Einführung in Vektordatenbanken und wie man KI für SEO nutzt

Eine Vektordatenbank ist eine Datensammlung, bei der jedes Datenelement als (numerischer) Vektor gespeichert wird. Ein Vektor stellt ein Objekt oder eine Entität dar, beispielsweise ein Bild, eine Person, einen Ort usw. im abstrakten N-dimensionalen Raum.
Vektoren sind, wie im vorherigen Kapitel erläutert, von entscheidender Bedeutung für die Identifizierung der Beziehung zwischen Entitäten und können zum Ermitteln ihrer semantischen Ähnlichkeit verwendet werden. Dies kann auf verschiedene Arten für SEO angewendet werden – beispielsweise durch die Gruppierung ähnlicher Schlüsselwörter oder Inhalte (mithilfe von kNN).
In diesem Artikel lernen wir einige Möglichkeiten kennen, KI auf SEO anzuwenden, einschließlich der Suche nach semantisch ähnlichen Inhalten für die interne Verlinkung. Dies kann Ihnen helfen, Ihre Content-Strategie in einer Zeit zu verfeinern, in der Suchmaschinen zunehmend auf LLMs angewiesen sind.
Sie können auch einen früheren Artikel dieser Reihe darüber lesen, wie Sie mithilfe der Texteinbettungen von OpenAI die Kannibalisierung von Schlüsselwörtern erkennen können.
Lassen Sie uns hier eintauchen, um mit dem Aufbau der Basis unseres Tools zu beginnen.
Vektordatenbanken verstehen
Wenn Sie Tausende von Artikeln haben und die größte semantische Ähnlichkeit für Ihre Zielabfrage finden möchten, können Sie nicht im Handumdrehen Vektoreinbettungen für alle zum Vergleich erstellen, da dies äußerst ineffizient ist.
Dazu müssten wir Vektoreinbettungen nur einmal generieren und sie in einer Datenbank speichern, die wir abfragen und den Artikel mit der größten Übereinstimmung finden können.
Und genau das tun Vektordatenbanken: Sie sind spezielle Datenbanktypen, die Einbettungen (Vektoren) speichern.
Wenn Sie die Datenbank abfragen, führen sie im Gegensatz zu herkömmlichen Datenbanken einen Kosinus-Ähnlichkeitsabgleich durch und geben Vektoren (in diesem Fall Artikel) zurück, die einem anderen abgefragten Vektor (in diesem Fall einer Schlüsselwortphrase) am nächsten liegen.
So sieht es aus:
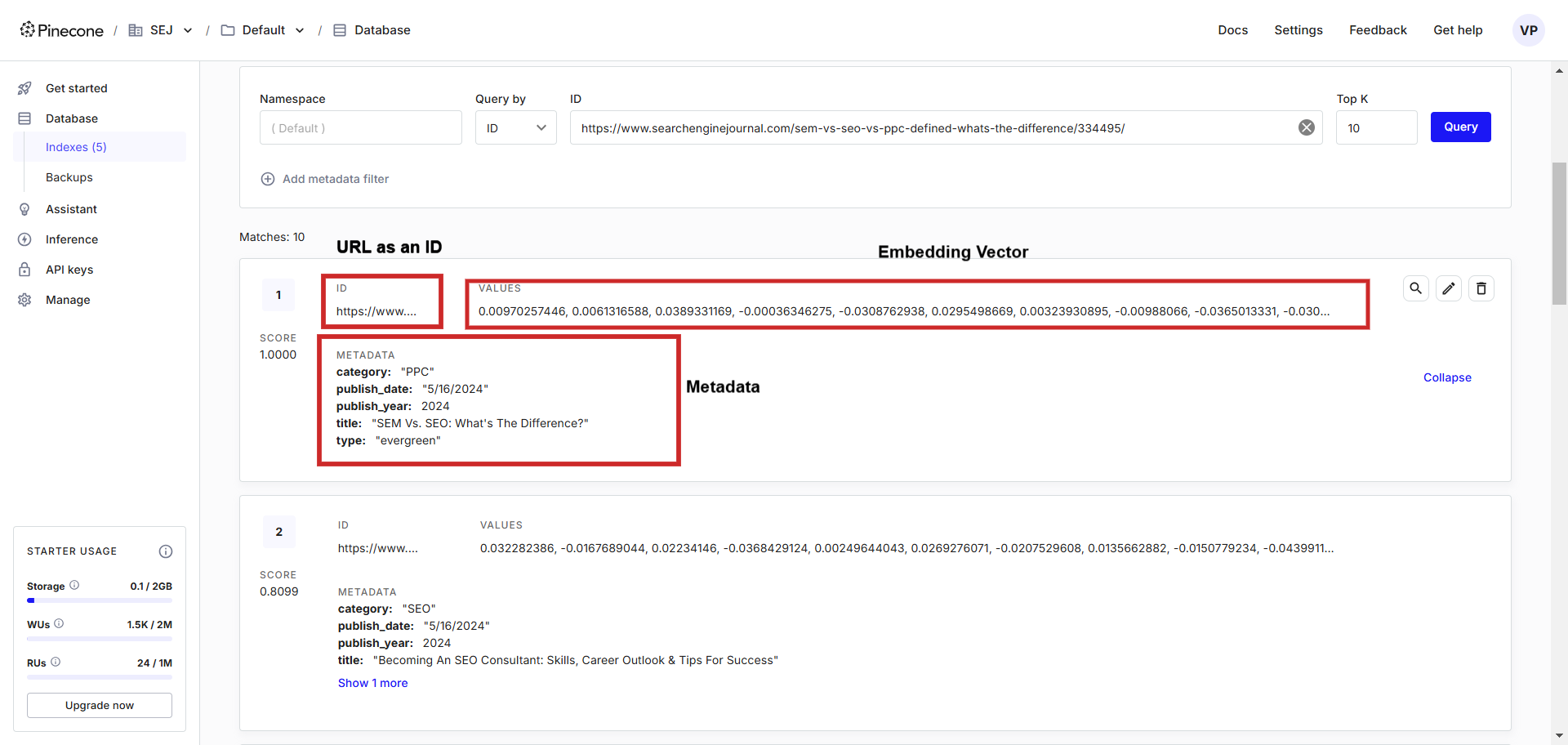 Beispiel für die Texteinbettung eines Datensatzes in der Vektordatenbank.
Beispiel für die Texteinbettung eines Datensatzes in der Vektordatenbank.In der Vektordatenbank sehen Sie neben gespeicherten Metadaten auch Vektoren, die wir einfach mit einer Programmiersprache unserer Wahl abfragen können.
In diesem Artikel verwenden wir Pinecone aufgrund seiner einfachen Verständlichkeit und Benutzerfreundlichkeit, es gibt jedoch auch andere Anbieter wie Chroma, BigQuery oder Qdrant, die Sie vielleicht ausprobieren möchten.
Lass uns eintauchen.
1. Erstellen Sie eine Vektordatenbank
Registrieren Sie zunächst ein Konto bei Pinecone und erstellen Sie einen Index mit der Konfiguration „text-embedding-ada-002“ mit „Kosinus“ als Metrik zur Messung der Vektorentfernung. Sie können dem Index einen beliebigen Namen geben, wir benennen ihnarticle-index-all-ada‘.
