Ein KI-angetanter Workflow zur Lösung von Inhalt Kannibalisierung

Ihre Website leidet wahrscheinlich mindestens einige inhaltliche Kannibalisierung, und Sie werden es möglicherweise nicht einmal erkennen.
Kannibalisierung schadet den organischen Verkehr und den Umsatz: Die Auswirkungen können sich von Schlüsselseiten erstrecken, die sich aufgrund der Qualität der niedrigen Domänen nicht auf Algorithmusprobleme bezeichnen.
Kannibalisierung ist jedoch schwierig zu erkennen, kann sich im Laufe der Zeit ändern und existiert in einem Spektrum.
Es ist die “Mikroplastik von SEO”.
In diesem Memo werde ich es Ihnen zeigen:
- So identifizieren und beheben Sie Inhalte Kannibalisierung zuverlässig.
- So automatisieren Sie die Erkennung von Inhalt von Kannibalisierung.
- Ein automatisierter Workflow, den Sie jetzt ausprobieren können: Der Kannibalisierungsdetektor, mein neues Keyword -Kannibalisierungsinstrument.
Ohne Nicole Guercia hätte ich das nie aus Airops tun können. Ich habe das Konzept entworfen und den automatisierten Workflow getestet, aber Nicole hat das Ganze gebaut.
Wie man über inhaltliche Kannibalisierung nachdenkt, die richtig
Bevor wir in den Workflow springen, müssen wir einige Leitprinzipien für inhaltliche Kannibalisierung klären, die oft missverstanden werden.
Das größte Missverständnis über Kannibalisierung ist, dass sie auf der Schlüsselwortebene auftritt.
Es geschieht tatsächlich auf der Intent -Ebene der Benutzer.
Wir alle müssen aufhören, dieses Konzept als Keyword -Kannibalisation und stattdessen als Kannibalisierung inhaltlich zu betrachten.
In diesem Sinne kann die Kannibalisierung…
- Ist ein bewegendes Ziel: Wenn Google das Verständnis der Absicht während eines Kernaktualisierung aktualisiert, können plötzlich zwei Seiten miteinander konkurrieren, was dies zuvor nicht getan hat.
- Existiert in einem Spektrum: Eine Seite kann mit einer anderen Seite oder mehreren Seiten konkurrieren, wobei sich eine Absicht überlappt von 10% auf 100%. Es ist schwer genau zu sagen, wie viel Überlappung in Ordnung ist, ohne die Ergebnisse und den Kontext zu betrachten.
- Hört nicht in Ranglisten auf: Die Suche nach zwei Seiten, die eine „beträchtliche“ Menge an Eindrücken oder Ranglisten für das gleiche Schlüsselwort (en) erhalten, kann Ihnen helfen, eine Kannibalisierung zu erkennen, aber es ist keine sehr genaue Methode. Es ist nicht genug Beweis.
- Benötigt regelmäßige Untersuchungen: Sie müssen Ihre Website regelmäßig auf Kannibalisierung überprüfen und Ihre Inhaltsbibliothek als „lebendiges“ Ökosystem behandeln.
- Kann hinterhältig sein: Viele Fälle sind nicht eindeutig. Zum Beispiel ist eine internationale Kannibalisierung inhaltlich nicht offensichtlich. A /EN-Verzeichnis zur Bekämpfung aller englischsprachigen Länder kann mit dem A /EN-US-Verzeichnis für den US-Markt konkurrieren.
