Finden Sie Keyword-Kannibalisierung mithilfe der Texteinbettungen von OpenAI mit Beispielen

In dieser neuen Artikelserie geht es um die Zusammenarbeit mit LLMs, um Ihre SEO-Aufgaben zu skalieren. Wir hoffen, Ihnen dabei zu helfen, KI in SEO zu integrieren, damit Sie Ihre Fähigkeiten verbessern können.
Wir hoffen, Ihnen hat der vorherige Artikel gefallen und Sie verstehen, was Vektoren, Vektordistanz und Texteinbettungen sind.
Anschließend ist es an der Zeit, Ihre „KI-Wissensmuskeln“ spielen zu lassen, indem Sie lernen, wie Sie mithilfe von Texteinbettungen Keyword-Kannibalisierung erkennen.
Wir beginnen mit den Texteinbettungen von OpenAI und vergleichen sie.
| Modell | Dimensionalität | Preisgestaltung | Anmerkungen |
|---|---|---|---|
| Texteinbettung-ada-002 | 1536 | 0,10 $ pro 1 Mio. Token | Ideal für die meisten Anwendungsfälle. |
| Texteinbettung-3-klein | 1536 | 0,002 $ pro 1 Mio. Token | Schneller und billiger, aber weniger genau |
| Texteinbettung-3-groß | 3072 | 0,13 $ pro 1 Mio. Token | Genauer für komplexe Aufgaben mit langen Texten, langsamer |
(*Token können als Wörter betrachtet werden.)
Aber bevor wir beginnen, müssen Sie Python und Jupyter auf Ihrem Computer installieren.
Jupyter ist ein webbasiertes Tool für Fachleute und Forscher. Es ermöglicht Ihnen die Durchführung komplexer Datenanalysen und die Entwicklung von Modellen für maschinelles Lernen in jeder beliebigen Programmiersprache.
Keine Sorge – die Installation ist ganz einfach und dauert nicht lange. Und denken Sie daran: ChatGPT ist Ihr Freund, wenn es ums Programmieren geht.
Kurzgesagt:
- Laden Sie Python herunter und installieren Sie es.
- Öffnen Sie Ihre Windows-Befehlszeile oder Ihr Terminal auf dem Mac.
- Geben Sie diese Befehle ein
pip install jupyterlabUndpip install notebook - Führen Sie Jupiter mit diesem Befehl aus:
jupyter lab
Wir werden Jupyter verwenden, um mit Texteinbettungen zu experimentieren. Sie werden sehen, wie viel Spaß die Arbeit damit macht!
Aber bevor wir beginnen, müssen Sie sich für die API von OpenAI anmelden und die Abrechnung einrichten, indem Sie Ihr Guthaben eintragen.
 Öffnen Sie die AI API-Abrechnungseinstellungen
Öffnen Sie die AI API-AbrechnungseinstellungenSobald Sie das getan haben, richten Sie E-Mail-Benachrichtigungen ein, die Sie informieren, wenn Ihre Ausgaben einen bestimmten Betrag überschreiten. Nutzungsbeschränkungen.
Dann erhalten Sie API-Schlüssel unter Armaturenbrett > API-Schlüssel, die Sie privat halten und niemals öffentlich teilen sollten.
 OpenAI API-Schlüssel
OpenAI API-SchlüsselJetzt verfügen Sie über alle erforderlichen Tools, um mit Einbettungen zu spielen.
- Öffnen Sie das Eingabeterminal Ihres Computers und geben Sie ein
jupyter lab. - In Ihrem Browser sollte nun etwa das folgende Bild angezeigt werden.
- Klicke auf Python 3 unter Notizbuch.
 Jupyter-Labor
Jupyter-LaborIn das geöffnete Fenster schreiben Sie Ihren Code.
