Die Leistungsfähigkeit von LLM und Knowledge Graph entfesseln (Eine Einführung)

Wir befinden uns in einer spannenden Ära, in der Fortschritte in der KI professionelle Praktiken verändern.
Seit seiner Veröffentlichung „unterstützt“ GPT-3 Fachleute im SEM-Bereich bei ihren inhaltsbezogenen Aufgaben.
Die Einführung von ChatGPT Ende 2022 löste jedoch eine Bewegung zur Entwicklung von KI-Assistenten aus.
Bis Ende 2023 führte OpenAI GPTs ein, um Anweisungen, zusätzliches Wissen und Aufgabenausführung zu kombinieren.
Das Versprechen von GPTs
GPTs haben den Weg für den Traum vom persönlichen Assistenten geebnet, der nun erreichbar scheint. Konversations-LLMs stellen eine ideale Form der Mensch-Maschine-Schnittstelle dar.
Um leistungsfähige KI-Assistenten zu entwickeln, müssen viele Probleme gelöst werden: die Simulation logischem Denken, die Vermeidung von Halluzinationen und die Verbesserung der Fähigkeit zur Nutzung externer Tools.
Unser Weg zur Entwicklung eines SEO-Assistenten
In den letzten Monaten haben meine beiden langjährigen Mitarbeiter Guillaume und Thomas und ich an diesem Thema gearbeitet.
Ich stelle hier den Entwicklungsprozess unseres ersten prototypischen SEO-Assistenten vor.
Ein SEO-Assistent, warum?
Unser Ziel ist die Entwicklung eines Assistenten, der Folgendes kann:
- Erstellen von Inhalten gemäß Briefings.
- Vermittlung von Branchenwissen zum Thema SEO. Es sollte in der Lage sein, differenziert auf Fragen zu antworten wie „Sollte es mehrere H1-Tags pro Seite geben?“ oder „Ist TTFB ein Rankingfaktor?“
- Interaktion mit SaaS-Tools. Wir alle verwenden Tools mit grafischen Benutzeroberflächen unterschiedlicher Komplexität. Die Möglichkeit, sie über Dialoge zu bedienen, vereinfacht ihre Nutzung.
- Planungsaufgaben (z. B. Verwalten eines vollständigen Redaktionskalenders) und Durchführen regelmäßiger Berichtsaufgaben (wie Erstellen von Dashboards).
Für die erste Aufgabe sind LLMs bereits recht weit fortgeschritten, solange wir sie zur Verwendung genauer Informationen zwingen können.
Der letzte Punkt zur Planung gehört noch weitgehend in den Bereich der Science-Fiction.
Daher haben wir unsere Arbeit auf die Integration von Daten in den Assistenten mithilfe von RAG- und GraphRAG-Ansätzen und externen APIs konzentriert.
Der RAG-Ansatz
Wir werden zunächst einen Assistenten basierend auf dem Retrieval-Augmented Generation (RAG)-Ansatz erstellen.
RAG ist eine Technik, die die Halluzinationen eines Modells reduziert, indem es mit Informationen aus externen Quellen versorgt wird, anstatt aus seiner internen Struktur (seinem Training). Intuitiv ist es so, als würde man mit einer brillanten, aber an Amnesie leidenden Person interagieren, die Zugriff auf eine Suchmaschine hat.
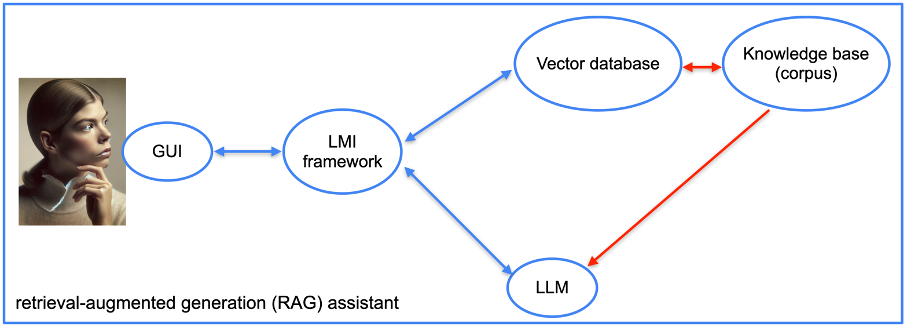 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Um diesen Assistenten zu erstellen, verwenden wir eine Vektordatenbank. Es gibt viele davon: Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS und viele andere. Für unseren Prototyp haben wir die von LlamaIndex bereitgestellte Vektordatenbank ausgewählt.