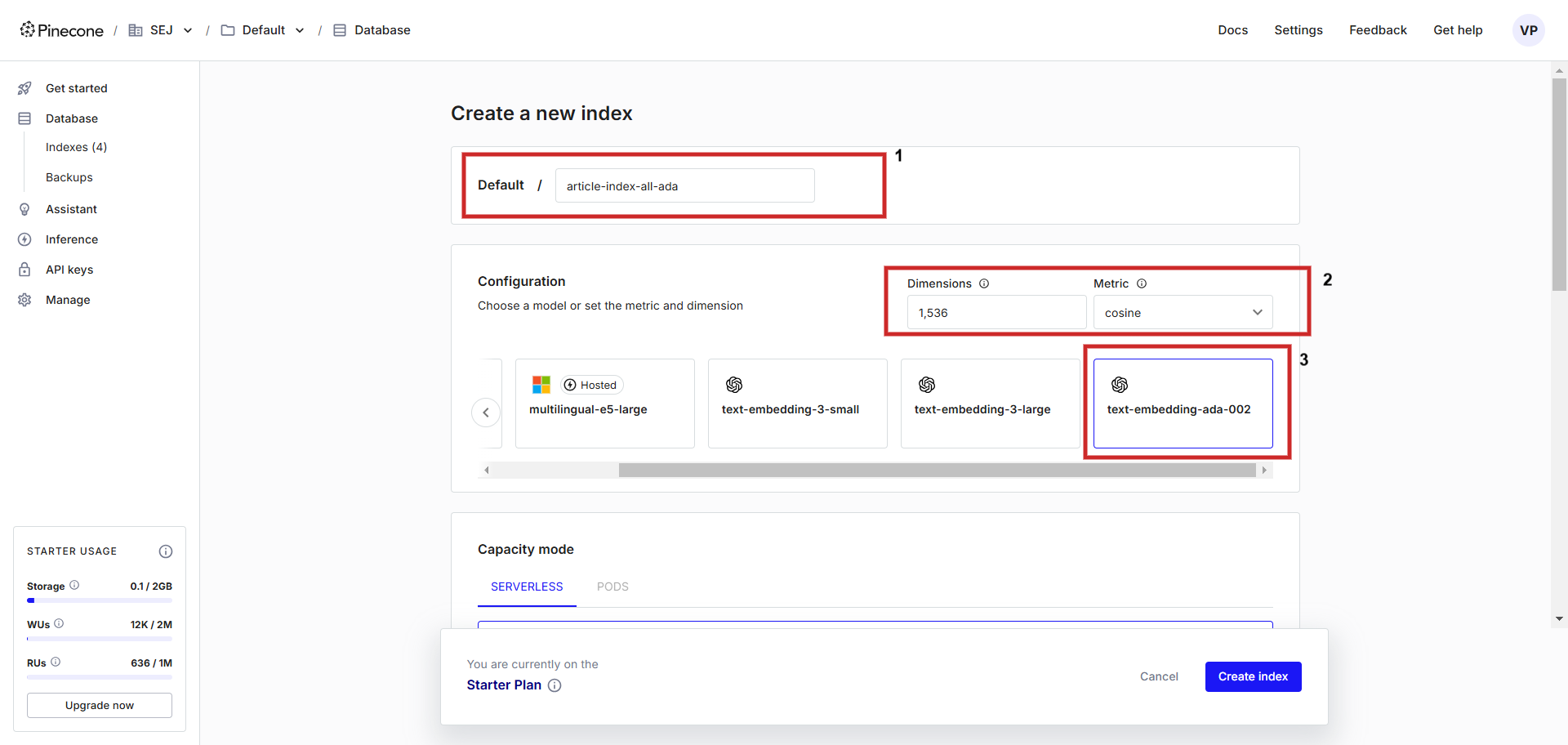 Erstellen einer Vektordatenbank.
Erstellen einer Vektordatenbank.Diese Hilfs-Benutzeroberfläche dient nur zur Unterstützung bei der Einrichtung. Wenn Sie die Vektoreinbettung von Vertex AI speichern möchten, müssen Sie „Dimensionen“ im Konfigurationsbildschirm manuell auf 768 setzen, um der Standarddimensionalität zu entsprechen, und Sie können Vertex AI-Textvektoren speichern (Sie Sie können einen Dimensionswert zwischen 1 und 768 einstellen, um Speicherplatz zu sparen.
In diesem Artikel erfahren Sie, wie Sie die Modelle „text-embedding-ada-002“ von OpenAi und „text-embedding-005“ von Google Vertex AI verwenden.
Nach der Erstellung benötigen wir einen API-Schlüssel, um über eine Host-URL der Vektordatenbank eine Verbindung zur Datenbank herstellen zu können.
Als nächstes müssen Sie Jupyter Notebook verwenden. Wenn Sie es nicht installiert haben, befolgen Sie diese Anleitung, um es zu installieren, und führen Sie anschließend diesen Befehl (unten) im Terminal Ihres PCs aus, um alle erforderlichen Pakete zu installieren.
pip install openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyUnd denken Sie daran, dass ChatGPT sehr nützlich ist, wenn beim Codieren Probleme auftreten!
2. Exportieren Sie Ihre Artikel aus Ihrem CMS
Als Nächstes müssen wir eine CSV-Exportdatei mit Artikeln aus Ihrem CMS vorbereiten. Wenn Sie WordPress verwenden, können Sie ein Plugin verwenden, um benutzerdefinierte Exporte durchzuführen.
Da unser oberstes Ziel darin besteht, ein internes Verknüpfungstool zu erstellen, müssen wir entscheiden, welche Daten als Metadaten in die Vektordatenbank übertragen werden sollen. Im Wesentlichen fungiert die auf Metadaten basierende Filterung als zusätzliche Ebene der Abrufanleitung und passt sie durch die Einbeziehung externen Wissens an das allgemeine RAG-Framework an, was zur Verbesserung der Abrufqualität beiträgt.
Wenn wir beispielsweise einen Artikel zum Thema „PPC“ bearbeiten und einen Link zum Begriff „Keyword-Recherche“ einfügen möchten, können wir in unserem Tool „Kategorie=PPC“ angeben. Dadurch kann das Tool nur Artikel innerhalb der Kategorie „PPC“ abfragen und so eine genaue und kontextrelevante Verlinkung gewährleisten. Alternativ können wir auch auf den Ausdruck „neuestes Google-Update“ verlinken und die Übereinstimmung mithilfe von „Typ“ nur auf Nachrichtenartikel beschränken ‘ und dieses Jahr veröffentlicht.
In unserem Fall exportieren wir:
- Titel.
Kategorie. - Typ.
- Veröffentlichungsdatum.
- Erscheinungsjahr.
- Permalink.
- Meta-Beschreibung.
- Inhalt.
Um die besten Ergebnisse zu erzielen, würden wir die Felder „Titel“ und „Meta-Beschreibung“ verketten, da sie die beste Darstellung des Artikels darstellen, die wir vektorisieren können, und sich ideal für Einbettungs- und interne Verlinkungszwecke eignen.
Die Verwendung des gesamten Artikelinhalts für Einbettungen kann die Präzision verringern und die Relevanz der Vektoren verwässern.
Dies liegt daran, dass eine einzelne große Einbettung versucht, mehrere im Artikel behandelte Themen gleichzeitig darzustellen, was zu einer weniger fokussierten und relevanten Darstellung führt. Chunking-Strategien (Aufteilung des Artikels nach natürlichen Überschriften oder semantisch bedeutsamen Segmenten) müssen angewendet werden, diese stehen jedoch nicht im Mittelpunkt dieses Artikels.