Lassen Sie uns als kleine Aufgabe ähnliche URLs aus einer CSV-Datei gruppieren. Die Beispiel-CSV-Datei hat zwei Spalten: URL und Titel. Die Aufgabe unseres Skripts besteht darin, URLs mit ähnlicher semantischer Bedeutung basierend auf dem Titel zu gruppieren, damit wir diese Seiten zu einer zusammenfassen und Probleme mit Keyword-Kannibalisierung beheben können.
Hier sind die Schritte, die Sie ausführen müssen:
Installieren Sie die erforderlichen Python-Bibliotheken mit den folgenden Befehlen im Terminal Ihres PCs (oder im Jupyter-Notebook).
pip install pandas openai scikit-learn numpy unidecodeDie Bibliothek „OpenAI“ ist für die Interaktion mit der OpenAI-API erforderlich, um Einbettungen zu erhalten, und „Pandas“ wird zur Datenmanipulation und Handhabung von CSV-Dateioperationen verwendet.
Die Bibliothek „scikit-learn“ ist für die Berechnung der Kosinusähnlichkeit erforderlich, und „numpy“ ist für numerische Operationen und die Handhabung von Arrays unverzichtbar. Schließlich wird Unidecode zum Bereinigen von Text verwendet.
Laden Sie dann das Beispielblatt als CSV herunter, benennen Sie die Datei in „pages.csv“ um und laden Sie sie in Ihren Jupyter-Ordner hoch, in dem sich Ihr Skript befindet.
Legen Sie Ihren OpenAI-API-Schlüssel auf den Schlüssel fest, den Sie im obigen Schritt erhalten haben, und kopieren Sie den folgenden Code in das Notebook.
Führen Sie den Code aus, indem Sie oben im Notizbuch auf das Wiedergabedreiecksymbol klicken.
import pandas as pdimport openaifrom sklearn.metrics.pairwise import cosine_similarityimport numpy as npimport csvfrom unidecode import unidecode# Function to clean textdef clean_text(text: str) -> str: # First, replace known problematic characters with their correct equivalents replacements = { '–': '–', # en dash '’': '’', # right single quotation mark '“': '“', # left double quotation mark 'â€': '”', # right double quotation mark '‘': '‘', # left single quotation mark 'â€': '—' # em dash } for old, new in replacements.items(): text = text.replace(old, new) # Then, use unidecode to transliterate any remaining problematic Unicode characters text = unidecode(text) return text# Load the CSV file with UTF-8 encoding from root folder of Jupiter project folderdf = pd.read_csv('pages.csv', encoding='utf-8')# Clean the 'Title' column to remove unwanted symbolsdf['Title'] = df['Title'].apply(clean_text)# Set your OpenAI API keyopenai.api_key = 'your-api-key-goes-here'# Function to get embeddingsdef get_embedding(text): response = openai.Embedding.create(input=[text], engine="text-embedding-ada-002") return response['data'][0]['embedding']# Generate embeddings for all titlesdf['embedding'] = df['Title'].apply(get_embedding)# Create a matrix of embeddingsembedding_matrix = np.vstack(df['embedding'].values)# Compute cosine similarity matrixsimilarity_matrix = cosine_similarity(embedding_matrix)# Define similarity thresholdsimilarity_threshold = 0.9 # since threshold is 0.1 for dissimilarity# Create a list to store groupsgroups = []# Keep track of visited indicesvisited = set()# Group similar titles based on the similarity matrixfor i in range(len(similarity_matrix)): if i not in visited: # Find all similar titles similar_indices = np.where(similarity_matrix[i] >= similarity_threshold)[0] # Log comparisons print(f"nChecking similarity for '{df.iloc[i]['Title']}' (Index {i}):") print("-" * 50) for j in range(len(similarity_matrix)): if i != j: # Ensure that a title is not compared with itself similarity_value = similarity_matrix[i, j] comparison_result = 'greater' if similarity_value >= similarity_threshold else 'less' print(f"Compared with '{df.iloc[j]['Title']}' (Index {j}): similarity = {similarity_value:.4f} ({comparison_result} than threshold)") # Add these indices to visited visited.update(similar_indices) # Add the group to the list group = df.iloc[similar_indices][['URL', 'Title']].to_dict('records') groups.append(group) print(f"nFormed Group {len(groups)}:") for item in group: print(f" - URL: {item['URL']}, Title: {item['Title']}")# Check if groups were createdif not groups: print("No groups were created.")# Define the output CSV fileoutput_file = 'grouped_pages.csv'# Write the results to the CSV file with UTF-8 encodingwith open(output_file, 'w', newline='', encoding='utf-8') as csvfile: fieldnames = ['Group', 'URL', 'Title'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for group_index, group in enumerate(groups, start=1): for page in group: cleaned_title = clean_text(page['Title']) # Ensure no unwanted symbols in the output writer.writerow({'Group': group_index, 'URL': page['URL'], 'Title': cleaned_title}) print(f"Writing Group {group_index}, URL: {page['URL']}, Title: {cleaned_title}")print(f"Output written to {output_file}")Dieser Code liest eine CSV-Datei „pages.csv“, die Titel und URLs enthält, die Sie einfach aus Ihrem CMS exportieren oder durch Crawlen einer Client-Website mit Screaming Frog erhalten können.