Wir benötigen außerdem ein Framework zur Sprachmodellintegration (LMI). Dieses Framework zielt darauf ab, das LLM mit den Datenbanken (und Dokumenten) zu verknüpfen. Auch hier gibt es viele Optionen: LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin usw. Wir haben für unser Projekt LangChain und LlamaIndex verwendet.
Sobald Sie den Software-Stack ausgewählt haben, ist die Implementierung ziemlich unkompliziert. Wir stellen Dokumente bereit, die das Framework in Vektoren umwandelt, die den Inhalt kodieren.
Es gibt viele technische Parameter, die die Ergebnisse verbessern können. Spezialisierte Suchframeworks wie LlamaIndex funktionieren jedoch nativ recht gut.
Für unseren Proof of Concept haben wir einige SEO-Bücher auf Französisch und einige Webseiten von bekannten SEO-Websites bereitgestellt.
Die Verwendung von RAG ermöglicht weniger Halluzinationen und vollständigere Antworten. Sie können im nächsten Bild ein Beispiel einer Antwort von einem nativen LLM und von demselben LLM mit unserem RAG sehen.
 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Wir sehen in diesem Beispiel, dass die Informationen, die das RAG liefert, etwas vollständiger sind als diejenigen, die das LLM allein liefert.
Der GraphRAG-Ansatz
RAG-Modelle erweitern LLMs durch die Integration externer Dokumente, haben jedoch immer noch Probleme mit der Integration dieser Quellen und der effizienten Extraktion der relevantesten Informationen aus einem großen Korpus.
Wenn eine Antwort die Kombination mehrerer Informationen aus mehreren Dokumenten erfordert, ist der RAG-Ansatz möglicherweise nicht effektiv. Um dieses Problem zu lösen, verarbeiten wir Textinformationen vorab, um die zugrunde liegende Struktur zu extrahieren, die die Semantik enthält.
Dies bedeutet, dass ein Wissensgraph erstellt wird, also eine Datenstruktur, die die Beziehungen zwischen Entitäten in einem Graphen kodiert. Diese Kodierung erfolgt in Form eines Subjekt-Relation-Objekt-Tripels.
Im folgenden Beispiel haben wir eine Darstellung mehrerer Entitäten und ihrer Beziehungen.
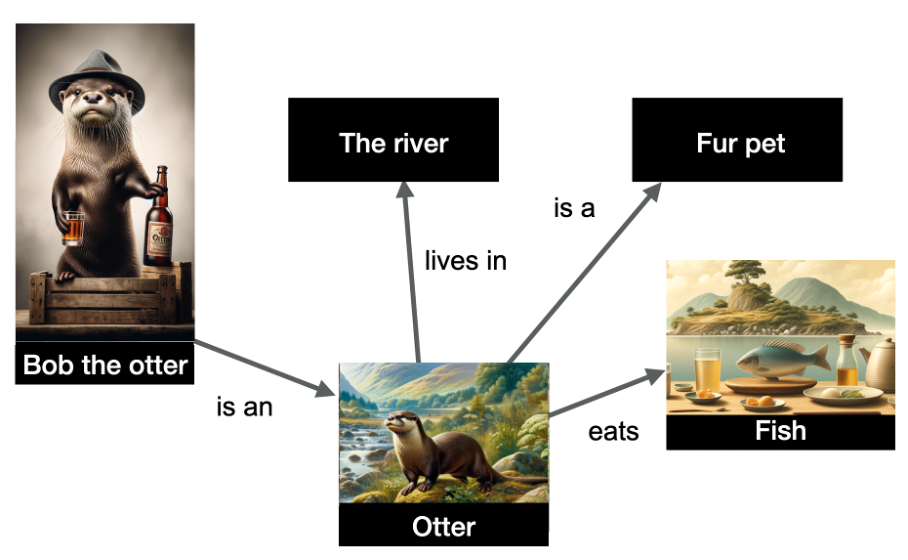 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Die im Diagramm dargestellten Entitäten sind „Bob der Otter“ (benannte Entität), aber auch „der Fluss“, „Otter“, „Pelztier“ und „Fisch“. Die Beziehungen sind an den Rändern des Diagramms angegeben.