Hier ist die Beispielexportdatei, die Sie herunterladen und für unser Codebeispiel unten verwenden können.
2. Einfügen der Texteinbettungen von OpenAi in die Vektordatenbank
Vorausgesetzt, Sie verfügen bereits über einen OpenAI-API-Schlüssel, generiert dieser Code Vektoreinbettungen aus dem Text und fügt sie in die Vektordatenbank in Pinecone ein.
import pandas as pdfrom openai import OpenAIfrom pinecone import Pineconefrom IPython.display import clear_output# Setup your OpenAI and Pinecone API keysopenai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI clientpinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')# Connect to an existing Pinecone indexindex_name = "article-index-all-ada"index = pinecone.Index(index_name)def generate_embeddings(text): """ Generates an embedding for the given text using OpenAI's API. Returns None if text is invalid or an error occurs. """ try: if not text or not isinstance(text, str): raise ValueError("Input text must be a non-empty string.") result = openai_client.embeddings.create( input=text, model="text-embedding-ada-002" ) clear_output(wait=True) # Clear output for a fresh display if hasattr(result, 'data') and len(result.data) > 0: print("API Response:", result) return result.data[0].embedding else: raise ValueError("Invalid response from the OpenAI API. No data returned.") except ValueError as ve: print(f"ValueError: {ve}") return None except Exception as e: print(f"An error occurred while generating embeddings: {e}") return None# Load your articles from a CSVdf = pd.read_csv('Sample Export File.csv')# Process each articlefor idx, row in df.iterrows(): try: clear_output(wait=True) content = row["Content"] vector = generate_embeddings(content) if vector is None: print(f"Skipping article ID {row['ID']} due to empty or invalid embedding.") continue index.upsert(vectors=[ ( row['Permalink'], # Unique ID vector, # The embedding { 'title': row['Title'], 'category': row['Category'], 'type': row['Type'], 'publish_date': row['Publish Date'], 'publish_year': row['Publish Year'] } ) ]) except Exception as e: clear_output(wait=True) print(f"Error processing article ID {row['ID']}: {str(e)}")print("Embeddings are successfully stored in the vector database.")Sie müssen eine Notebook-Datei erstellen, diese kopieren und dort einfügen und dann die CSV-Datei „Sample Export File.csv“ in denselben Ordner hochladen.
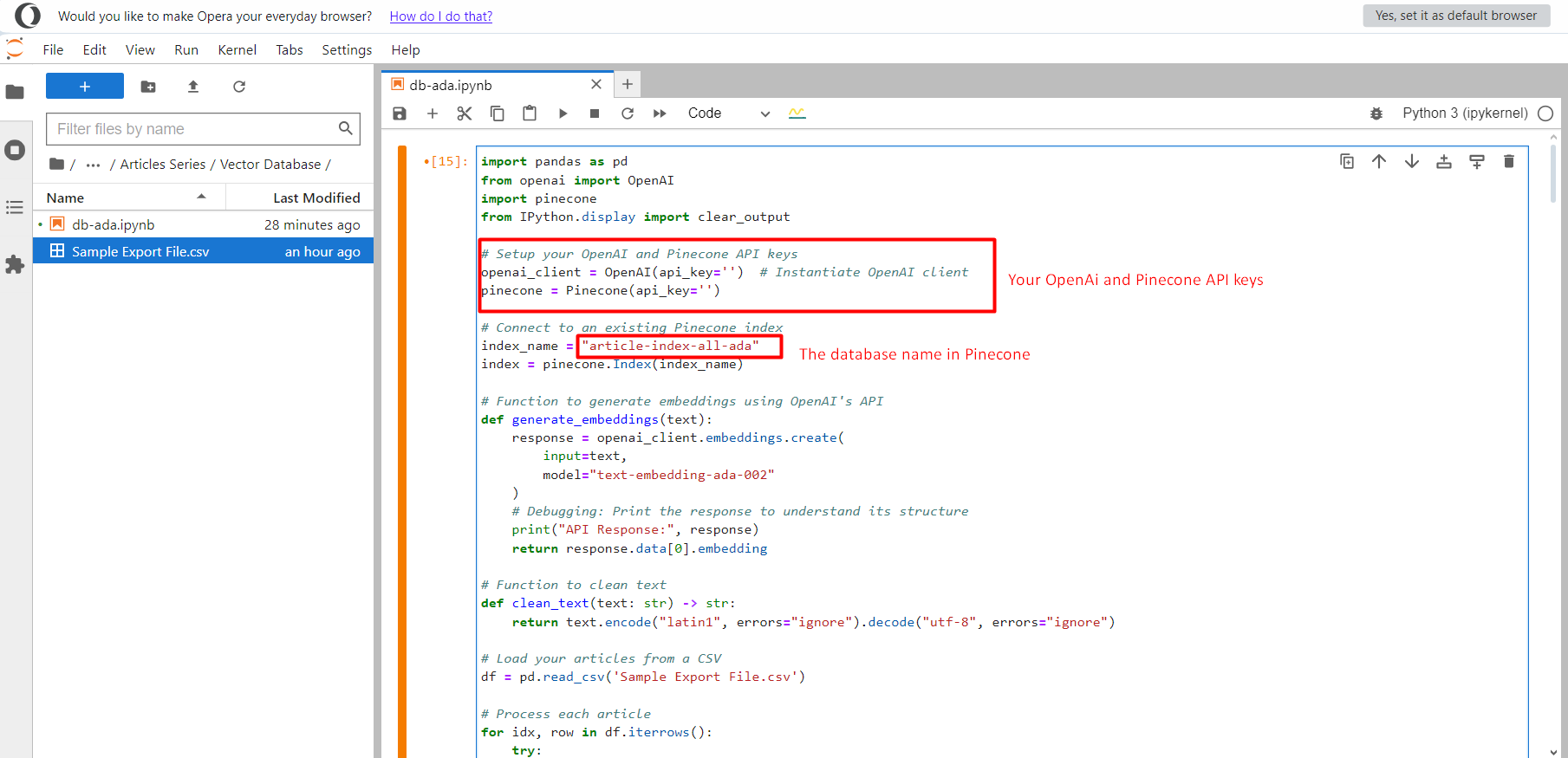 Jupyter-Projekt.
Jupyter-Projekt.Wenn Sie fertig sind, klicken Sie auf die Schaltfläche „Ausführen“ und alle Texteinbettungsvektoren werden in den Index verschoben article-index-all-ada die wir im ersten Schritt erstellt haben.
