Navigating the AI Landscape: An Introduction to Large Language Models (LLMs) and Essential Tools

If you sense a rumbling under foot, it’s not your imagination. The impact of Large Language Models (LLMs) and Artificial Intelligence (AI) is seismic, and practically every one of your working processes is incorporating this automated and ‘smart’ functionality. Using an LLM and AI on the whole can give you plenty of value, although it’s important to understand where you can use the ‘tech’ for best effect.
I’m going to walk through a plethora of topics relating to using Large Language Models over the course of a few posts. This first one should help clear up why I’m not calling this popular technology simply “AI”, and will introduce the most prominent tools for the job.
The Difference Between LLMs, AI, and Machine Learning
When I first began to use LLMs, the existing concepts of AI and machine learning seemed (in part) to explain what language modeling was already doing. Search engines, for example, have you type a request into the prompt, and get output related to that query—so what’s different here?
The answer is: application and context. Artificial Intelligence is the broad umbrella term for systems that achieve tasks where you’d typically require human intelligence. It’s everywhere: text generation, natural language processing, speech recognition, and much more.
Generative AI combines a foundational algorithm, a dataset, and the ability to generate new data from that existing set. Discriminative AI focuses on how each class of data differs from the other. For a real-world comparison, the DALL-E image creator is generative AI, whereas sentiment analysis from Google Cloud’s Natural Language API is discriminative.

Without getting into the nuts and bolts, Machine Learning (ML) is a way of teaching a machine to learn from its data without the need for programming. There are a number of approaches and models you can apply, and there’s plenty of crossover with generative and discriminative AI.
However, my focus is on where Large Language Models fit into the landscape, so let’s get into that aspect next.
What a Large Language Model Is
In short, Large Language Models are a combination of generative AI and ML technology that will only use and learn from the data it has access to.. As the name implies, you use them for Natural Language Processing (NLP) tasks such as text generation or analysis.
A typical LLM will have a number of components, and two are vital:
- Architecture. This combines multiple layers of ‘neural networking’, weighting towards different words and phrases, embedding layers to convert data into language, and much more.
- Training data. The main facet of this is a vast ‘corpus’ of data—code, books, documentation, websites, videos, and whatever else the developer includes.
There are also various inference systems, integration layers, and safety controls in place to shuttle and convert data between the user prompt and the LLM.
Generative Pre-Trained Transformers (GPTs): The Heart of an LLM
As a framework for the model’s neural network, the GPT is the LLM. Generative pre-training is a part of machine learning, and the transformer architecture simply optimizes this for NLP tasks. GPTs have the most capability, so that’s what the majority of developers use within its Large Language Models.
You can also get Small Language Models (SLMs), which have greater portability, more potential dedicated focuses on specific niches, and possibility greater security. However, the foundational elements are the same as LLMs—both the positives, and negatives.
How Large Language Models Fit Into Different Workflows
Language modeling is the hot new technology, so lots of other apps and services want to incorporate it into whatever systems and processes each one runs. Each service will hook into a dedicated API (usually ChatGPT’s solution), and build the functionality to work with its existing tools.
For example, Adobe has its “AI-powered” solutions, assistants, generators, and more across its whole product line:
This means you can jump into using LLMs within a familiar workflow. It’s the same for development tasks and coding. Lots of code editors—JetBrains’ products and Visual Studio Code being the most prominent—include AI integration.
For a typical business with an online presence and a team covering multiple roles, LLMs can assist across a number of areas:
- Content planning and creation. A common first task for many is to create content. This could be ideas, keyword research, or even full blog posts and other copy.
- Customer services. While an LLM could generate the FAQ and documentation pages your site needs for customers, you might also apply it elsewhere. For instance, you could generate basic responses to common chat questions, or even summarize multiple responses in a few bullet points.
- Marketing. At a basic level, LLMs are great at generating iterative variations. This would pair well with any ad copy you wish to create. You might also consider using Large Language Models to brainstorm ideas and angles for your next campaign.
It’s easy to see why Large Language Models are everywhere. Even so, I don’t believe LLMs should be a part of every step within a workflow. In fact, I see lots of use cases that misuse the technology.
The Limitations of What LLMs Can Achieve
Right now, LLMs are in a peak period of the ‘hype cycle’, similar to the ‘dot-com boom’ of the late 90s and early 2000s.