 Bildnachweis: Kevin Indig
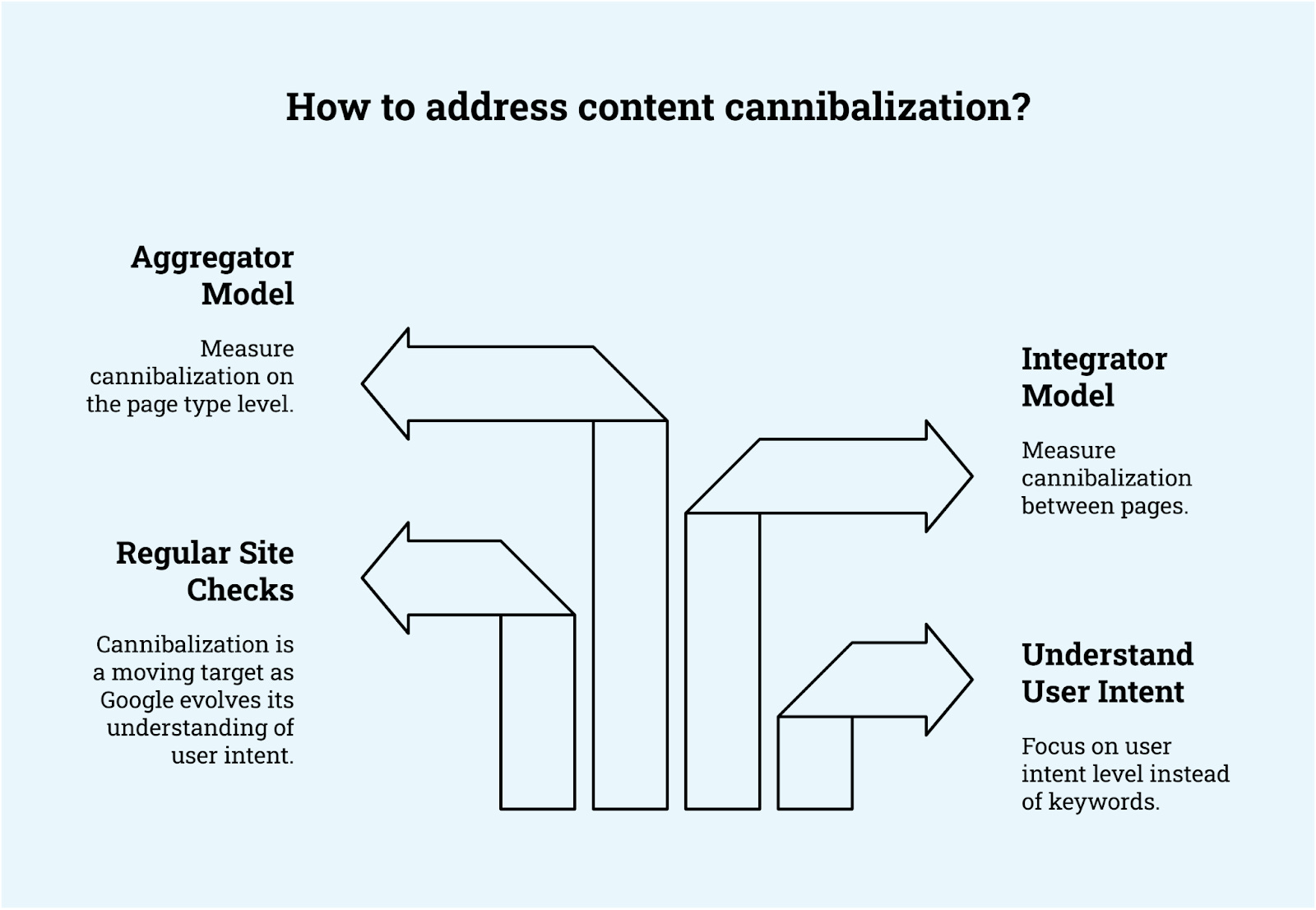
Bildnachweis: Kevin IndigVerschiedene Arten von Standorten haben grundsätzlich unterschiedliche Schwächen für Kannibalisierung.
Mein Modell für Standorttypen ist das Modell für Integrator vs. Aggregator. Online -Einzelhändler und andere Marktplätze stehen grundsätzlich unterschiedliche Fälle von Kannibalisierung als SaaS- oder D2C -Unternehmen.
Integratoren zwischen Seiten kannibalisieren. Aggregatoren kannibalisieren zwischen Seitentypen.
- Mit AggregatorenEine Kannibalisierung tritt häufig auf, wenn zwei Seitentypen zu ähnlich sind. Zum Beispiel können Sie zwei Seitenstypen haben, die miteinander konkurrieren könnten oder nicht: “Punkte von Interesse an {Stadt}” und “Dinge in {City}”.
- Mit IntegratorenEine Kannibalisierung tritt häufig auf, wenn Unternehmen neue Inhalte ohne Wartung und einen Plan für die vorhandenen Inhalte veröffentlichen. Ein großer Teil des Problems ist, dass es schwieriger wird, einen Überblick darüber zu behalten, was Sie haben und welche Schlüsselwörter/Absichten es auf eine bestimmte Anzahl von Artikeln abzielen (ich fand, dass das Linchpin rund 250 Artikel beträgt).
Wie man Inhalte Kannibalisierung erkennen
 Ein Beispiel für Kannibalisierung inhaltlich (Bildnachweis: Kevin Indig)
Ein Beispiel für Kannibalisierung inhaltlich (Bildnachweis: Kevin Indig)Cannibalisierung inhaltlich kann eine oder mehrere der folgenden Symptome haben:
- “URL Flackering”: bedeutet, dass mindestens zwei URLs für ein oder mehrere Schlüsselwörter in Ranking wechseln.
- Eine Seite verliert den Datenverkehr und/oder eine Rangliste, nachdem eine andere live gegangen ist.