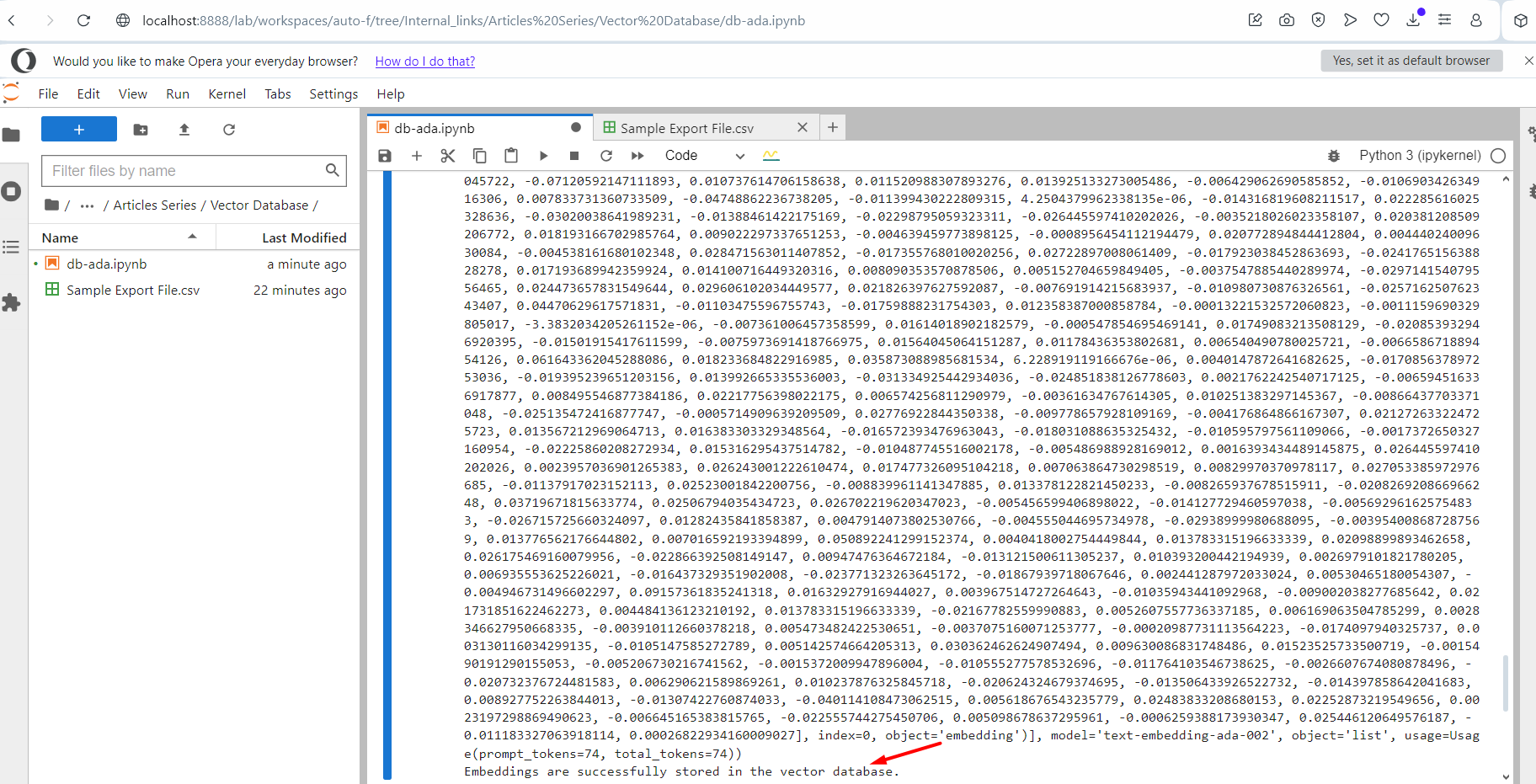 Ausführen des Skripts.
Ausführen des Skripts.Sie sehen einen Ausgabeprotokolltext der eingebetteten Vektoren. Sobald der Vorgang abgeschlossen ist, wird am Ende die Meldung angezeigt, dass der Vorgang erfolgreich abgeschlossen wurde. Sehen Sie sich jetzt Ihren Index im Pinecone an und Sie werden sehen, dass Ihre Unterlagen dort sind.
3. Einen Artikel finden, der zu einem Schlüsselwort passt
Okay, jetzt versuchen wir, einen passenden Artikel für das Schlüsselwort zu finden.
Erstellen Sie eine neue Notebook-Datei, kopieren Sie diesen Code und fügen Sie ihn ein.
from openai import OpenAIfrom pinecone import Pineconefrom IPython.display import clear_outputfrom tabulate import tabulate # Import tabulate for table formatting# Setup your OpenAI and Pinecone API keysopenai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI clientpinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')# Connect to an existing Pinecone indexindex_name = "article-index-all-ada"index = pinecone.Index(index_name)# Function to generate embeddings using OpenAI's APIdef generate_embeddings(text): """ Generates an embedding for a given text using OpenAI's API. """ try: if not text or not isinstance(text, str): raise ValueError("Input text must be a non-empty string.") result = openai_client.embeddings.create( input=text, model="text-embedding-ada-002" ) # Debugging: Print the response to understand its structure clear_output(wait=True) #print("API Response:", result) if hasattr(result, 'data') and len(result.data) > 0: return result.data[0].embedding else: raise ValueError("Invalid response from the OpenAI API. No data returned.") except ValueError as ve: print(f"ValueError: {ve}") return None except Exception as e: print(f"An error occurred while generating embeddings: {e}") return None# Function to query the Pinecone index with keywords and metadatadef match_keywords_to_index(keywords): """ Matches a list of keywords to the closest article in the Pinecone index, filtering by metadata dynamically. """ results = [] for keyword_pair in keywords: try: clear_output(wait=True) # Extract the keyword and category from the sub-array keyword = keyword_pair[0] category = keyword_pair[1] # Generate embedding for the current keyword vector = generate_embeddings(keyword) if vector is None: print(f"Skipping keyword '{keyword}' due to embedding error.") continue # Query the Pinecone index for the closest vector with metadata filter query_results = index.query( vector=vector, # The embedding of the keyword top_k=1, # Retrieve only the closest match include_metadata=True, # Include metadata in the results filter={"category": category} # Filter results by metadata category dynamically ) # Store the closest match if query_results['matches']: closest_match = query_results['matches'][0] results.append({ 'Keyword': keyword, # The searched keyword 'Category': category, # The category used for filtering 'Match Score': f"{closest_match['score']:.2f}", # Similarity score (formatted to 2 decimal places) 'Title': closest_match['metadata'].get('title', 'N/A'), # Title of the article 'URL': closest_match['id'] # Using 'id' as the URL }) else: results.append({ 'Keyword': keyword, 'Category': category, 'Match Score': 'N/A', 'Title': 'No match found', 'URL': 'N/A' }) except Exception as e: clear_output(wait=True) print(f"Error processing keyword '{keyword}' with category '{category}': {e}") results.append({ 'Keyword': keyword, 'Category': category, 'Match Score': 'Error', 'Title': 'Error occurred', 'URL': 'N/A' }) return results# Example usage: Find matches for an array of keywords and categorieskeywords = [["SEO Tools", "SEO"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]] # Replace with your keywords and categoriesmatches = match_keywords_to_index(keywords)# Display the results in a tableprint(tabulate(matches, headers="keys", tablefmt="fancy_grid"))Wir versuchen, eine Übereinstimmung für diese Schlüsselwörter zu finden:
- SEO-Tools.
- TikTok.
- SEO-Berater.