Anschließend bereinigt es die Titel von Nicht-UTF-Zeichen, generiert mithilfe der API von OpenAI Einbettungsvektoren für jeden Titel, berechnet die Ähnlichkeit zwischen den Titeln, gruppiert ähnliche Titel und schreibt die gruppierten Ergebnisse in eine neue CSV-Datei „grouped_pages.csv“.
Bei der Keyword-Kannibalisierungsaufgabe verwenden wir einen Ähnlichkeitsschwellenwert von 0,9. Das bedeutet, dass wir Artikel als unterschiedlich betrachten, wenn die Kosinusähnlichkeit unter 0,9 liegt. Um dies in einem vereinfachten zweidimensionalen Raum zu visualisieren, wird es als zwei Vektoren mit einem Winkel von ungefähr 25 Grad zwischen ihnen dargestellt.

In Ihrem Fall möchten Sie möglicherweise einen anderen Schwellenwert verwenden, z. B. 0,85 (ungefähr 31 Grad zwischen ihnen), und ihn auf einer Stichprobe Ihrer Daten ausführen, um die Ergebnisse und die Gesamtqualität der Übereinstimmungen zu bewerten. Wenn dies nicht zufriedenstellend ist, können Sie den Schwellenwert erhöhen, um ihn für eine bessere Genauigkeit strenger zu machen.
Sie können „matplotlib“ über das Terminal installieren.
pip install matplotlibUnd verwenden Sie den untenstehenden Python-Code in einem separaten Jupyter-Notebook, um Kosinus-Ähnlichkeiten im zweidimensionalen Raum selbst zu visualisieren. Probieren Sie es aus, es macht Spaß!
import matplotlib.pyplot as pltimport numpy as np# Define the angle for cosine similarity of 0.9. Change here to your desired value. theta = np.arccos(0.9)# Define the vectorsu = np.array([1, 0])v = np.array([np.cos(theta), np.sin(theta)])# Define the 45 degree rotation matrixrotation_matrix = np.array([ [np.cos(np.pi/4), -np.sin(np.pi/4)], [np.sin(np.pi/4), np.cos(np.pi/4)]])# Apply the rotation to both vectorsu_rotated = np.dot(rotation_matrix, u)v_rotated = np.dot(rotation_matrix, v)# Plotting the vectorsplt.figure()plt.quiver(0, 0, u_rotated[0], u_rotated[1], angles='xy', scale_units='xy', scale=1, color='r')plt.quiver(0, 0, v_rotated[0], v_rotated[1], angles='xy', scale_units='xy', scale=1, color='b')# Setting the plot limits to only positive rangesplt.xlim(0, 1.5)plt.ylim(0, 1.5)# Adding labels and gridplt.xlabel('X-axis')plt.ylabel('Y-axis')plt.grid(True)plt.title('Visualization of Vectors with Cosine Similarity of 0.9')# Show the plotplt.show()Normalerweise verwende ich 0,9 und höher, um Probleme mit der Keyword-Kannibalisierung zu identifizieren. Beim Umgang mit alten Artikelweiterleitungen müssen Sie den Wert jedoch möglicherweise auf 0,5 setzen, da alte Artikel möglicherweise keine nahezu identischen Artikel enthalten, die aktueller, aber teilweise ähnlich sind.