- Eine neue Seite erreicht ein Ranking -Plateau für das Hauptschlüsselwort und kann nicht in die Top 3 Positionen einbrechen.
- Google indiziere keine neue Seite oder Seiten innerhalb desselben Seitentyps.
- Genaue doppelte Titel werden im Suchindex von Google angezeigt.
- Google meldet “Krabbelt, nicht indiziert” oder “entdeckt, nicht indiziert” für URLs, die keinen dünnen Inhalt oder technischen Problemen haben.
Da Google uns kein klares Signal für Kannibalisierung gibt, ist der beste Weg, die Ähnlichkeit zwischen zwei oder mehr Seiten zu messen, die Ähnlichkeit der Cosinus zwischen ihren tokenisierten Einbettungen (ich weiß, es ist ein Schluck).
Aber das ist es, was es bedeutet: Im Grunde genommen vergleichen Sie, wie ähnlich zwei Seiten sind, indem Sie ihren Text in Zahlen verwandeln und sehen, wie genau diese Zahlen in die gleiche Richtung zeigen.
Denken Sie darüber nach wie ein Schokoladenkeksrezept:
- Tokenisierung = Brechen Sie jedes Rezept (z. B. Seiteninhalt) in Zutaten auf: Mehl, Zucker, Schokoladenchips usw.
- Einbettungen = Umwandeln Sie jede Zutat in Zahlen, z. B. wie viel von jedem Zutaten verwendet wird und wie wichtig jeder für die Identität des Rezepts ist.
- Kosinusähnlichkeit = Vergleichen Sie die Rezepte mathematisch. Dies gibt Ihnen eine Zahl zwischen 0 und 1. Eine Punktzahl von 1 bedeutet, dass die Rezepte identisch sind, während 0 bedeutet, dass sie völlig unterschiedlich sind.
Befolgen Sie diesen Vorgang, um Ihre Website zu scannen und Kannibalisierungskandidaten zu finden:
- Kriechen: Kratzen Sie Ihre Website mit einem Tool wie Schreienfrosch (optional aus, die keine SEO -Zweck haben), um den URL- und Meta -Titel jeder Seite zu extrahieren
- Tokenisierung: Verwandeln Sie Wörter sowohl in der URL als auch in den Titel in Wörter, die leichter zu arbeiten sind. Das sind deine Token.
- Einbettungen: Verwandeln Sie die Token in Zahlen, um “Wortmathematik” zu machen.
- Ähnlichkeit: Berechnen Sie die Kosinus -Ähnlichkeit zwischen allen URLs und Meta -Titeln
Im Idealfall erhalten Sie eine Auswahlliste von URLs und Titeln, die zu ähnlich sind.
Im nächsten Schritt können Sie den folgenden Prozess anwenden, um sicherzustellen, dass sie sich wirklich gegenseitig ausschlachten:
- Inhalt extrahieren: Isolieren Sie klar den Hauptinhalt (Navigation, Fußzeile, Anzeigen usw. ausschließen). Vielleicht räumen Sie bestimmte Elemente auf, z. B. Stoppwörter.
- Chunking oder Tokenisierung: Aufteilen Sie den Inhalt entweder in aussagekräftige Brocken (Sätze oder Absätze) oder tokenisieren direkt. Ich bevorzuge Letzteres.
- Einbettungen: Einbetten Sie die Token ein.
- Entitäten: Extrahieren Sie benannte Entitäten aus den Token und wiegen sie in Einbettungen höher. Im Wesentlichen überprüfen Sie, welche Einbettungen „bekannte Dinge“ sind, und geben ihnen mehr Macht in Ihrer Analyse.
- Aggregation von Einbettungen: Aggregierte Token/Chunk-Einbettungen mit einer gewichteten Mittelung (z. B. TF-IDF) oder aufmerksamkeitsgewichtigen Pooling.
- Kosinusähnlichkeit: Berechnen Sie die Kosinus -Ähnlichkeit zwischen den resultierenden Einbettungen.
Sie können mein App -Skript verwenden, wenn Sie es in Google Sheets ausprobieren möchten (aber ich habe gleich eine bessere Alternative für Sie).
Über die Ähnlichkeit der Kosinus: Es ist nicht perfekt, aber gut genug.
Ja, Sie können Modelle für bestimmte Themen einbetten.
Und ja, Sie können erweiterte Einbettungsmodelle wie Satztransformatoren oben verwenden, aber dieser vereinfachte Prozess ist normalerweise ausreichend. Es ist nicht erforderlich, ein Astrophysik -Projekt daraus zu machen.
Wie man Kannibalisierung repariert
Sobald Sie Kannibalisierung identifiziert haben, sollten Sie Maßnahmen ergreifen.
