inhalte für das LLM-Modelltraining zu erstellen.
Machen Sie keinen Fehler: Autoren werden nicht reich, wenn sie für KI schreiben.
Für 25 bis 50 US-Dollar pro Stunde erledigen Autoren Aufgaben wie die Bewertung von KI-Antworten, das Schreiben von Kurzgeschichten und die Überprüfung von Fakten.
Bewerber müssen über einen Doktortitel verfügen. oder Master-Abschluss oder besuchen derzeit eine Hochschule. Datenanbieter sind eindeutig auf der Suche nach Experten und „guten“ Autoren. Aber die ersten Anzeichen sind vielversprechend: Schreiben für KI könnte monetarisierbar sein.
 Bildnachweis: Kevin Indig
Bildnachweis: Kevin Indig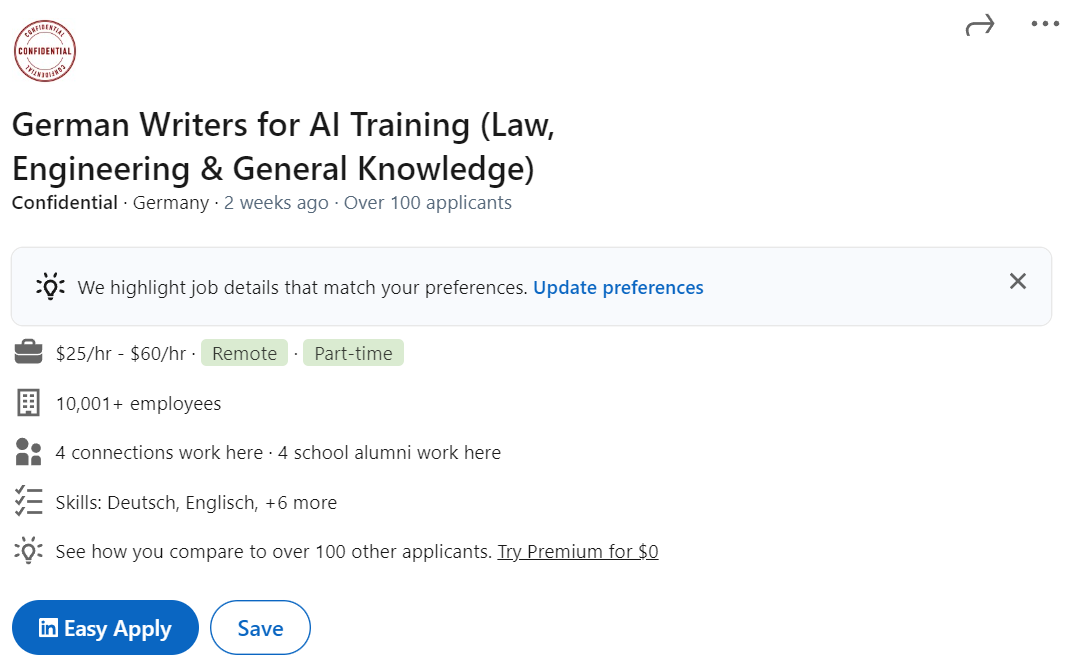 Bildnachweis: Kevin Indig
Bildnachweis: Kevin IndigModellentwickler suchen in jeder Ecke des Webs nach guten Inhalten, und einige verkaufen diese gerne.
Content-Plattformen wie Photobucket verkaufen Fotos für fünf Cent bis einen Dollar pro Stück. Kurzvideos können zwischen 2 und 4 US-Dollar kosten; Längere Filme kosten 100 bis 300 US-Dollar pro Filmstunde.
Mit Milliarden von Fotos ist das Unternehmen im Hinterhof auf Öl gestoßen. Welcher CEO kann einer solchen Versuchung widerstehen, zumal die Monetarisierung von Inhalten immer schwieriger wird?3
Aus kostenlosen Inhalten:
Verlage geraten von mehreren Seiten unter Druck:
- Nur wenige sind auf den Tod von Drittanbieter-Cookies vorbereitet.
- Soziale Netzwerke senden weniger Traffic (Meta) oder weisen eine schlechtere Qualität auf (X).
- Die meisten jungen Leute erhalten Neuigkeiten von TikTok.
- SGE zeichnet sich ab.
Ironischerweise könnte eine bessere Kennzeichnung von KI-Inhalten der LLM-Entwicklung helfen, da es einfacher ist, natürliche von synthetischen Inhalten zu unterscheiden.
In diesem Sinne liegt es im Interesse der LLM-Entwickler, KI-Inhalte zu kennzeichnen, damit sie sie vom Training ausschließen oder richtig verwenden können.