Außerdem kann es bei Weiterleitungen besser sein, zusätzlich zum Titel auch die Meta-Beschreibung mit dem Titel zu verknüpfen.
Es hängt also von der Aufgabe ab, die Sie ausführen. Wie Weiterleitungen implementiert werden, besprechen wir später in dieser Reihe in einem separaten Artikel.
Sehen wir uns nun die Ergebnisse mit den drei oben genannten Modellen an und schauen wir, wie sie in der Lage waren, aus unserer Datenstichprobe aus den Artikeln des Search Engine Journal ähnliche Artikel zu identifizieren.
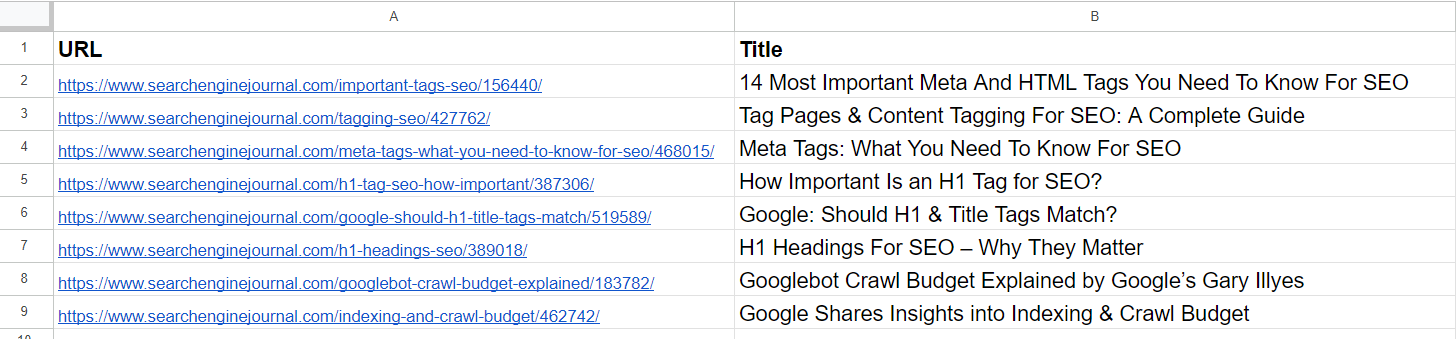 Datenbeispiel
DatenbeispielAus der Liste können wir bereits ersehen, dass der 2. und 4. Artikel dasselbe Thema behandeln, nämlich „Meta-Tags“. Die Artikel in der 5. und 7. Reihe sind ziemlich gleich – sie diskutieren die Bedeutung von H1-Tags in der SEO – und können zusammengeführt werden.
Der Artikel in der 3. Reihe hat keinerlei Ähnlichkeiten mit den Artikeln in der Liste, enthält aber gemeinsame Wörter wie „Tag“ oder „SEO“.
Der Artikel in der 6. Zeile handelt wieder von H1, aber nicht genau dasselbe wie die Bedeutung von H1 für SEO. Stattdessen stellt er die Meinung von Google dar, ob sie übereinstimmen sollten.
Die Artikel in der 8. und 9. Reihe sind recht ähnlich, aber dennoch unterschiedlich; sie können kombiniert werden.
Texteinbettung-ada-002
Durch die Verwendung von „text-embedding-ada-002“ haben wir den 2. und 4. Artikel mit einer Kosinus-Ähnlichkeit von 0,92 und den 5. und 7. Artikel mit einer Ähnlichkeit von 0,91 gefunden.
