So automatisieren Sie das SEO -Keyword -Clustering durch Suchabsicht mit Python

Es gibt viel zu wissen über die Suchabsicht, von der Verwendung von Deep Learning bis zur Suchabsicht, indem sie Text klassifizieren und die SERP -Titel mithilfe der NLP -Techniken (natürlicher Sprache verarbeiten), bis hin zur semantischen Relevanz, mit den erläuterten Vorteilen, bis hin zu Clustering auf der Grundlage der semantischen Relevanz ab.
Wir kennen nicht nur die Vorteile der Entschlüsselungsabsicht, sondern auch eine Reihe von Techniken zur Verfügung, um Skalierung und Automatisierung zu veröffentlichen.
Warum brauchen wir also einen weiteren Artikel über die Automatisierung der Suchabsicht?
Die Suchabsicht ist jetzt immer wichtiger, da die KI -Suche eingetroffen ist.
Während mehr in der Such -Ära von 10 Blue Links im Allgemeinen lag, gilt das Gegenteil mit der KI -Suchtechnologie, da diese Plattformen im Allgemeinen versuchen, die Rechenkosten (pro Flop) zu minimieren, um den Dienst bereitzustellen.
SERPs enthalten immer noch die besten Einblicke für die Suchabsicht
Bei den bisherigen Techniken geht es darum, Ihre eigene KI durchzuführen, dh alle Kopien aus den Titeln des Ranking -Inhalts für ein bestimmtes Schlüsselwort und dann in ein neuronales Netzwerkmodell (das Sie dann erstellen und testen müssen) oder NLP zu Cluster -Keywords einfügen.
Was ist, wenn Sie weder Zeit noch das Wissen haben, um Ihre eigene KI zu erstellen oder die Open AI -API aufzurufen?
Während die Ähnlichkeit der Cosinus als Antwort auf SEO -Fachleute bei der Navigation durch die Abgrenzung von Themen für Taxonomie und Standortstrukturen angepriesen wurde, behaupte ich immer noch, dass die Suchclusterbildung nach SERP -Ergebnissen eine weit überlegene Methode ist.
Das liegt daran, dass AI sehr daran interessiert ist, ihre Ergebnisse auf SERPs zu erden, und das aus gutem Grund – sie ist dem Benutzerverhalten modelliert.
Es gibt einen anderen Weg, der die eigene KI von Google verwendet, um die Arbeit für Sie zu erledigen, ohne alle SERPS -Inhalte kratzen und ein KI -Modell erstellen zu müssen.
Nehmen wir an, dass Google die URLs der Site durch die Wahrscheinlichkeit des Inhalts bezieht, der die Benutzerabfrage in absteigender Reihenfolge erfüllt. Daraus folgt, dass die SERPs wahrscheinlich ähnlich sind, wenn die Absicht für zwei Schlüsselwörter gleich ist.
Seit Jahren verglichen viele SEO -Fachkräfte SERP -Ergebnisse für Keywords, um die gemeinsame (oder gemeinsame) Suchabsicht zu schließen, um die Kernaktualisierungen auf dem Laufenden zu halten. Dies ist also nichts Neues.
Die Wertschöpfung hier ist die Automatisierung und Skalierung dieses Vergleichs, wodurch sowohl Geschwindigkeit als auch größere Präzision angeboten werden.
Socluster von Schlüsselwörtern nach Suchabsichten in der Skala mit Python (mit Code)
Angenommen, Sie haben Ihre SERPs zu einem CSV -Download, importieren wir ihn in Ihr Python -Notizbuch.
1. Importieren Sie die Liste in Ihr Python -Notizbuch
import pandas as pdimport numpy as npserps_input = pd.read_csv('data/sej_serps_input.csv')del serps_input['Unnamed: 0']serps_inputUnten finden Sie die SERPS -Datei, die jetzt in einen Pandas -Datenframe importiert wird.
 Bild vom Autor, April 2025
Bild vom Autor, April 20252. Filterdaten für Seite 1
Wir möchten die Ergebnisse der einzelnen SERP zwischen Schlüsselwörtern vergleichen.