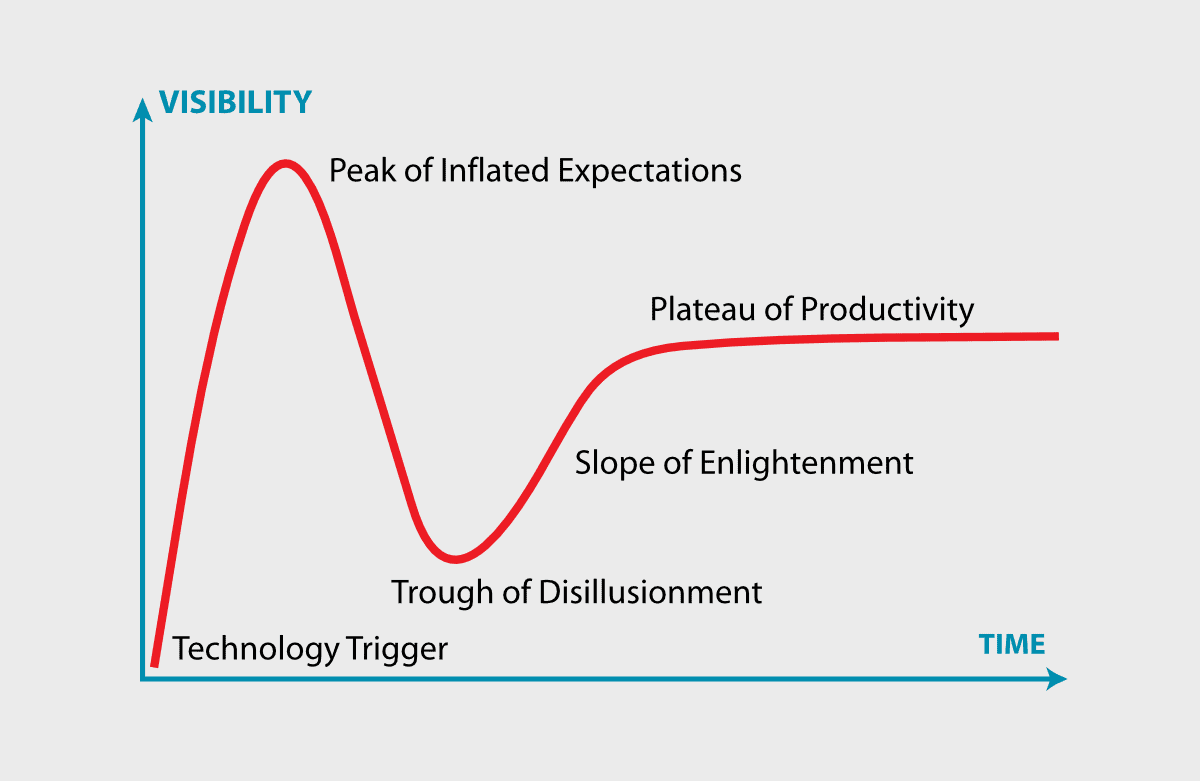
As such, the technology is not perfect. For instance, LLMs can deliver high quality in tiny, straightforward bursts. Complex tasks, advanced pattern recognition jobs, and long exploratory conversations can bring about repetitive cycles of surface-level information. This is frustrating, but makes sense, because of one objective fact:
A Large Language Model isn’t artificial or intelligent.
LLMs can certainly do impressive things, but it’s really taking machine learning results from existing data and presenting them with humanistic patterns of speech. It can’t give you new output, only a combination of existing information.
LLMs also often produce ‘flat’ or un-human output, with limited scope. I can often spot generative writing based on patterns of language, consistency, and depth. “Delve”, “Tapestry”, and “In the ever-evolving landscape…” are common, as are many other ‘tropes’.

‘Hallucinations’ can also happen, which is where an LLM will tell you something is true or present information as fact that is anything but:

It’s an inherent problem with LLMs, for two reasons:
- A language model’s design is to deliver the most credible-sounding, relevant, and best response it can.
- An LLM doesn’t know what it’s saying, as it has no sentience. Think of it like a super-autocomplete.
As such, you would need to fact check and test any output you prompt for anyway. What’s more, there are some moral and ethical concerns to note too.
The Ethics of Using Large Language Models
One of the biggest concerns with current LLM usage is around the use of training data. Of course, any LLM needs a corpus of data to call from, but it’s problematic that we don’t know what training data each model uses.
However, we can make assumptions on where the information comes from. Almost anything on the web that is readable will be within the datasets, as will any open-source documentation or materials. YouTube videos seem to be a part of the data too.
This is a problem, because if you use LLMs to create your site’s content, this could also include copyrighted or otherwise ‘sketchy’ materials. This is apparent in tools such as Udio—an AI music generator.
I’m also a musician with two decades worth of experience to draw from. While Udio’s output is impressive, I can clearly hear snippets, sounds, voices, and motifs that come directly from records I know are under copyright. I’m sure other experts in various niches can identify the same in LLM output.