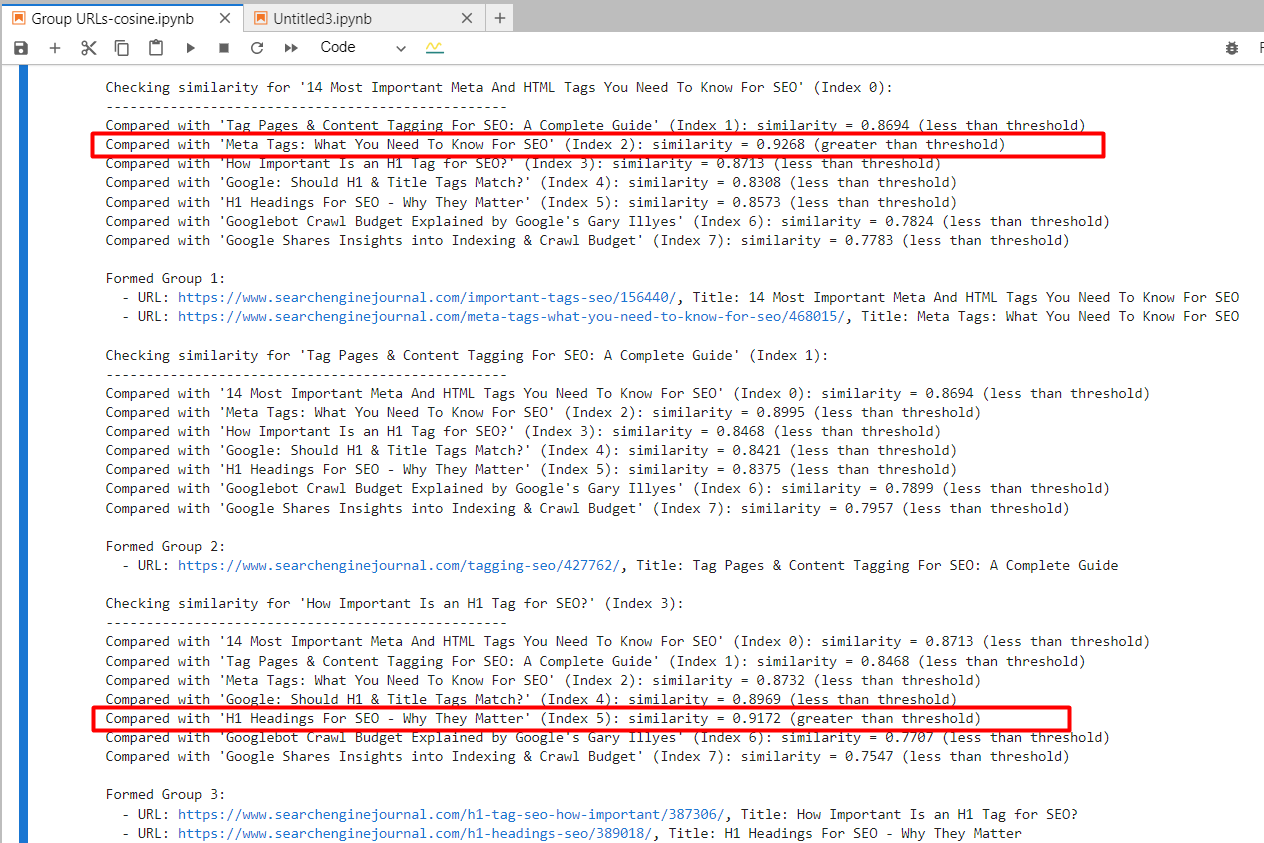 Screenshot aus dem Jupyter-Protokoll, der Kosinusähnlichkeiten zeigt
Screenshot aus dem Jupyter-Protokoll, der Kosinusähnlichkeiten zeigtUnd es generierte eine Ausgabe mit gruppierten URLs, indem für ähnliche Artikel die gleiche Gruppennummer verwendet wurde. (Farben werden zu Visualisierungszwecken manuell angewendet).