Vergessen Sie jedoch nicht, Ihren langfristigen Ansatz zur Erstellung und Governance von Inhalten anzupassen. Wenn Sie dies nicht tun, wird all diese Arbeiten, um Kannibalisierung zu finden und zu reparieren, ein Verschwendung sein.
Kurzfristig Lösen von Kannibalisierung
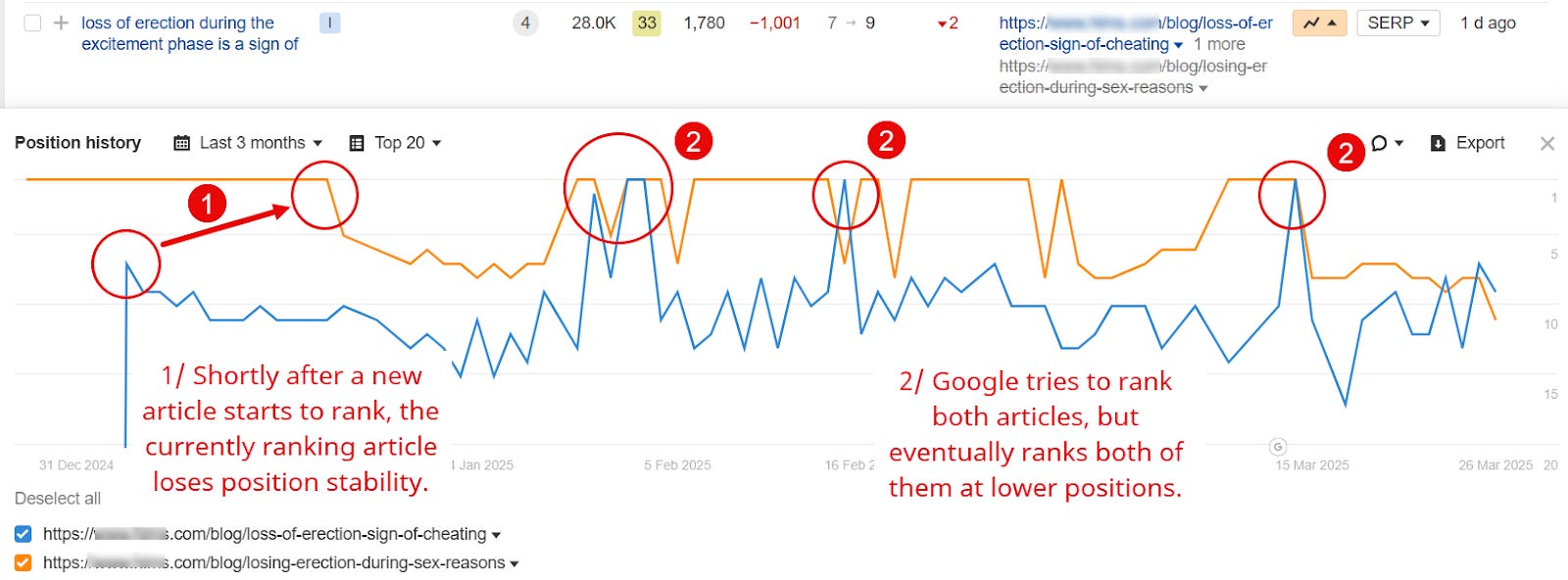
Die kurzfristigen Maßnahmen, die Sie ergreifen sollten, hängt von dem Grad der Kannibalisierung und wie schnell Sie handeln können.
„Abschluss“ bedeutet, wie ähnlich der Inhalt auf zwei oder mehr Seiten ist, ausgedrückt in Cosinus- oder Inhaltsähnlichkeit.
Obwohl keine genaue Wissenschaft, wird meiner Erfahrung nach eine Cosinus -Ähnlichkeit über 0,7 als „hoch“ eingestuft, während sie unter einem Wert von 0,5 „niedrig“ ist.
 4 Möglichkeiten zur Behebung der Kannibalisierung (Bildnachweis: Kevin Indig)
4 Möglichkeiten zur Behebung der Kannibalisierung (Bildnachweis: Kevin Indig)Was tun, wenn die Seiten ein hohes Maß an Ähnlichkeit haben:
- Kanonisch oder noIndex Die Seite, wenn die Kannibalisierung aufgrund technischer Probleme wie Parameter -URLs oder wenn die Kannibalisierungsseite für SEO, wie bezahlte Zielseiten, irrelevant ist. In diesem Fall kanonisieren Sie die Parameter-URL zur Nicht-Parameter-URL (oder noIndex auf der kostenpflichtigen Zielseite).