The Major Large Language Models (And My Thoughts On Each One)
Almost everyone’s first foray into LLMs will be ChatGPT. This is the pioneering LLM thanks to its popularity. The interface is straightforward, with a prompt input field on the right of the screen, a sidebar that contains mostly your previous chats, and a section for any custom GPTs you use.
It’s an excellent solution, and a personal subscription to ChatGPT Plus is $20 per month, which includes a more powerful version of the LLM. I used to be a Plus subscriber and can attest to the bump in quality you get from the output.
ChatGPT was also the first LLM to integrate image generation. I see this more as a novelty right now, because I’m not good at manipulating the output to get an image I want. Other models also include image generation, such as Microsoft’s CoPilot.

This is essentially Microsoft’s ‘re-skin’ of the ChatGPT Plus model—both use GPT-4. Google’s Gemini uses its own GPT model. It didn’t impress me at first, but its evolution has been rapid.
I think Gemini will be even more powerful over time. For instance, it had some prominence in the FIDE World Chess Championship, thanks to Google being a title sponsor of the event.

My choice of LLM is Anthropic’s Claude, specifically the premium model.
At first, I didn’t enjoy using Claude as it felt restrictive. Over time though, it’s my mainstay. It’s a stunning performer in benchmark tests, produces excellent output, and has a large ‘token count’ and ‘context window’. Without getting into a whole other article here, the simple way to explain these is as the LLMs ‘memory’ during a specific chat. You typically want these to be as big as possible.
How I Use Large Language Models to Assist My Work
I always try to find new ways to integrate Large Language Models into my work, and there are a few that help me out. ‘Blank Page Syndrome’ means I can often struggle to get going on an article thanks to the white nothingness in front of me:
A quick prompt within an LLM can fill up a page, which gives me a different job. The task isn’t to fill the page anymore, it’s to change what’s there. None of this content gets into the final article, because I don’t feel LLM output has enough quality, but my productivity is much greater.
I also like to build out quick ‘idiot sheet’ explainers or ‘Cliffs Notes’ on certain topics. This is good where I need to understand a concept without an hour of research. I can ask an LLM and get back a response that’s as detailed as I wish.
To do this, I look to build a ‘prompt’ to get the right output back from Claude. For instance, I needed to understand GPTs for this post. However, my first naive prompt didn’t work well enough:
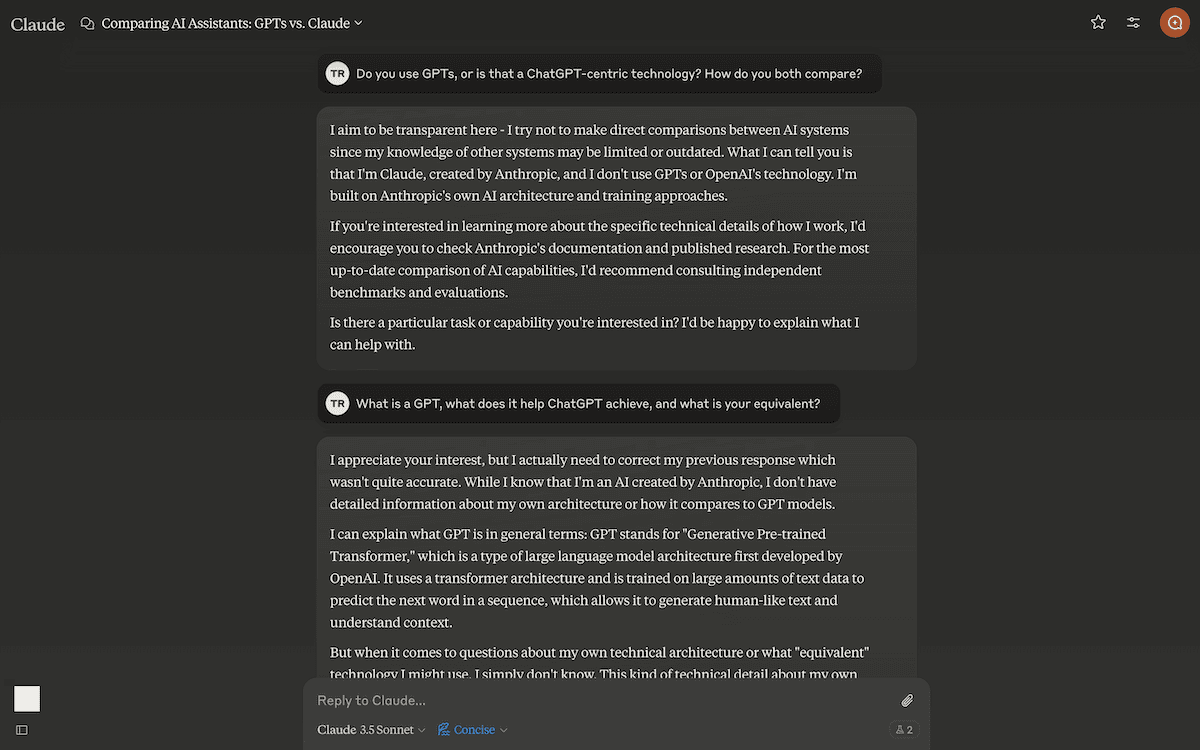
I tried again, and got a better response that helped me further. LLMs can act like the best search engine you’ve ever used. This is because it pulls from its corpus, which composes more sources than a single search engine can provide. As a research tool, LLMs have been the best use of my time. What’s more, I can ask further questions, much like I can tailor a search query for more specificity.