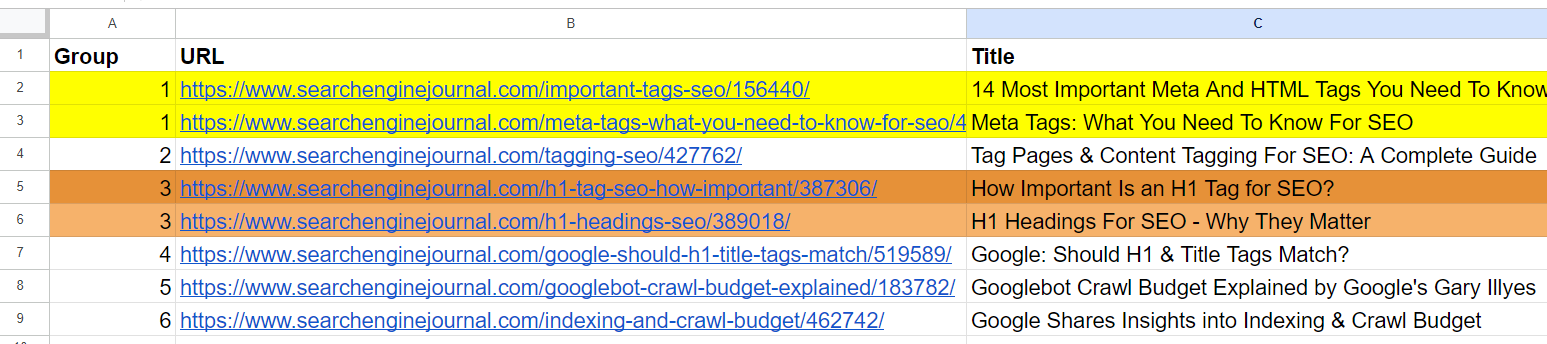 Ausgabeblatt mit gruppierten URLs
Ausgabeblatt mit gruppierten URLsFür den 2. und 3. Artikel, die die gemeinsamen Wörter „Tag“ und „SEO“ enthalten, aber nichts miteinander zu tun haben, betrug die Kosinus-Ähnlichkeit 0,86. Dies zeigt, warum ein hoher Ähnlichkeitsschwellenwert von 0,9 oder höher erforderlich ist. Wenn wir ihn auf 0,85 setzen würden, wäre er voller falscher Positivergebnisse und könnte darauf hindeuten, dass nicht miteinander in Zusammenhang stehende Artikel zusammengeführt werden sollten.
Texteinbettung-3-klein
Bei Verwendung von „text-embedding-3-small“ wurden überraschenderweise keine Übereinstimmungen mit unserem Ähnlichkeitsschwellenwert von 0,9 oder höher gefunden.
Für den 2. und 4. Artikel betrug die Kosinus-Ähnlichkeit 0,76 und für den 5. und 7. Artikel eine Ähnlichkeit von 0,77.
Um dieses Modell durch Experimente besser zu verstehen, habe ich der Stichprobe eine leicht modifizierte Version der 1. Zeile mit „15“ vs. „14“ hinzugefügt.
- „Die 14 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen“
- „Die 15 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen“
 Ein Beispiel, das die Ergebnisse von text-embedding-3-small zeigt
Ein Beispiel, das die Ergebnisse von text-embedding-3-small zeigtIm Gegenteil, „text-embedding-ada-002“ ergab eine Kosinus-Ähnlichkeit von 0,98 zwischen diesen Versionen.
| Titel 1 | Titel 2 | Kosinus-Ähnlichkeit |
| Die 14 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | 15 Die wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | 0,92 |
| Die 14 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | Meta-Tags: Das müssen Sie für SEO wissen | 0,76 |
Hier zeigt sich, dass sich dieses Modell für den Vergleich von Titeln nicht so gut eignet.