- Konsolidieren mit einer anderen Seite, wenn es sich nicht um ein technisches Problem handelt. Konsolidierung bedeutet, den Inhalt zu kombinieren und die URLs umzuleiten. Ich schlage vor, die ältere Seite und/oder die schlimmste Seite zu nehmen und zu einer neuen, besseren Seite umzuleiten. Übertragen Sie dann nützliche Inhalte in die neue Variante.
Was tun, wenn die Seiten einen geringen Grad an Ähnlichkeit haben:
- NoIndex oder entfernen (Statuscode: 410) Wenn Sie nicht über die Kapazität oder die Fähigkeit verfügen, Inhalte Änderungen vorzunehmen.
- Sich steigern Der Absichtsfokus des Inhalts, wenn Sie die Kapazität haben und die Überlappung nicht zu stark ist. Im Wesentlichen möchten Sie die Teile der Seiten unterscheiden, die zu ähnlich sind.
Langfristige Lösung von Kannibalisierung
Es ist wichtig, langfristige Maßnahmen zu ergreifen, um Ihren Strategie oder Ihren Produktionsprozess anzupassen, da die Kannibalisierung inhaltlich ein Symptom für ein größeres Problem ist, nicht für eine Grundursache.
(Es sei denn, wir sprechen von Google, das sein Verständnis der Absicht während eines Kernalgorithmus -Update verändert, und das hat nichts mit Ihnen oder Ihrem Team zu tun.)
Die kritischsten langfristigen Änderungen, die Sie vornehmen müssen, sind:
- Erstellen Sie eine Roadmap in Content: SEO-Integratoren sollten eine lebende Tabelle oder Datenbank mit allen SEO-relevanten URLs und ihren Hauptziel-Keywords und der Absicht zur Verringerung der redaktionellen Aufsicht beibehalten. Wer für die Roadmap inhaltlich verantwortlich ist, muss sicherstellen, dass sich keine Überschneidungen zwischen Artikeln und anderen Seitentypen überlappen. Autoren müssen eine klare Zielabsicht für neue und vorhandene Inhalte haben.
- Entwickeln Sie klare Standortarchitektur: Der Anhänger einer Inhaltskarte für SEO -Aggregatoren ist eine Site -Architekturkarte, die lediglich ein Überblick über verschiedene Seitentypen und die Absicht ist, die sie abzielen. Es ist wichtig, die Absicht zu unterstreichen, wenn Sie sie mit Beispiel -Schlüsselwörtern definieren, die Sie regelmäßig überprüfen („Ringen wir immer noch gut für diese Schlüsselwörter?“), Um sie mit dem Verständnis und Konkurrenten von Google zu entsprechen.
Die letzte Frage ist: “Woher weiß ich, wann die Kannibalisierung von Inhalten festgelegt ist?”
Die Antwort lautet, wenn die im vorherigen Kapitel genannten Symptome verschwinden:
- Indexierung von Problemen Lösung.
- URL Flackering verschwindet.
- Im Google -Suchindex werden keine doppelten Titel angezeigt.
- “Krabbelt, nicht indiziert” oder “entdeckt, nicht indiziert” Probleme verringern.
- Rankings stabilisieren sich und brechen durch ein Plateau (wenn die Seite keine anderen offensichtlichen Probleme hat).
Und nachdem ich jahrelang mit meinen Kunden unter diesem manuellen Rahmen zusammengearbeitet hatte, entschied ich, dass es Zeit ist, es zu automatisieren.
Einführung: Ein vollständig automatisierter Kannibalisierungsdetektor
Zusammen mit Nicole habe ich Airops verwendet, um einen vollständig automatisierten KI -Workflow zu bauen, der 37 Schritte durchläuft, um die Kannibalisierung innerhalb von Minuten zu erkennen.
Es führt eine gründliche Analyse der Kannibalisierung von Inhalten durch, indem die Keyword -Rankings, die Ähnlichkeit inhalts und historische Daten untersucht werden.