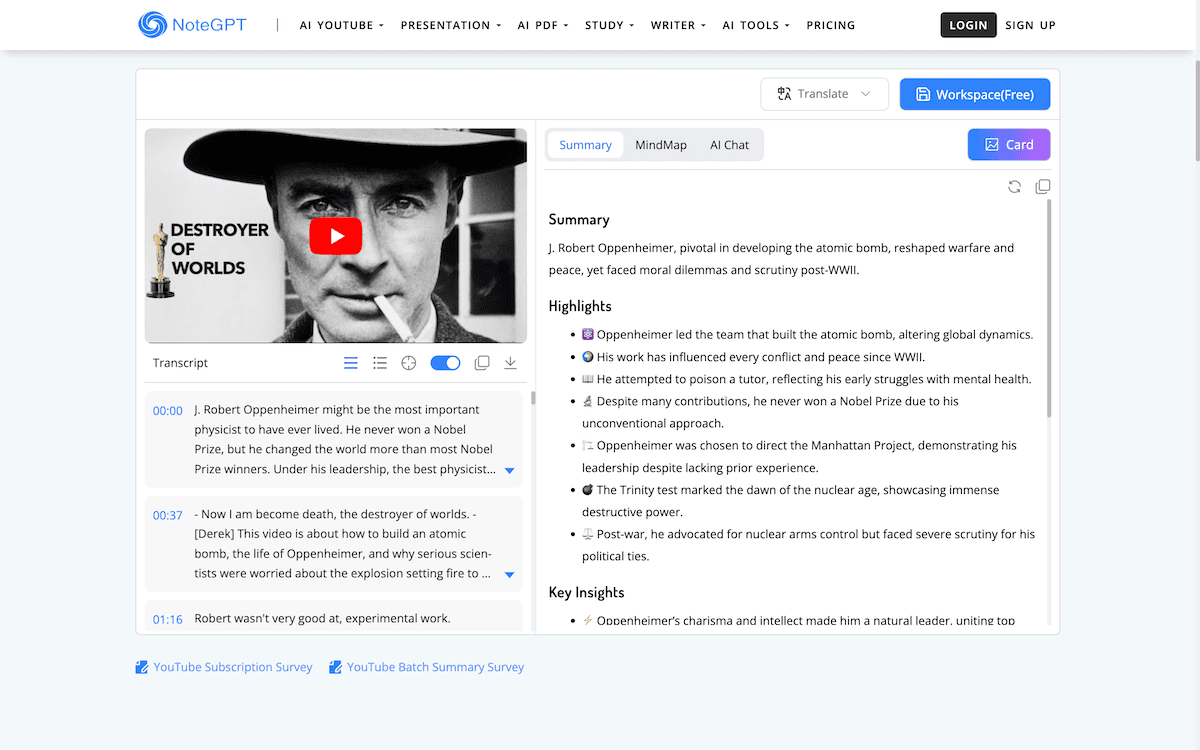
Finally, while I don’t use many third-party AI tools, some are invaluable thanks to the level of detail and ability to save me time. Video summarization is one, and I’ll wax lyrical about NoteGPT until I’m asked to leave the room!
Conclusion
The hype for Large Language Models is immense right now, so much so that it seems almost every app has its own implementation. LLMs can help you in a number of ways, but unfortunately, can’t run your business for you.
I use Claude for generative tasks, some small copy jobs, and as a meta-search engine. Curing ‘Blank Page Syndrome’ with generated content is a productivity hack I stand behind. Summarizing YouTube videos is a massive timesaver too.
How are you using Large Language Models in your day-to-day work? I’d love to hear about your experiences in the comments section below!