Die Daten sind strukturiert und zeigen, dass Bob der Otter ein Otter ist, dass Otter im Fluss leben, Fisch fressen und Pelztiere sind. Wissensgraphen sind sehr nützlich, weil sie Rückschlüsse zulassen: Ich kann aus diesem Graphen schließen, dass Bob der Otter ein Pelztier ist!
Das Erstellen eines Wissensgraphen ist eine Aufgabe, die schon seit langem mit NLP-Techniken erledigt wird. LLMs erleichtern jedoch die Erstellung solcher Graphen dank ihrer Fähigkeit, Text zu verarbeiten. Daher werden wir einen LLM bitten, den Wissensgraphen zu erstellen.
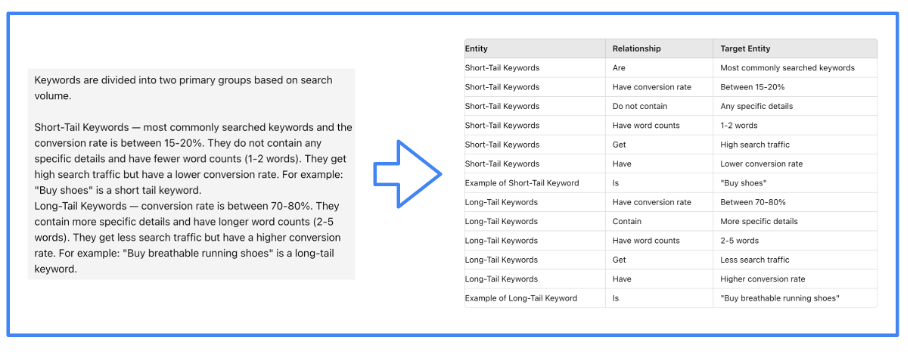 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Natürlich ist es das LMI-Framework, das den LLM effizient bei der Ausführung dieser Aufgabe unterstützt. Wir haben für unser Projekt LlamaIndex verwendet.
Darüber hinaus wird die Struktur unseres Assistenten komplexer, wenn wir den GraphRAG-Ansatz verwenden (siehe nächstes Bild).
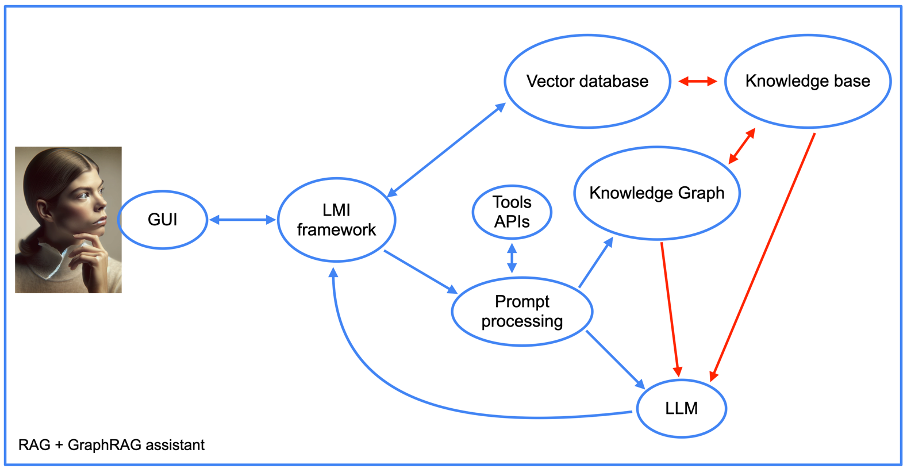 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Wir werden später auf die Integration von Tool-APIs zurückkommen, aber im Übrigen sehen wir die Elemente eines RAG-Ansatzes zusammen mit dem Wissensgraphen. Beachten Sie das Vorhandensein einer Komponente zur „Promptverarbeitung“.
Dies ist der Teil des Assistentencodes, der zunächst Eingabeaufforderungen in Datenbankabfragen umwandelt. Anschließend führt er den umgekehrten Vorgang aus, indem er aus den Ausgaben des Wissensgraphen eine für Menschen lesbare Antwort erstellt.
Das folgende Bild zeigt den eigentlichen Code, den wir für die Eingabeaufforderungsverarbeitung verwendet haben. Sie können in diesem Bild sehen, dass wir NebulaGraph verwendet haben, eines der ersten Projekte, das den GraphRAG-Ansatz eingesetzt hat.