Beschriftung
Das Suchen nach Wörtern zum Trainieren von LLMs ist nur eine Seite der Entwicklung von KI-Modellen der nächsten Generation. Der andere ist die Etikettierung. Modellentwickler brauchen eine Kennzeichnung, um einen Modellkollaps zu verhindern, und die Gesellschaft braucht sie als Schutz gegen Fake News.
Eine neue Bewegung der KI-Kennzeichnung nimmt zu, obwohl OpenAI aufgrund der geringen Genauigkeit (26 %) auf Wasserzeichen verzichtet.4 Anstatt Inhalte selbst zu kennzeichnen, was sinnlos erscheint, drängen große Technologieunternehmen (Google, YouTube, Meta und TikTok) Benutzer dazu, KI-Inhalte mit Zuckerbrot und Peitsche zu kennzeichnen.
Google verfolgt einen zweigleisigen Ansatz, um KI-Spam in der Suche zu bekämpfen: Foren wie Reddit, in denen Inhalte höchstwahrscheinlich von Menschen erstellt werden, werden prominent angezeigt, und es werden Strafen verhängt.
Von AIfficiency:
Google bringt mehr Inhalte aus Foren in die SERPs, um ein Gegengewicht zu KI-Inhalten zu schaffen. Die Verifizierung ist das ultimative KI-Wasserzeichen. Auch wenn Reddit Menschen nicht daran hindern kann, KI zum Erstellen von Beiträgen oder Kommentaren zu verwenden, sind die Chancen geringer, weil die Google-Suche zwei Dinge nicht hat: Moderation und Karma.
Ja, Content Goblins haben es bereits auf Reddit abgesehen, aber die meisten der 73 Millionen täglich aktiven Nutzer liefern nützliche Antworten.1 Inhaltsmoderatoren bestrafen Spam mit Sperren oder sogar Rauswürfen. Der stärkste Qualitätsfaktor auf Reddit ist jedoch Karma, „der Reputationswert eines Benutzers, der seine Community-Beiträge widerspiegelt“. Durch einfache Up- oder Downvotes können Nutzer Autorität und Vertrauenswürdigkeit erlangen, zwei wesentliche Bestandteile der Qualitätssysteme von Google.
Google hat kürzlich klargestellt, dass es von Händlern erwartet, KI-Metadaten nicht mithilfe des IPTC-Metadatenprotokolls aus Bildern zu entfernen.
Wenn ein Bild ein Tag wie „compositeSynthetic“ hat, kann Google es überall als „KI-generiert“ kennzeichnen, nicht nur beim Einkaufen.5 Die Strafe für das Entfernen von KI-Metadaten ist unklar, aber ich stelle es mir wie eine Linkstrafe vor.
IPTC ist das gleiche Format, das Meta für Instagram, Facebook und WhatsApp verwendet. Beide Unternehmen versehen alle Inhalte, die aus ihren eigenen LLMs stammen, mit IPTC-Metatags. Je mehr Hersteller von KI-Tools bei der Markierung und Kennzeichnung von KI-Inhalten dieselben Richtlinien befolgen, desto zuverlässiger funktionieren Erkennungssysteme.
Wenn mit unserer Meta-KI-Funktion fotorealistische Bilder erstellt werden, tun wir verschiedene Maßnahmen, um sicherzustellen, dass die Leute wissen, dass KI im Spiel ist, einschließlich der Platzierung sichtbarer Markierungen, die Sie auf den Bildern sehen können, sowie der Einbettung unsichtbarer Wasserzeichen und Metadaten in Bilddateien. Die Verwendung unsichtbarer Wasserzeichen und Metadaten auf diese Weise verbessert sowohl die Robustheit dieser unsichtbaren Markierungen als auch hilft anderen Plattformen, sie zu identifizieren.6
Die Nachteile von KI-Inhalten sind gering, wenn die Inhalte wie KI aussehen. Aber wenn KI-Inhalte echt aussehen, brauchen wir Labels.
Während Werbetreibende versuchen, vom KI-Look wegzukommen, bevorzugen Content-Plattformen ihn, weil er leicht zu erkennen ist.7
Für kommerzielle Künstler und Werbetreibende hat generative KI die Macht, den kreativen Prozess enorm zu beschleunigen und personalisierte Anzeigen in großem Umfang an Kunden zu liefern – so etwas wie ein heiliger Gral in der Marketingwelt. Aber es gibt einen Haken: Viele Bilder, die KI-Modelle erzeugen, zeichnen sich durch cartoonartige Glätte, verräterische Fehler oder beides aus.
Verbraucher wenden sich bereits so sehr gegen den „KI-Look“, dass einer unheimlichen und filmischen Super Bowl-Werbung für die christliche Wohltätigkeitsorganisation He Gets Us vorgeworfen wurde, sie sei aus KI entstanden – obwohl die Bilder von einem Fotografen erstellt wurden.