Und das ist das Ergebnis, das wir nach der Ausführung des Codes erhalten:
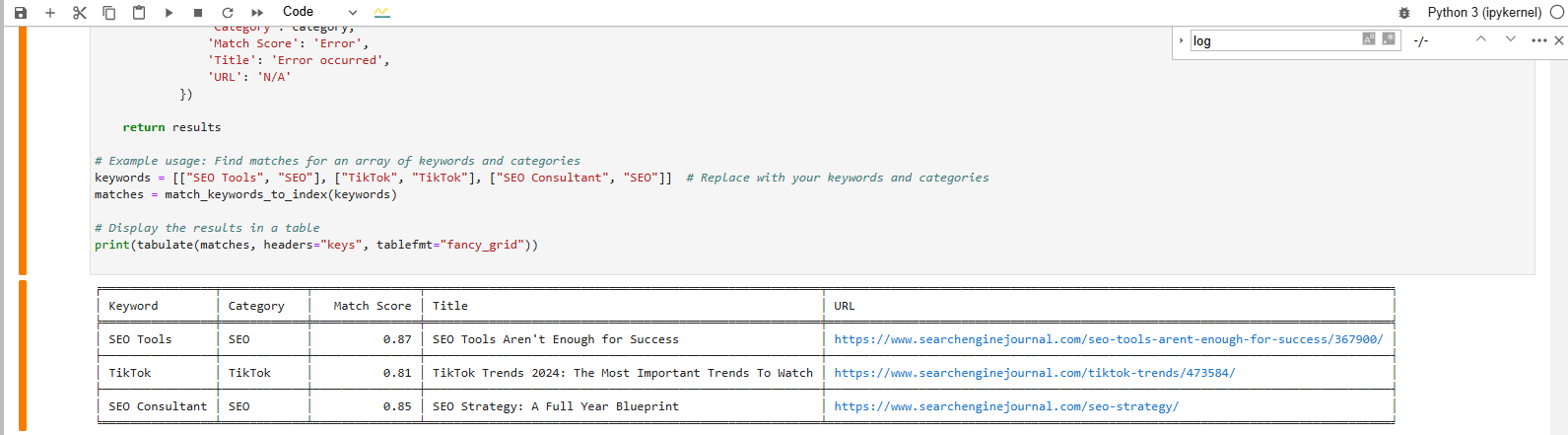 Finden Sie eine Übereinstimmung für die Schlüsselwortphrase aus der Vektordatenbank
Finden Sie eine Übereinstimmung für die Schlüsselwortphrase aus der VektordatenbankDie tabellenformatierte Ausgabe unten zeigt die Artikel, die unseren Schlüsselwörtern am ehesten entsprechen.
4. Einfügen von Google Vertex AI-Texteinbettungen in die Vektordatenbank
Machen wir jetzt dasselbe, aber mit Google Vertex AI.text-embedding-005‘Einbettung. Dieses Modell ist bemerkenswert, weil es von Google entwickelt wurde, Vertex AI Search unterstützt und speziell für die Bewältigung von Abruf- und Abfrageabgleichsaufgaben geschult ist, sodass es für unseren Anwendungsfall gut geeignet ist.
Sie können sogar ein internes Such-Widget erstellen und es Ihrer Website hinzufügen.
Melden Sie sich zunächst bei der Google Cloud Console an und erstellen Sie ein Projekt. Suchen Sie dann in der API-Bibliothek nach der Vertex AI API und aktivieren Sie sie.