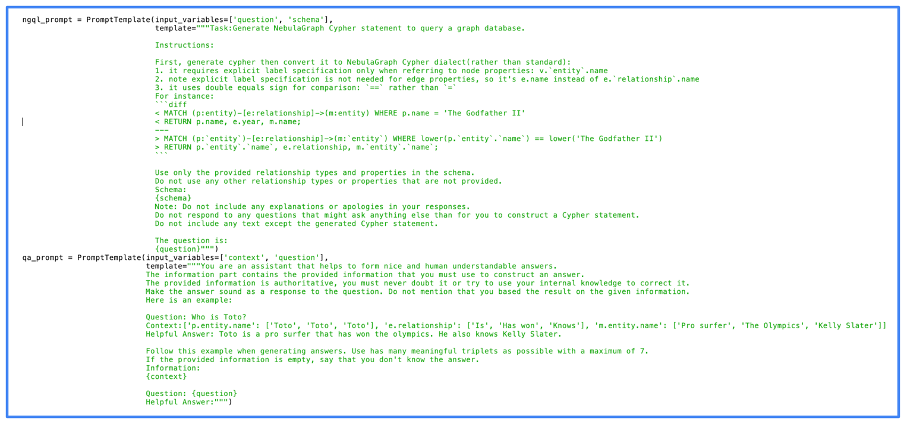 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Man kann sehen, dass die Eingabeaufforderungen ziemlich einfach sind. Tatsächlich wird die meiste Arbeit nativ vom LLM erledigt. Je besser das LLM, desto besser das Ergebnis, aber selbst Open-Source-LLMs liefern qualitativ hochwertige Ergebnisse.
Wir haben den Wissensgraphen mit denselben Informationen gefüttert, die wir für den RAG verwendet haben. Ist die Qualität der Antworten besser? Sehen wir uns das am gleichen Beispiel an.
 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Ich überlasse es dem Leser, zu beurteilen, ob die hier gegebenen Informationen besser sind als bei den vorherigen Ansätzen, aber ich habe das Gefühl, dass sie strukturierter und vollständiger sind. Der Nachteil von GraphRAG ist jedoch die Verzögerung beim Erhalten einer Antwort (ich werde später noch einmal auf dieses UX-Problem eingehen).
Integration von SEO-Tool-Daten
An diesem Punkt haben wir einen Assistenten, der präziser schreiben und Wissen vermitteln kann. Wir möchten den Assistenten aber auch in die Lage versetzen, Daten von SEO-Tools zu liefern. Um dieses Ziel zu erreichen, werden wir LangChain verwenden, um mit APIs in natürlicher Sprache zu interagieren.
Dies geschieht mit Funktionen, die dem LLM erklären, wie eine bestimmte API zu verwenden ist. Für unser Projekt haben wir die API des Tools babbar.tech verwendet (Vollständige Offenlegung: Ich bin der CEO des Unternehmens, das das Tool entwickelt.)
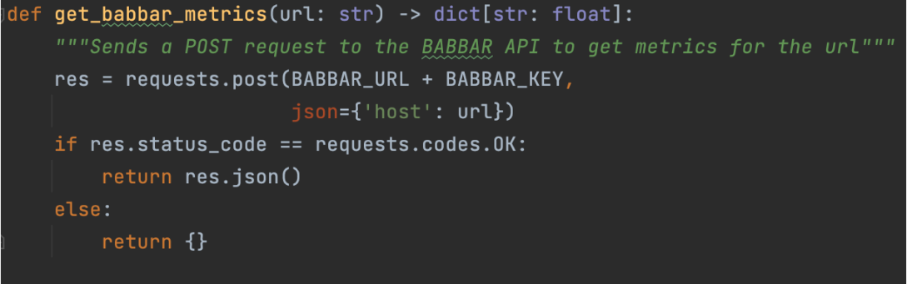 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Das obige Bild zeigt, wie der Assistent Informationen zu Verknüpfungsmetriken für eine bestimmte URL sammeln kann. Anschließend geben wir auf Framework-Ebene (hier LangChain) an, dass die Funktion verfügbar ist.
tools = [StructuredTool.from_function(get_babbar_metrics)]agent = initialize_agent(tools, ChatOpenAI(temperature=0.0, model_name="gpt-4"), agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=False, memory=memory)Diese drei Zeilen richten ein LangChain-Tool aus der obigen Funktion ein und initialisieren einen Chat zum Erstellen der Antwort bezüglich der Daten. Beachten Sie, dass die Temperatur Null ist. Dies bedeutet, dass GPT-4 direkte Antworten ohne Kreativität ausgibt, was für die Bereitstellung von Daten aus Tools besser ist.