Wir werden den Datenfunk in Mini -Keyword -Datenframes aufteilen, um die Filterfunktion auszuführen, bevor wir zu einem einzigen Datenrahmen rekombiert werden, da wir auf der Schlüsselwortebene filtern möchten:
# Split serps_grpby_keyword = serps_input.groupby("keyword")k_urls = 15# Apply Combinedef filter_k_urls(group_df): filtered_df = group_df.loc[group_df['url'].notnull()] filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls] return filtered_dffiltered_serps = serps_grpby_keyword.apply(filter_k_urls)# Combine## Add prefix to column names#normed = normed.add_prefix('normed_')# Concatenate with initial data framefiltered_serps_df = pd.concat([filtered_serps],axis=0)del filtered_serps_df['keyword']filtered_serps_df = filtered_serps_df.reset_index()del filtered_serps_df['level_1']filtered_serps_df Bild vom Autor, April 2025
Bild vom Autor, April 20253.. Konvertieren Sie die Ranking -URLs in eine Zeichenfolge
Da es mehr SERP -Ergebnis -URLs als Schlüsselwörter gibt, müssen wir diese URLs in eine einzelne Zeile komprimieren, um das SERP des Schlüsselworts darzustellen.
So wie: wie:
# convert results to strings using Split Apply Combine filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")def string_serps(df): df['serp_string'] = ''.join(df['url']) return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps) # Concatenate with initial data frame and clean strung_serps = pd.concat([strung_serps],axis=0) strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30) strung_serps = strung_serps.drop_duplicates() strung_serpsNachfolgend zeigt das SERP für jedes Schlüsselwort in eine einzelne Zeile.
 Bild vom Autor, April 2025
Bild vom Autor, April 20254. Vergleichen Sie die Serrentfernung
Um den Vergleich durchzuführen, benötigen wir jetzt jede Kombination von Keyword -SERP, gepaart mit anderen Paaren:
# align serpsdef serps_align(k, df): prime_df = df.loc[df.keyword == k] prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'}) comp_df = df.loc[df.keyword != k].reset_index(drop=True) prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True) prime_df = pd.concat([prime_df, comp_df], axis=1) prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'}) return prime_dfcolumns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']matched_serps = pd.DataFrame(columns=columns)matched_serps = matched_serps.fillna(0)queries = strung_serps.keyword.to_list()for q in queries: temp_df = serps_align(q, strung_serps) matched_serps = matched_serps.append(temp_df)matched_serps
Das obige zeigt alle Keyword -SERP -Paarkombinationen, sodass es für den SERP -String -Vergleich bereit ist.
Es gibt keine Open-Source-Bibliothek, die Listenobjekte nach Reihenfolge vergleicht. Daher wurde die Funktion nachstehend für Sie geschrieben.
Die Funktion "serp_compare" vergleicht die Überlappung von Stellen und die Reihenfolge dieser Standorte zwischen den SERPs.
import py_stringmatching as smws_tok = sm.WhitespaceTokenizer()# Only compare the top k_urls results def serps_similarity(serps_str1, serps_str2, k=15): denom = k 1 norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)]) #use to tokenize the URLs ws_tok = sm.WhitespaceTokenizer() #keep only first k URLs serps_1 = ws_tok.tokenize(serps_str1)[:k] serps_2 = ws_tok.tokenize(serps_str2)[:k] #get positions of matches match = lambda a, b: [b.index(x) 1 if x in b else None for x in a] #positions intersections of form [(pos_1, pos_2), ...] pos_intersections = [(i 1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None] pos_in1_not_in2 = [i 1 for i,j in enumerate(match(serps_1, serps_2)) if j is None] pos_in2_not_in1 = [i 1 for i,j in enumerate(match(serps_2, serps_1)) if j is None] a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections]) b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2]) c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1]) intent_prime = a_sum b_sum c_sum intent_dist = 1 - (intent_prime/norm) return intent_dist# Apply the functionmatched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)# This is what you getmatched_serps[['keyword', 'keyword_b', 'si_simi']]
Nachdem die Vergleiche ausgeführt wurden, können wir mit dem Clustering von Schlüsselwörtern beginnen.
Wir werden alle Schlüsselwörter mit einer gewichteten Ähnlichkeit von 40% oder mehr behandeln.
# group keywords by search intentsimi_lim = 0.4# join search volumekeysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()keysv_df.head()# append topic volskeywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword', 'search_volume': 'topic_volume'})# sim si_simikeywords_crossed_vols.sort_values('topic_volume', ascending = False)# strip NANkeywords_filtered_nonnan = keywords_crossed_vols.dropna()keywords_filtered_nonnanWir haben jetzt den potenziellen Themennamen, die Schlüsselwörter SERP -Ähnlichkeit und die Suchvolumina von jedem.