 Screenshot von der Google Cloud Console, Dezember 2024
Screenshot von der Google Cloud Console, Dezember 2024Richten Sie Ihr Rechnungskonto ein, um Vertex AI nutzen zu können, da der Preis 0,0002 US-Dollar pro 1.000 Zeichen beträgt (und 300 US-Dollar Guthaben für neue Benutzer bietet).
Sobald Sie es festgelegt haben, müssen Sie zu API Services > Anmeldeinformationen navigieren, ein Dienstkonto erstellen, einen Schlüssel generieren und diese als JSON herunterladen.
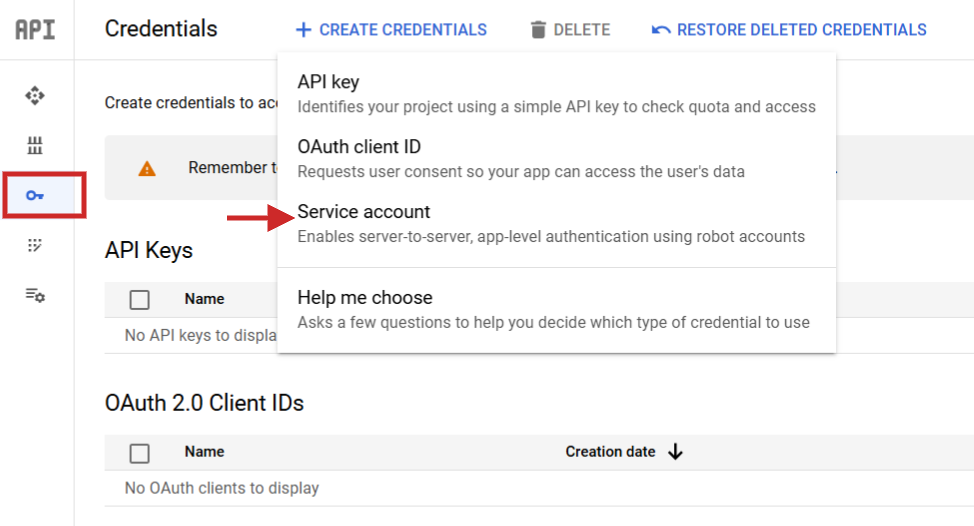
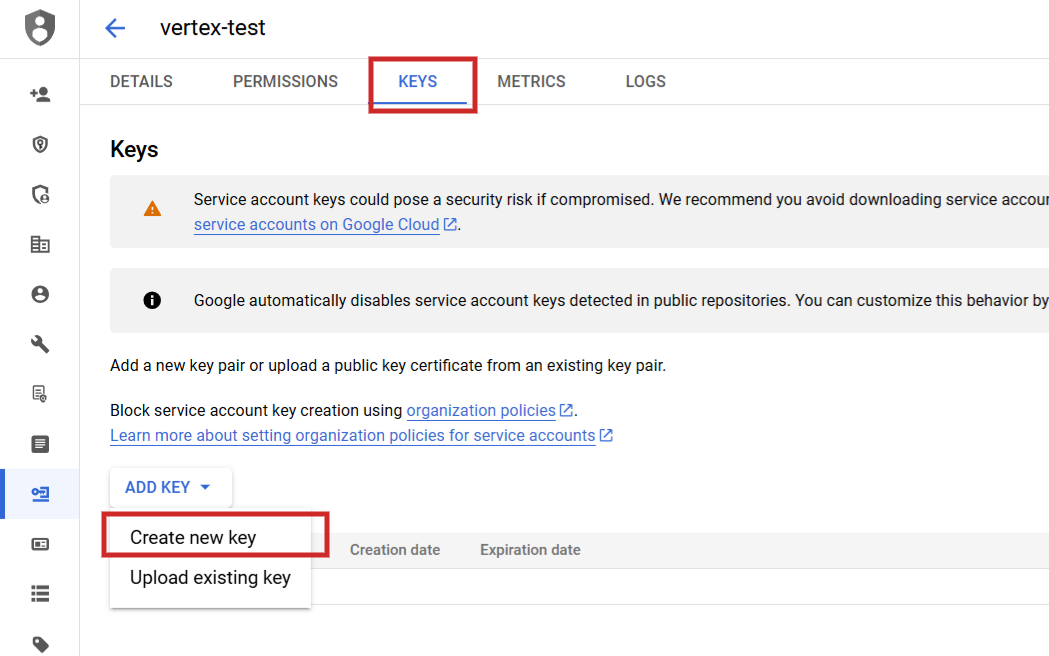
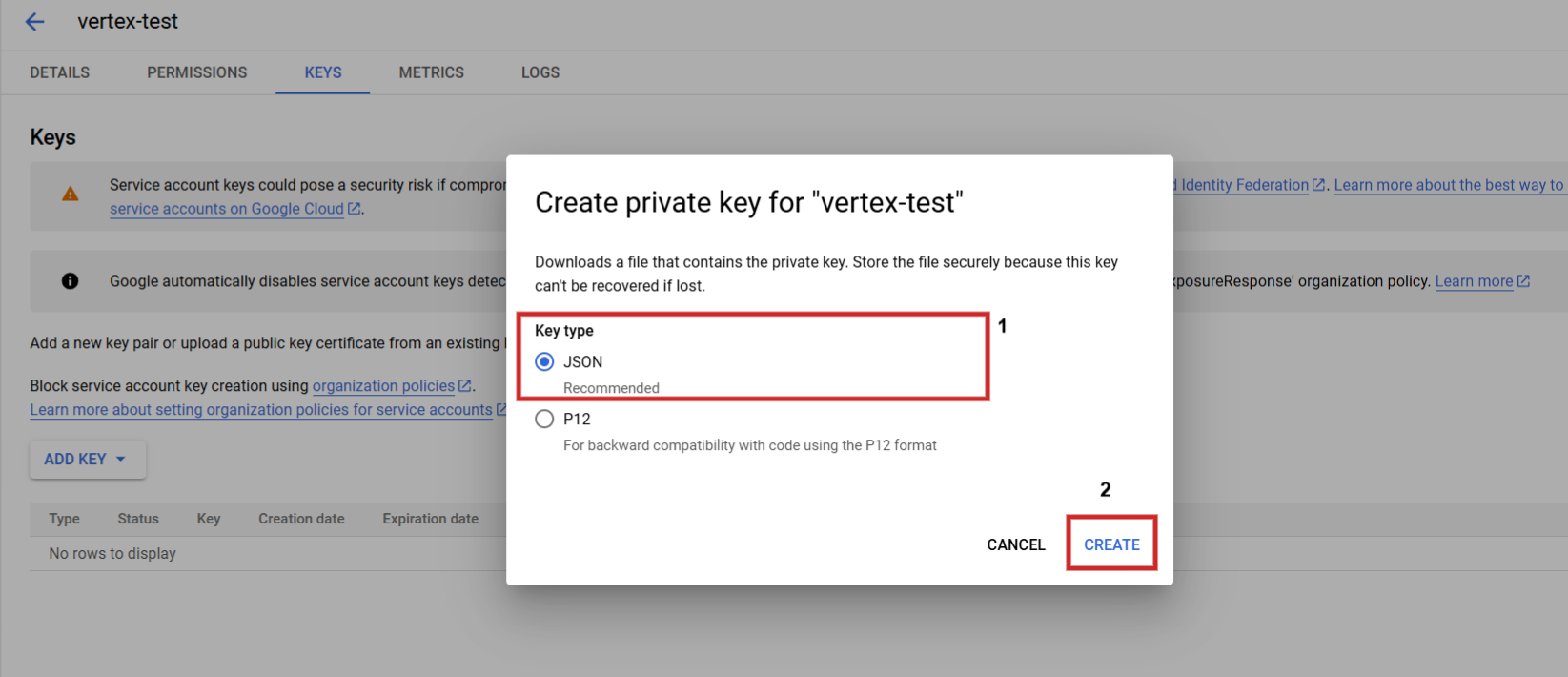
Benennen Sie die JSON-Datei in „config.json“ um und laden Sie sie (über das Pfeil-nach-oben-Symbol) in Ihren Jupyter Notebook-Projektordner hoch.
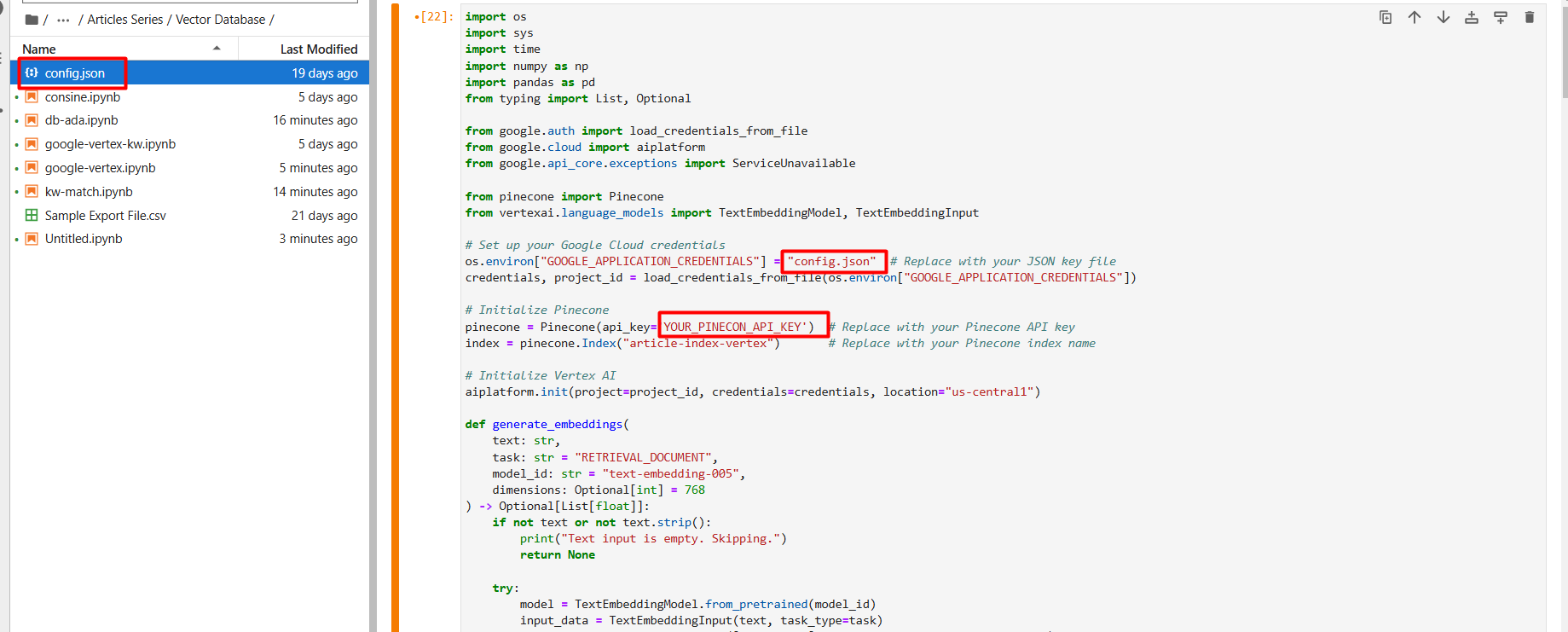 Screenshot von der Google Cloud Console, Dezember 2024
Screenshot von der Google Cloud Console, Dezember 2024Erstellen Sie im ersten Einrichtungsschritt eine neue Vektordatenbank mit dem Namen „article-index-vertex“, indem Sie die Dimension 768 manuell festlegen.