Texteinbettung-3-groß
Die Dimensionalität dieses Modells beträgt 3072, was doppelt so hoch ist wie die von „text-embedding-3-small“ und „text-embedding-ada-002“ mit 1536 Dimensionalität.
Da es über mehr Dimensionen als die anderen Modelle verfügt, können wir davon ausgehen, dass es die semantische Bedeutung mit höherer Präzision erfasst.
Für den 2. und 4. Artikel ergab sich jedoch eine Kosinus-Ähnlichkeit von 0,70 und für den 5. und 7. Artikel eine Ähnlichkeit von 0,75.
Ich habe es noch einmal mit leicht veränderten Versionen des ersten Artikels mit „15“ vs. „14“ und ohne „Am wichtigsten“ im Titel getestet.
- „Die 14 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen“
- „Die 15 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen“
- „14 Meta- und HTML-Tags, die Sie für SEO kennen müssen“
| Titel 1 | Titel 2 | Kosinus-Ähnlichkeit |
| Die 14 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | 15 Die wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | 0,95 |
| Die 14 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | 14 | 0,93 |
| Die 14 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | Meta-Tags: Das müssen Sie für SEO wissen | 0,70 |
| Die 15 wichtigsten Meta- und HTML-Tags, die Sie für SEO kennen müssen | 14 | 0,86 |
Wir können also sehen, dass „text-embedding-3-large“ im Vergleich zu „text-embedding-ada-002“ schlechter abschneidet, wenn wir Kosinus-Ähnlichkeiten zwischen Titeln berechnen.
Ich möchte darauf hinweisen, dass die Genauigkeit von „text-embedding-3-large“ mit der Länge des Textes zunimmt, „text-embedding-ada-002“ aber insgesamt immer noch eine bessere Leistung erbringt.
Ein anderer Ansatz könnte darin bestehen, Stoppwörter aus dem Text zu entfernen. Das Entfernen dieser Wörter kann manchmal dazu beitragen, die Einbettungen auf bedeutungsvollere Wörter zu konzentrieren, was möglicherweise die Genauigkeit von Aufgaben wie Ähnlichkeitsberechnungen verbessert.
Um festzustellen, ob das Entfernen von Stoppwörtern die Genauigkeit für Ihre spezielle Aufgabe und Ihren Datensatz verbessert, können Sie am besten beide Ansätze empirisch testen und die Ergebnisse vergleichen.
Abschluss
Mit diesen Beispielen haben Sie den Umgang mit den Einbettungsmodellen von OpenAI kennengelernt und können bereits vielfältige Aufgaben durchführen.
Um Ähnlichkeitsschwellenwerte festzulegen, müssen Sie mit Ihren eigenen Datensätzen experimentieren und herausfinden, welche Schwellenwerte für Ihre spezielle Aufgabe sinnvoll sind. Führen Sie dazu kleinere Datenstichproben aus und überprüfen Sie die Ausgabe durch einen Menschen.
Bitte beachten Sie, dass der Code in diesem Artikel nicht optimal für große Datensätze ist, da Sie bei jeder Änderung in Ihrem Datensatz Texteinbettungen von Artikeln erstellen müssen, um diese mit anderen Zeilen abzugleichen.
Um es effizient zu machen, müssen wir Vektordatenbanken verwenden und die Einbettungsinformationen dort speichern, sobald sie generiert wurden. Wir werden uns in Kürze mit der Verwendung von Vektordatenbanken befassen und das Codebeispiel hier ändern, um eine Vektordatenbank zu verwenden.
Mehr Ressourcen:
- Vermeidung von Keyword-Kannibalisierung zwischen Ihren bezahlten und organischen Suchkampagnen
- Wie verhindere ich Keyword-Kannibalisierung, wenn meine Produkte alle ähnlich sind?
- Nutzung generativer KI-Tools für SEO
Vorgestelltes Bild: BestForBest/Shutterstock