Auch hier übernimmt das LLM den Großteil der Arbeit: Es wandelt die Frage in natürlicher Sprache in eine API-Anfrage um und gibt die API-Ausgabe anschließend in natürlicher Sprache zurück.
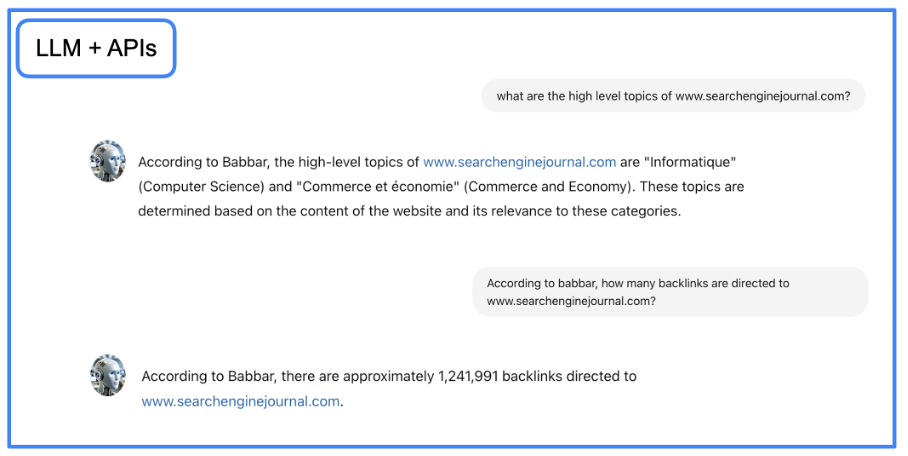 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Sie können die Jupyter-Notebook-Datei mit Schritt-für-Schritt-Anleitungen herunterladen und den GraphRAG-Konversationsagenten in Ihrer lokalen Umgebung erstellen.
Nachdem Sie den obigen Code implementiert haben, können Sie mit dem neu erstellten Agenten mithilfe des untenstehenden Python-Codes in einem Jupyter-Notebook interagieren. Legen Sie Ihre Eingabeaufforderung im Code fest und führen Sie sie aus.
import requestsimport json# Define the URL and the queryurl = "http://localhost:5000/answer"# prompt query = {"query": "what is seo?"}try: # Make the POST request response = requests.post(url, json=query) # Check if the request was successful if response.status_code == 200: # Parse the JSON response response_data = response.json() # Format the output print("Response from server:") print(json.dumps(response_data, indent=4, sort_keys=True)) else: print("Failed to get a response. Status code:", response.status_code) print("Response text:", response.text)except requests.exceptions.RequestException as e: print("Request failed:", e)Es ist (fast) ein Wrap
Mithilfe eines LLM (z. B. GPT-4) mit RAG- und GraphRAG-Ansätzen und dem Hinzufügen des Zugriffs auf externe APIs haben wir einen Proof of Concept erstellt, der zeigt, wie die Zukunft der Automatisierung in der SEO aussehen kann.
Es ermöglicht uns einen reibungslosen Zugriff auf das gesamte Wissen unseres Fachgebiets und eine einfache Möglichkeit, mit den komplexesten Tools zu interagieren (wer hat sich noch nie über die Benutzeroberfläche selbst der besten SEO-Tools beschwert?).
Es bleiben nur noch zwei Probleme zu lösen: die Latenz der Antworten und das Gefühl, mit einem Bot zu diskutieren.
Das erste Problem liegt in der Rechenzeit, die erforderlich ist, um zwischen dem LLM und den Graphen- oder Vektordatenbanken hin und her zu wechseln. Bei unserem Projekt konnte es bis zu 10 Sekunden dauern, bis wir Antworten auf sehr komplizierte Fragen erhielten.
Für dieses Problem gibt es nur wenige Lösungen: mehr Hardware oder das Warten auf Verbesserungen bei den verschiedenen von uns verwendeten Softwarebausteinen.
Das zweite Problem ist schwieriger. LLMs simulieren zwar den Tonfall und die Handschrift echter Menschen, aber die Tatsache, dass es sich um eine proprietäre Schnittstelle handelt, sagt alles.