Im Folgenden werde ich die wichtigsten Schritte aufschlüsseln, die es in Ihrem Namen automatisiert:
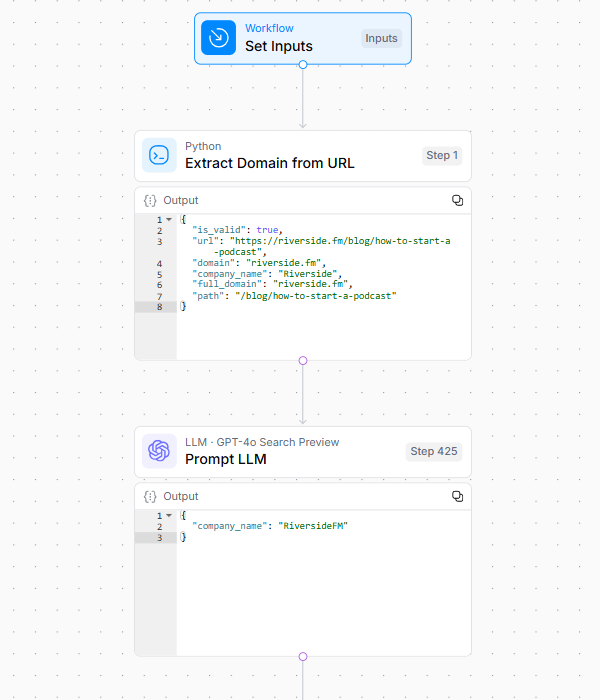
1. Erste URL -Verarbeitung
Der Workflow extrahiert und normalisiert die Domäne und den Markennamen der Eingabe -URL.
Dieser grundlegende Schritt legt die Identität der Zielwebsite fest und erstellt die Grundlinie für alle nachfolgenden Analysen.
 Bildnachweis: Kevin Indig
Bildnachweis: Kevin Indig2. Analyse der Zielinhaltsanalyse
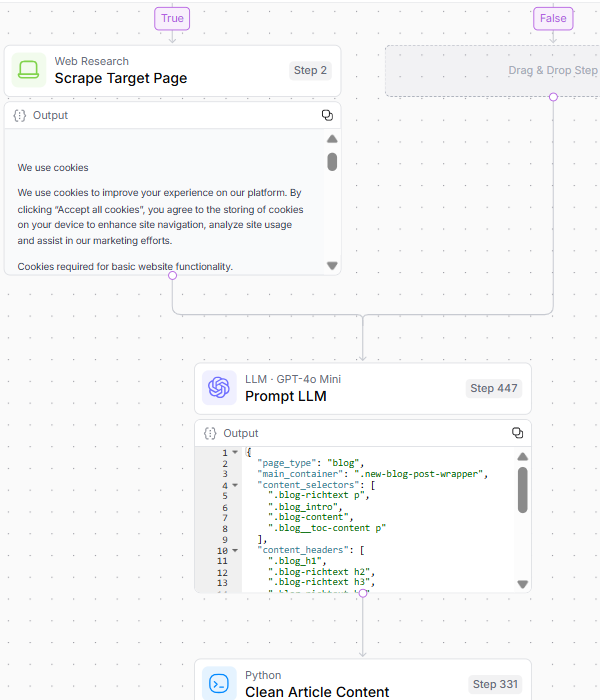
Um sicherzustellen, dass das System über Qualitätsquellenmaterial verfügt, um Wettbewerber zu analysieren und zu vergleichen, umfasst Schritt 2:
- Die Seite abkratzen.
- Validierung und Analyse der HTML -Struktur für den Hauptinhaltsextraktion.
- Reinigen Sie den Artikelinhalt und generieren Zieleinbettungen.
 Bildnachweis: Kevin Indig
Bildnachweis: Kevin Indig3. Keyword -Analyse
Schritt 3 enthüllt th Die Sichtbarkeit von URLs und potenzielle Schwachstellen der URL von:
- Analyse der Ranking -Keywords über SEMrush -Daten.
- Filterungsmarke im Vergleich zu Nicht-Marken-Begriffen.
- Identifizierung der SERP -Überlappung mit konkurrierenden URLs.
- Durchführung der historischen Ranglistenanalyse.
- Bestimmung des Seitenwerts basierend auf mehreren Metriken.
- Analyse von Positionsdifferentialveränderungen im Laufe der Zeit.
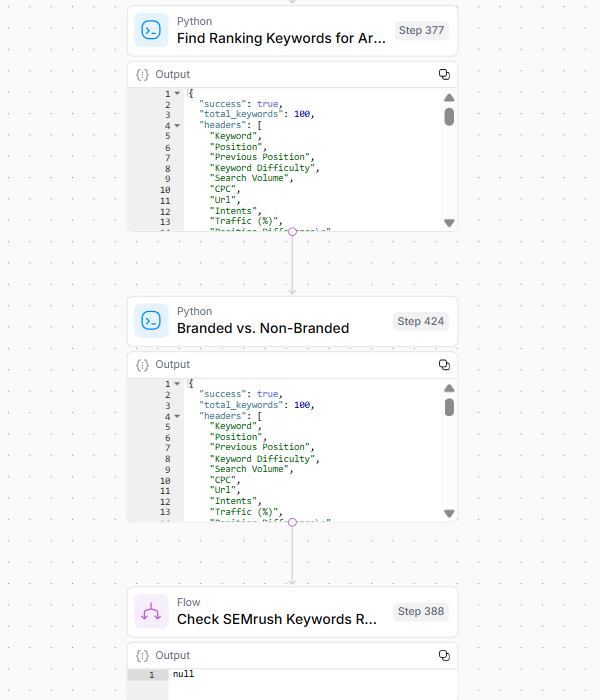 Bildnachweis: Kevin Indig
Bildnachweis: Kevin Indig4. konkurrierende Inhaltsanalyse (Iteration über konkurrierende URLs)
Schritt 4 sammelt einen zusätzlichen Kontext für Kannibalisierung, indem jede konkurrierende URL in den Suchergebnissen durch die vorherigen Schritte iterativ verarbeitet wird.