YouTube hat damit begonnen, neue Richtlinien für Videoersteller durchzusetzen, die besagen, dass realistisch aussehende KI-Inhalte gekennzeichnet werden müssen.8
Die durch generative KI entstehenden Herausforderungen sind ein ständiger Schwerpunkt von YouTube, aber wir wissen, dass KI neue Risiken mit sich bringt, die böswillige Akteure während einer Wahl auszunutzen versuchen könnten. Mithilfe von KI können Inhalte generiert werden, die das Potenzial haben, Zuschauer in die Irre zu führen – insbesondere, wenn diese nicht wissen, dass das Video verändert oder synthetisch erstellt wurde. Um diesem Problem besser Rechnung zu tragen und die Zuschauer zu informieren, wenn der von ihnen angesehene Inhalt verändert oder synthetisch ist, werden wir mit der Einführung der folgenden Aktualisierungen beginnen:
- Offenlegung des Erstellers: Urheber müssen offenlegen, wenn sie veränderte oder synthetische Inhalte erstellt haben, die realistisch sind, auch unter Verwendung von KI-Tools. Dazu gehören Wahlinhalte.
- Beschriftung: Wir kennzeichnen realistisch veränderte oder synthetische Wahlinhalte, die nicht gegen unsere Richtlinien verstoßen, um den Zuschauern klar anzuzeigen, dass einige der Inhalte verändert oder synthetisch waren. Bei Wahlen wird dieses Label sowohl im Videoplayer als auch in der Videobeschreibung angezeigt und erscheint unabhängig vom Ersteller, den politischen Ansichten oder der Sprache.9
Die größte drohende Angst sind gefälschte KI-Inhalte, die die US-Präsidentschaftswahl 2024 beeinflussen könnten.
Keine Plattform möchte das Facebook des Jahres 2016 sein, das einen dauerhaften Reputationsschaden erlitt, der sich auf den Aktienkurs auswirkte.
Chinesische und russische staatliche Akteure haben bereits mit gefälschten KI-Nachrichten experimentiert und versucht, sich in die Wahlen in Taiwan und den kommenden USA einzumischen.10
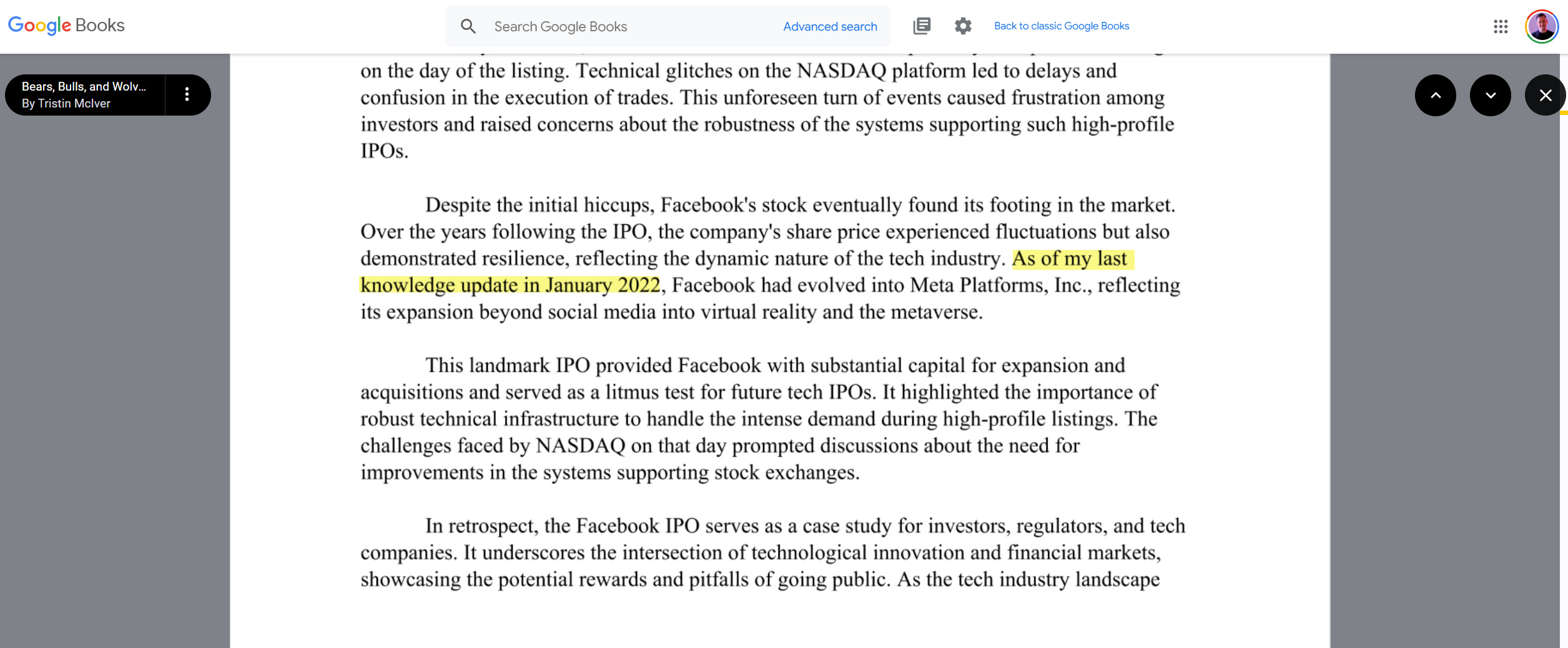
Jetzt, da OpenAI kurz vor der Veröffentlichung von Sora steht, das aus Eingabeaufforderungen hyperrealistische Videos erstellt, ist es nicht weit, sich vorzustellen, wie KI-Videos ohne strenge Kennzeichnung Probleme verursachen können. Die Situation ist schwer in den Griff zu bekommen. Google Books bietet bereits Bücher an, die eindeutig mit oder von ChatGPT geschrieben wurden.11
 Bildnachweis: Kevin Indig
Bildnachweis: Kevin IndigWegbringen
Etiketten, ob mental oder visuell, beeinflussen unsere Entscheidungen. Sie kommentieren die Welt für uns und haben die Macht, Vertrauen zu schaffen oder zu zerstören. Wie Kategorieheuristiken beim Einkaufen vereinfachen Labels unsere Entscheidungsfindung und Informationsfilterung.