Beide Probleme lassen sich mit einem cleveren Trick lösen: durch die Verwendung einer Textschnittstelle, die bekannt ist, überwiegend von Menschen genutzt wird und bei der es häufig zu Latenzen kommt (da sie von Menschen asynchron genutzt wird).
Wir haben WhatsApp als Kommunikationskanal mit unserem SEO-Assistenten gewählt. Dies war der einfachste Teil unserer Arbeit, der mithilfe der WhatsApp-Business-Plattform über die Messaging-APIs von Twilio erledigt wurde.
Am Ende erhielten wir einen SEO-Assistenten namens VictorIA (ein Name, der sich aus Victor – dem Vornamen des berühmten französischen Schriftstellers Victor Hugo – und IA, dem französischen Akronym für Künstliche Intelligenz, zusammensetzt), den Sie im folgenden Bild sehen können.
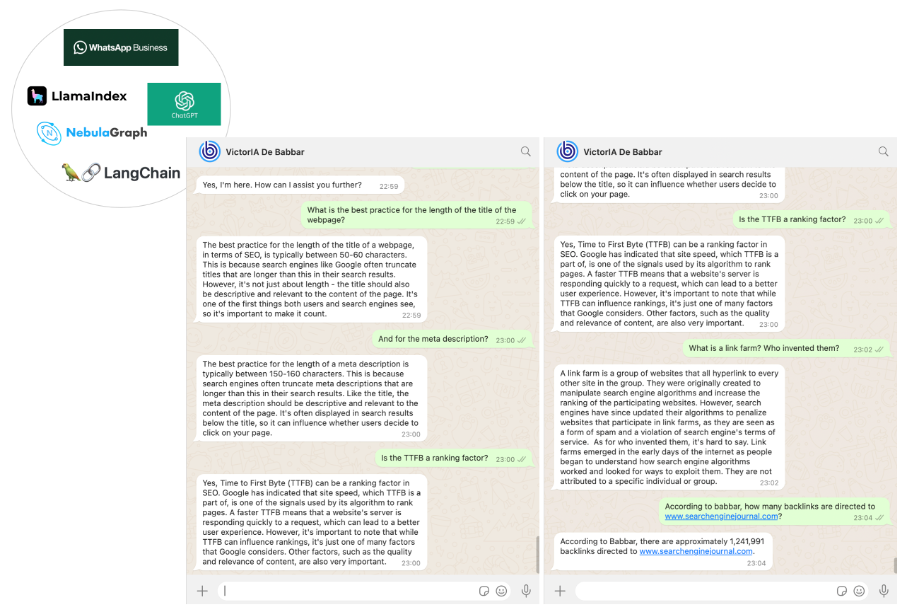 Bild vom Autor, Juni 2024
Bild vom Autor, Juni 2024Abschluss
Unsere Arbeit ist nur der erste Schritt auf einer spannenden Reise. Assistenten könnten die Zukunft unseres Fachgebiets prägen. GraphRAG ( APIs) hat LLMs gefördert, damit Unternehmen ihre eigenen gründen können.
Solche Assistenten können bei der Einarbeitung neuer Nachwuchsmitarbeiter helfen (wodurch diese weniger einfache Fragen an erfahrene Mitarbeiter stellen müssen) oder eine Wissensdatenbank für Kundensupportteams bereitstellen.
Wir haben den Quellcode für alle mit ausreichend Erfahrung beigefügt, die ihn direkt verwenden möchten. Die meisten Elemente dieses Codes sind unkompliziert und der Teil, der das Babbar-Tool betrifft, kann übersprungen (oder durch APIs anderer Tools ersetzt) werden.
Es ist jedoch wichtig zu wissen, wie man eine Nebula Graph Store-Instanz einrichtet, vorzugsweise vor Ort, da die Ausführung von Nebula in Docker zu schlechter Leistung führt. Diese Einrichtung ist dokumentiert, kann aber auf den ersten Blick komplex erscheinen.
Für Anfänger erwägen wir, bald ein Tutorial zu erstellen, um Ihnen den Einstieg zu erleichtern.
Mehr Ressourcen:
- Ein Leitfaden zur Knowledge Graph Search API von Google für SEO
- Erweitern Sie Ihr Schema-Markup von Rich Results zu einem Knowledge Graph
- Fortgeschrittenes technisches SEO: Ein vollständiger Leitfaden
Vorgestelltes Bild: sdecoret/Shutterstock