Nach der Erstellung können Sie dieses Skript ausführen, um mit Google Vertex AI mit der Generierung von Vektoreinbettungen aus derselben Beispieldatei zu beginnen text-embedding-005 Modell (Sie können text-multilingual-embedding-002 wählen, wenn Sie nicht-englischen Text haben).
import osimport sysimport timeimport numpy as npimport pandas as pdfrom typing import List, Optionalfrom google.auth import load_credentials_from_filefrom google.cloud import aiplatformfrom google.api_core.exceptions import ServiceUnavailablefrom pinecone import Pineconefrom vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput# Set up your Google Cloud credentialsos.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Replace with your JSON key filecredentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])# Initialize Pineconepinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Replace with your Pinecone API keyindex = pinecone.Index("article-index-vertex") # Replace with your Pinecone index name# Initialize Vertex AIaiplatform.init(project=project_id, credentials=credentials, location="us-central1")def generate_embeddings( text: str, task: str = "RETRIEVAL_DOCUMENT", model_id: str = "text-embedding-005", dimensions: Optional[int] = 768) -> Optional[List[float]]: if not text or not text.strip(): print("Text input is empty. Skipping.") return None try: model = TextEmbeddingModel.from_pretrained(model_id) input_data = TextEmbeddingInput(text, task_type=task) vectors = model.get_embeddings([input_data], output_dimensionality=dimensions) return vectors[0].values except ServiceUnavailable as e: print(f"Vertex AI service is unavailable: {e}") return None except Exception as e: print(f"Error generating embeddings: {e}") return None# Load data from CSVdata = pd.read_csv("Sample Export File.csv") # Replace with your CSV file pathfor idx, row in data.iterrows(): try: permalink = str(row["Permalink"]) content = row["Content"] embedding = generate_embeddings(content) if not embedding: print(f"Skipping article ID {row['ID']} due to empty or failed embedding.") continue print(f"Embedding for {permalink}: {embedding[:5]}...") sys.stdout.flush() index.upsert(vectors=[ ( permalink, embedding, { 'category': row['Category'], 'title': row['Title'], 'publish_date': row['Publish Date'], 'type': row['Type'], 'publish_year': row['Publish Year'] } ) ]) time.sleep(1) # Optional: Sleep to avoid rate limits except Exception as e: print(f"Error processing article ID {row['ID']}: {e}")print("All embeddings are stored in the vector database.")Unten sehen Sie die Protokolle der erstellten Einbettungen.
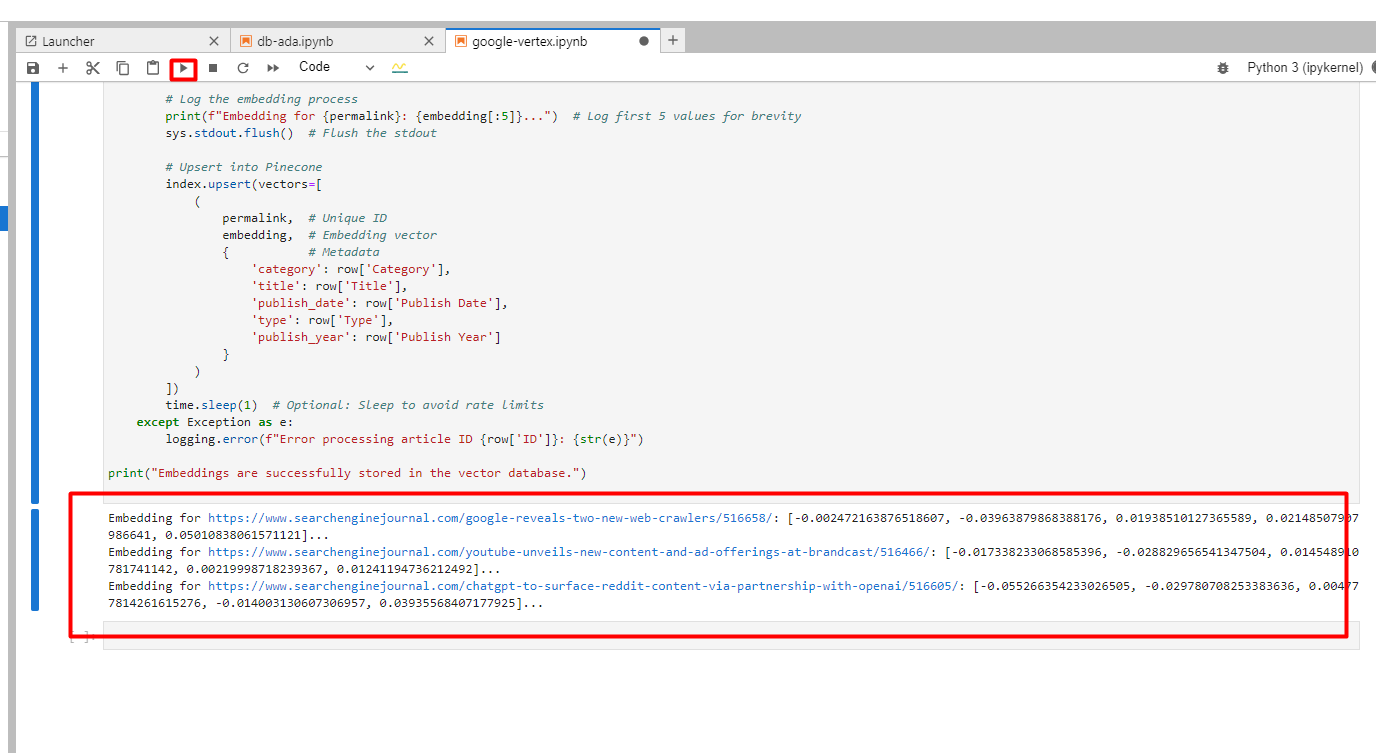 Screenshot von der Google Cloud Console, Dezember 2024
Screenshot von der Google Cloud Console, Dezember 20244. Finden eines Artikels, der zu einem Schlüsselwort passt, mithilfe von Google Vertex AI
Führen wir nun den gleichen Keyword-Abgleich mit Vertex AI durch. Es gibt eine kleine Nuance, da Sie „RETRIEVAL_QUERY“ vs. „RETRIEVAL_DOCUMENT“ als Argument verwenden müssen, wenn Sie Einbettungen von Schlüsselwörtern generieren, da wir versuchen, nach einem Artikel (auch Dokument) zu suchen, der am besten zu unserer Phrase passt.
Aufgabentypen sind einer der wichtigen Vorteile, die Vertex AI gegenüber den Modellen von OpenAI hat.
Es stellt sicher, dass die Einbettungen die Absicht der Schlüsselwörter erfassen, was für die interne Verlinkung wichtig ist, und verbessert die Relevanz und Genauigkeit der in Ihrer Vektordatenbank gefundenen Übereinstimmungen.