Von Messy Middle:
Schließlich bietet die Idee der Kategorieheuristik, Zahlen, auf die sich Kunden konzentrieren, um die Entscheidungsfindung zu vereinfachen, wie Megapixel bei Kameras, einen Weg zur Spezifizierung der Optimierung des Benutzerverhaltens. Ein E-Commerce-Shop, der beispielsweise Kameras verkauft, sollte seine Produktkarten optimieren, um Kategorieheuristiken visuell zu priorisieren. Zugegeben, Sie müssen sich zunächst mit den Heuristiken in Ihren Kategorien vertraut machen, und diese können je nach dem von Ihnen verkauften Produkt variieren. Ich denke, das ist es, was man heutzutage braucht, um im SEO-Bereich erfolgreich zu sein.
Bald werden uns Labels mitteilen, wann Inhalte von KI geschrieben wurden oder nicht. In einer öffentlichen Umfrage unter 23.000 Befragten stellte Meta fest, dass 82 % der Menschen Kennzeichnungen für KI-Inhalte wünschen.12 Ob gemeinsame Standards und Strafen funktionieren, bleibt abzuwarten, aber die Dringlichkeit ist da.
Hier liegt auch eine Chance: Labels könnten menschliche Autoren ins Rampenlicht rücken und ihre Inhalte wertvoller machen, je nachdem, wie gut KI-Inhalte werden.
Darüber hinaus könnte das Schreiben für KI eine weitere Möglichkeit sein, Inhalte zu monetarisieren. Während die aktuellen Stundensätze niemanden reich machen, verleiht das Modelltraining den Inhalten einen neuen Mehrwert. Content-Plattformen könnten neue Einnahmequellen erschließen.
Webinhalte sind stark kommerzialisiert worden, aber die KI-Lizenzierung könnte Autoren dazu anregen, wieder gute Inhalte zu erstellen und sich von Affiliate- oder Werbeeinnahmen zu trennen.
Manchmal macht der Kontrast den Wert sichtbar. Vielleicht kann KI das Web doch noch besser machen.
1 Für datenfressende KI-Unternehmen ist das Internet zu klein
2 Die Kraft der Aufforderung
3 Im unterirdischen Wettlauf von Big Tech um den Kauf von KI-Trainingsdaten
4 OpenAI gibt das Erkennungstool für KI-generierten Text auf
5 IPTC-Fotometadaten
6 Kennzeichnung von KI-generierten Bildern auf Facebook, Instagram und Threads
7 Wie die Werbebranche dafür sorgt, dass KI-Bilder weniger wie KI aussehen
8 Wie wir Urhebern dabei helfen, veränderte oder synthetische Inhalte offenzulegen
9 Bekämpfung KI-generierter Wahl-Fehlinformationen
10 China zielt mit KI-gestützter Desinformation auf US-Wähler und Taiwan
11 Google Books indiziert KI-generierten Müll
12 Unser Ansatz zur Kennzeichnung von KI-generierten Inhalten und manipulierten Medien
Ausgewähltes Bild: Paulo Bobita/Search Engine Journal