Sie werden feststellen, dass Keyword und Keyword_B in Themen bzw. Schlüsselwort umbenannt wurden.
Jetzt werden wir mit der Lambda -Technik über die Spalten im DataFrame iterieren.
Die Lambda -Technik ist ein effizienter Weg, um Zeilen in einem Pandas -Datenframe überzuteilen, da sie Zeilen in eine Liste umwandelt, im Gegensatz zur Funktion .Iterrows ().
Hier geht:
queries_in_df = list(set(matched_serps['keyword'].to_list()))topic_groups = {}def dict_key(dicto, keyo): return keyo in dictodef dict_values(dicto, vala): return any(vala in val for val in dicto.values())def what_key(dicto, vala): for k, v in dicto.items(): if vala in v: return kdef find_topics(si, keyw, topc): if (si >= simi_lim): if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)): if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)): sim_topic_groups[keyw] = [keyw] sim_topic_groups[keyw] = [topc] if dict_key(non_sim_topic_groups, keyw): non_sim_topic_groups.pop(keyw) if dict_key(non_sim_topic_groups, topc): non_sim_topic_groups.pop(topc) if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)): d_key = what_key(sim_topic_groups, keyw) sim_topic_groups[d_key].append(topc) if dict_key(non_sim_topic_groups, keyw): non_sim_topic_groups.pop(keyw) if dict_key(non_sim_topic_groups, topc): non_sim_topic_groups.pop(topc) if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)): d_key = what_key(sim_topic_groups, topc) sim_topic_groups[d_key].append(keyw) if dict_key(non_sim_topic_groups, keyw): non_sim_topic_groups.pop(keyw) if dict_key(non_sim_topic_groups, topc): non_sim_topic_groups.pop(topc) elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups): sim_topic_groups[keyw].append(topc) sim_topic_groups[keyw].append(keyw) if keyw in non_sim_topic_groups: non_sim_topic_groups.pop(keyw) if topc in non_sim_topic_groups: non_sim_topic_groups.pop(topc) elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups): sim_topic_groups[topc].append(keyw) sim_topic_groups[topc].append(topc) if keyw in non_sim_topic_groups: non_sim_topic_groups.pop(keyw) if topc in non_sim_topic_groups: non_sim_topic_groups.pop(topc) elif (keyw in sim_topic_groups) and (topc in sim_topic_groups): if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]): sim_topic_groups[keyw].append(topc) [sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)] sim_topic_groups.pop(topc) elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]): sim_topic_groups[topc].append(keyw) [sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)] sim_topic_groups.pop(keyw) elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]): if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw: sim_topic_groups.pop(keyw) elif si < simi_lim: if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)): non_sim_topic_groups[keyw] = [keyw] if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)): non_sim_topic_groups[topc] = [topc]Nachfolgend zeigt ein Wörterbuch, das alle Schlüsselwörter enthält, die durch Suchabsichten in nummerierten Gruppen aufgenommen wurden:
{1: ['fixed rate isa', 'isa rates', 'isa interest rates', 'best isa rates', 'cash isa', 'cash isa rates'], 2: ['child savings account', 'kids savings account'], 3: ['savings account', 'savings account interest rate', 'savings rates', 'fixed rate savings', 'easy access savings', 'fixed rate bonds', 'online savings account', 'easy access savings account', 'savings accounts uk'], 4: ['isa account', 'isa', 'isa savings']}Lassen Sie uns das in einen Datenrahmen einbinden:
topic_groups_lst = []for k, l in topic_groups_numbered.items(): for v in l: topic_groups_lst.append([k, v])topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword']) topic_groups_dictdf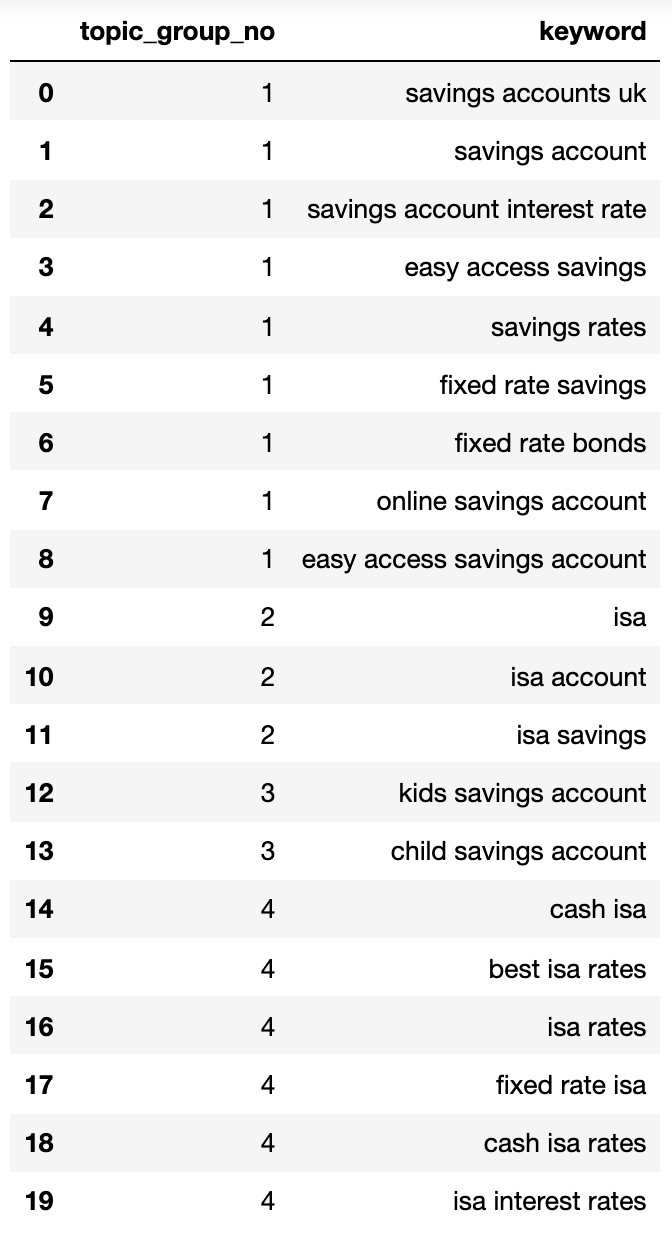 Bild vom Autor, April 2025
Bild vom Autor, April 2025Die obigen Suchabsichten zeigen eine gute Annäherung an die Schlüsselwörter in ihnen, was ein SEO -Experte wahrscheinlich erreichen würde.
Obwohl wir nur einen kleinen Satz von Schlüsselwörtern verwendet haben, kann die Methode offensichtlich auf Tausende skaliert werden (wenn nicht mehr).
Aktivieren Sie die Ausgänge, um Ihre Suche besser zu machen
Natürlich könnte das oben genannte mithilfe neuronaler Netzwerke weiter genommen werden, wodurch die Ranglisteninhalte für genauere Cluster und die Namensnamen der Clustergruppe verarbeitet werden, wie einige der kommerziellen Produkte bereits vorhanden sind.
Im Moment können Sie mit dieser Ausgabe:
- Integrieren Sie dies in Ihre eigenen SEO -Dashboard -Systeme, um Ihre Trends und die SEO -Berichterstattung aussagekräftiger zu gestalten.
- Erstellen Sie besser bezahlte Suchkampagnen, indem Sie Ihre Google -Anzeigenkonten durch Suchabsicht für eine höhere Qualitätsbewertung strukturieren.
- Merge redundante Facetten -E -Commerce -Such -URLs.
- Strukturieren Sie die Taxonomie einer Einkaufsseite nach Suchabsicht anstelle eines typischen Produktkatalogs.
Ich bin sicher, dass es mehr Anwendungen gibt, die ich nicht erwähnt habe. Sie können wichtige wichtige kommentieren, die ich noch nicht erwähnt habe.
In jedem Fall hat Ihre SEO -Keyword -Recherche gerade so ein bisschen skalierbar, genau und schneller!
Laden Sie den vollständigen Code hier für Ihre eigene Verwendung herunter.
Weitere Ressourcen:
- Semantisches Keyword -Clustering für mehr als 10.000 Schlüsselwörter [With Script]
- Tangential SEO: Keywords für Inhalte finden, die niemand sonst hat
- Das vollständige Arbeitsbuch für technische SEO -Audit
Ausgewähltes Bild: Buch und Bee/Shutterstock