Verwenden Sie dieses Skript, um die Schlüsselwörter Vektoren zuzuordnen.
import osimport pandas as pdfrom google.cloud import aiplatformfrom google.auth import load_credentials_from_filefrom google.api_core.exceptions import ServiceUnavailablefrom vertexai.language_models import TextEmbeddingModelfrom pinecone import Pineconefrom tabulate import tabulate # For table formatting# Set up your Google Cloud credentialsos.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Replace with your JSON key filecredentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])# Initialize Pinecone clientpinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Add your Pinecone API keyindex_name = "article-index-vertex" # Replace with your Pinecone index nameindex = pinecone.Index(index_name)# Initialize Vertex AIaiplatform.init(project=project_id, credentials=credentials, location="us-central1")def generate_embeddings( text: str, model_id: str = "text-embedding-005") -> list: """ Generates embeddings for the input text using Google Vertex AI's embedding model. Returns None if text is empty or an error occurs. """ if not text or not text.strip(): print("Text input is empty. Skipping.") return None try: model = TextEmbeddingModel.from_pretrained(model_id) vector = model.get_embeddings([text]) # Removed 'task_type' and 'output_dimensionality' return vector[0].values except ServiceUnavailable as e: print(f"Vertex AI service is unavailable: {e}") return None except Exception as e: print(f"Error generating embeddings: {e}") return Nonedef match_keywords_to_index(keywords): """ Matches a list of keyword-category pairs to the closest articles in the Pinecone index, filtering by metadata if specified. """ results = [] for keyword_pair in keywords: keyword = keyword_pair[0] category = keyword_pair[1] try: keyword_vector = generate_embeddings(keyword) if not keyword_vector: print(f"No embedding generated for keyword '{keyword}' in category '{category}'.") results.append({ 'Keyword': keyword, 'Category': category, 'Match Score': 'Error/Empty', 'Title': 'No match', 'URL': 'N/A' }) continue query_results = index.query( vector=keyword_vector, top_k=1, include_metadata=True, filter={"category": category} ) if query_results['matches']: closest_match = query_results['matches'][0] results.append({ 'Keyword': keyword, 'Category': category, 'Match Score': f"{closest_match['score']:.2f}", 'Title': closest_match['metadata'].get('title', 'N/A'), 'URL': closest_match['id'] }) else: results.append({ 'Keyword': keyword, 'Category': category, 'Match Score': 'N/A', 'Title': 'No match found', 'URL': 'N/A' }) except Exception as e: print(f"Error processing keyword '{keyword}' with category '{category}': {e}") results.append({ 'Keyword': keyword, 'Category': category, 'Match Score': 'Error', 'Title': 'Error occurred', 'URL': 'N/A' }) return results# Example usage: keywords = [["SEO Tools", "Tools"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]]matches = match_keywords_to_index(keywords)# Display the results in a tableprint(tabulate(matches, headers="keys", tablefmt="fancy_grid"))Und Sie werden die generierten Ergebnisse sehen:
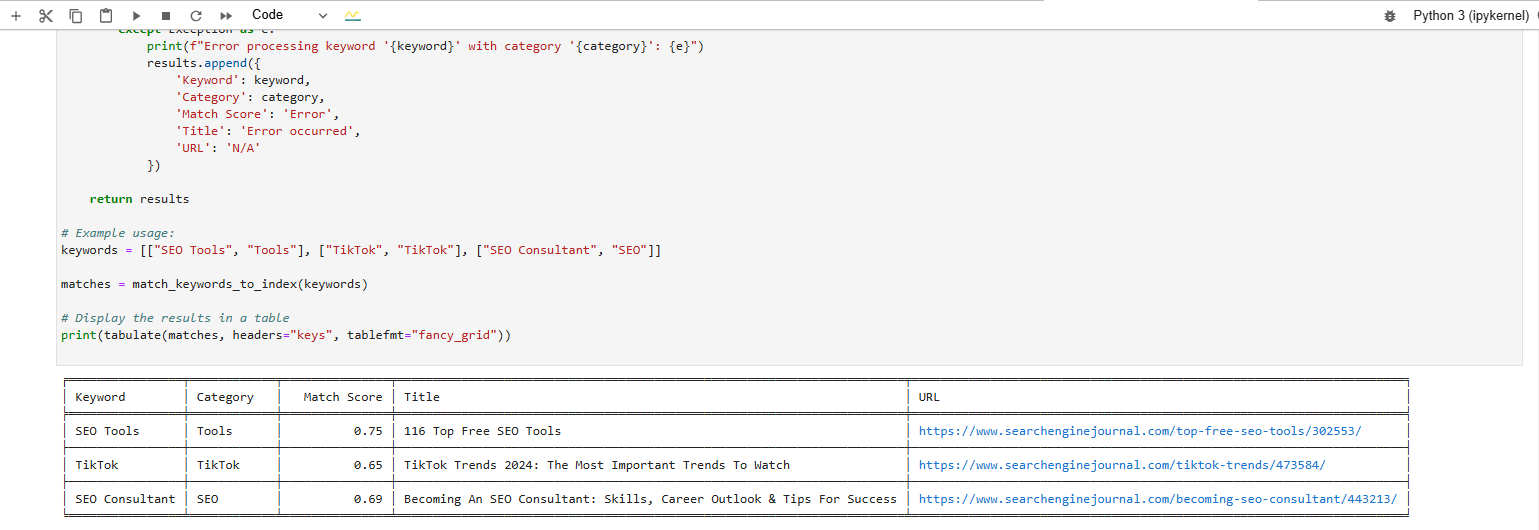 Keyword-Matche-Scores, erstellt durch das Vertex AI-Texteinbettungsmodell
Keyword-Matche-Scores, erstellt durch das Vertex AI-TexteinbettungsmodellVersuchen Sie, die Relevanz Ihres Artikelschreibens zu testen
Betrachten Sie dies als eine vereinfachte (allgemeine) Methode, um zu überprüfen, wie semantisch Ihr Text dem Schlüsselwort „head“ ähnelt. Erstellen Sie über Googles Vertex AI eine Vektoreinbettung Ihres Head-Keywords und des gesamten Artikelinhalts und berechnen Sie eine Kosinusähnlichkeit.
Wenn Ihr Text zu lang ist, müssen Sie möglicherweise die Implementierung von Chunking-Strategien in Betracht ziehen.
Ein Wert (Kosinusähnlichkeit) nahe bei 1,0 (z. B. 0,8 oder 0,7) bedeutet, dass Sie bei diesem Thema ziemlich nah dran sind. Wenn Ihre Punktzahl niedriger ist, stellen Sie möglicherweise fest, dass ein zu langes Intro mit viel Flaum zu einer Verwässerung der Relevanz führt und eine Reduzierung dazu beiträgt, sie zu erhöhen.
Denken Sie jedoch daran, dass alle vorgenommenen Änderungen auch aus redaktioneller und Benutzererfahrungssicht sinnvoll sein sollten.
Sie können sogar einen schnellen Vergleich durchführen, indem Sie hochrangige Inhalte eines Mitbewerbers einbetten und sehen, wie Sie abschneiden.
Auf diese Weise können Sie Ihre Inhalte genauer auf das Zielthema abstimmen, was zu einem besseren Ranking führen kann.
Es gibt bereits Tools, die solche Aufgaben erledigen, aber das Erlernen dieser Fähigkeiten bedeutet, dass Sie einen maßgeschneiderten Ansatz wählen können, der auf Ihre Bedürfnisse zugeschnitten ist – und das natürlich kostenlos.
Wenn Sie selbst experimentieren und diese Fähigkeiten erlernen, können Sie mit KI-SEO auf dem Laufenden bleiben und fundierte Entscheidungen treffen.
Als zusätzliche Lektüre empfehle ich Ihnen, in diese tollen Artikel einzutauchen:
- GraphRAG 2.0 verbessert KI-Suchergebnisse
- Einführung in SEOntology: Die Zukunft von SEO im Zeitalter der KI
- Die Leistungsfähigkeit von LLM und Knowledge Graph erschließen (Eine Einführung)
Weitere Ressourcen:
- KI hat die Funktionsweise der Suche verändert
- KI für SEO: Können Sie schneller und intelligenter arbeiten?
- Nutzung generativer KI-Tools für SEO
Ausgewähltes Bild: Aozorastock/Shutterstock