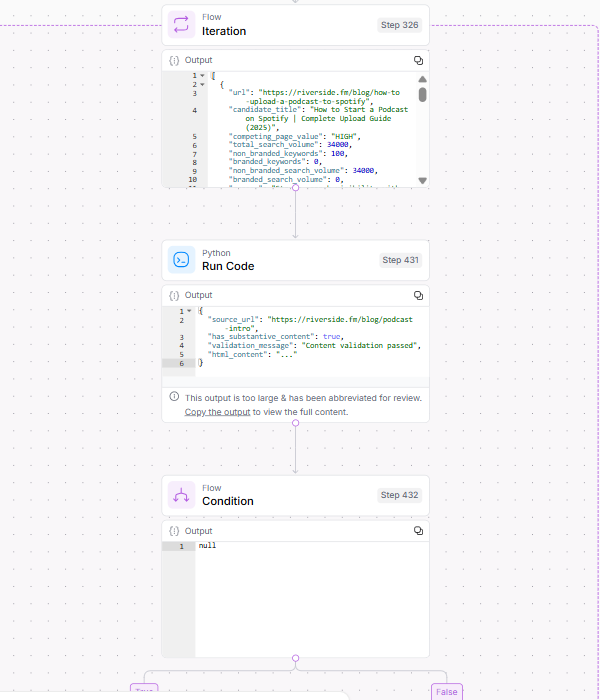 Bildnachweis: Kevin Indig
Bildnachweis: Kevin Indig5. Abschlussbericht Generierung
Im letzten Schritt reinigt der Workflow die Daten und generiert einen umsetzbaren Bericht.
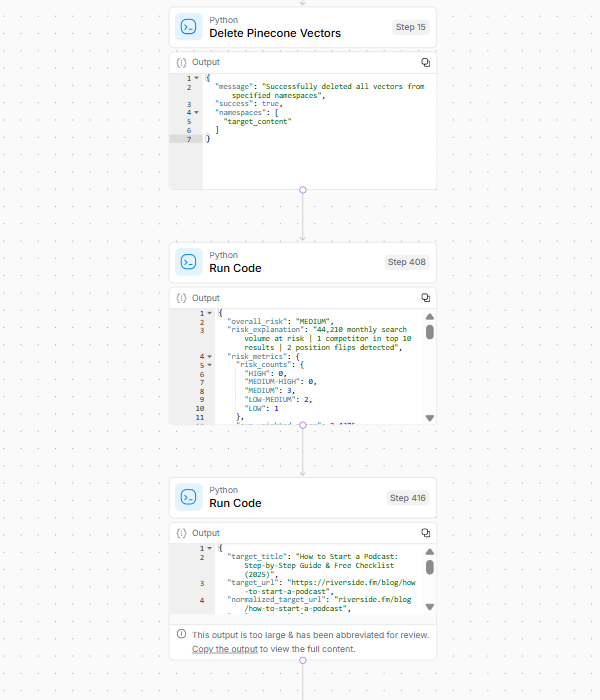 Bildnachweis: Kevin Indig
Bildnachweis: Kevin IndigVersuchen Sie den automatisierten Inhaltskaiserungsdetektor
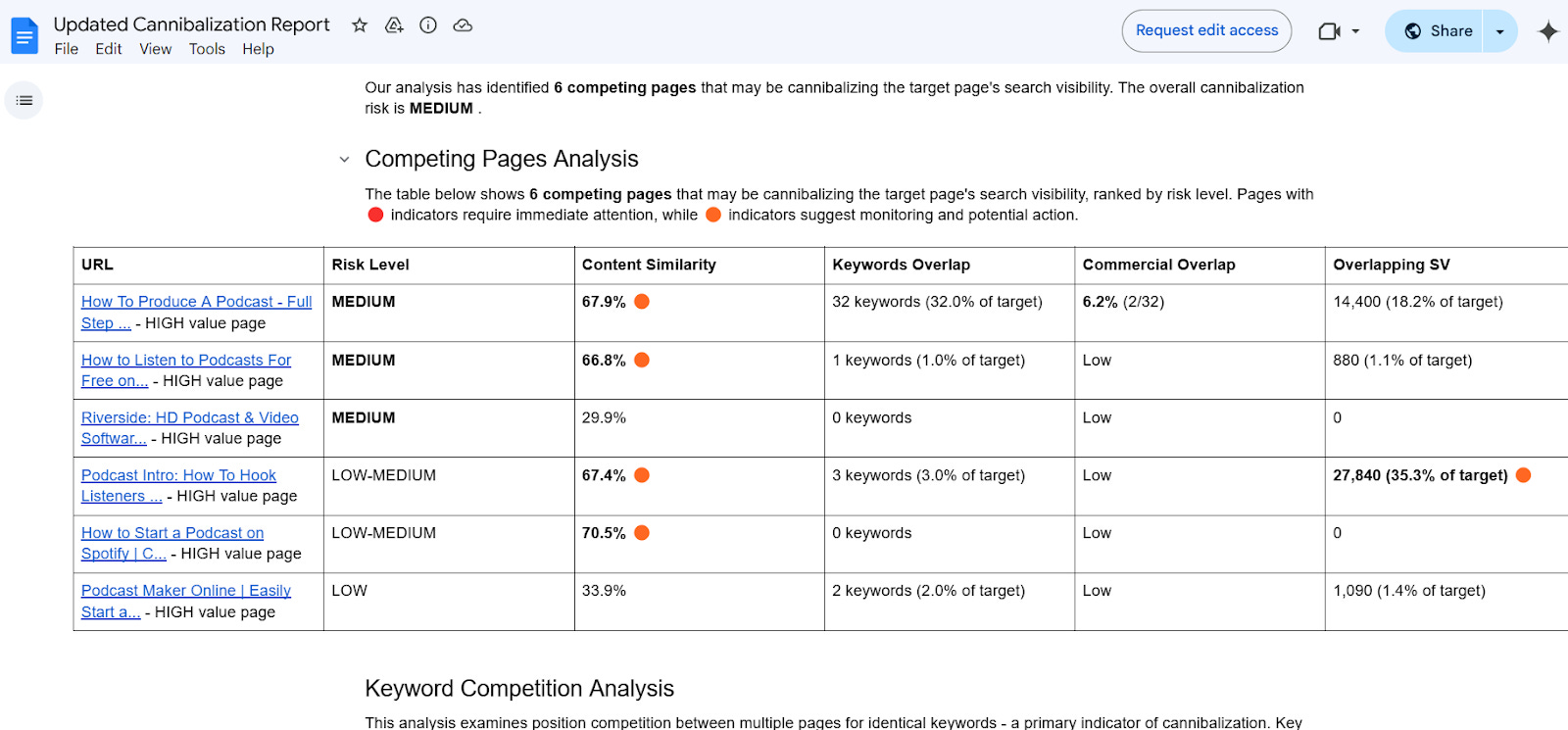 Bildnachweis: Kevin Indig
Bildnachweis: Kevin IndigProbieren Sie den Kannibalisierungsdetektor aus und sehen Sie sich einen Beispielbericht an.
Ein paar Dinge zu beachten:
- Dies ist eine frühe Version. Wir planen, es im Laufe der Zeit zu optimieren und zu verbessern.
- Der Workflow kann sich vorstellen Aufgrund einer hohen Anzahl von Anfragen. Wir begrenzen absichtlich die Nutzung, um nicht von API -Anrufen zu überwältigen (sie kosten Geld). Wir werden die Nutzung überwachen und möglicherweise die Grenze vorübergehend erhöhen. Wenn Ihr erster Versuch nicht erfolgreich ist, versuchen Sie es in wenigen Minuten erneut. Es könnte nur eine vorübergehende Nutzung sein.
- Ich bin ein Berater von Airops wurde aber weder bezahlt noch angeregt, um diesen Workflow aufzubauen.
Bitte hinterlassen Sie Ihr Feedback in den Kommentaren.
Wir würden gerne hören, wie wir den Kannibalisierungsdetektor auf die nächste Stufe bringen können!
Steigern Sie Ihre Fähigkeiten mit den wöchentlichen Experten -Erkenntnissen von Wachstum Memo. Kostenlos abonnieren!
Ausgewähltes Bild: Paulo Bobbita/Suchmaschinenjournal
![SEO-Auswirkungen des KI-Modus von Google | Studie zum Benutzerverhalten im KI-Modus [Teil 2]](https://behmaster.ir/wp-content/uploads/2025/10/637921-seo-auswirkungen-des-ki-modus-von-google-studie-zum-benutzerverhalten-im-ki-modus-teil-2-260x150.png)



