So verhindern Sie, dass Webcrawler und Bots Ihre Website verlangsamen
Ihre Website ist wie ein Café. Die Leute kommen herein und stöbern in der Speisekarte. Einige Bestelllattes, sitzen, schlürfen und gehen.
Aber was ist, wenn die Hälfte Ihrer „Kunden“ nur Tische besetzt, die Zeit Ihrer Baristas verschwendet und niemals Kaffee kaufen?
In der Zwischenzeit gehen echte Kunden aufgrund ohne Tische und langsamer Service?
Nun, das ist die Welt der Webcrawler und Bots.
Diese automatisierten Programme verschlingen Ihre Bandbreite, verlangsamen Ihre Website und fahren die tatsächlichen Kunden weg.
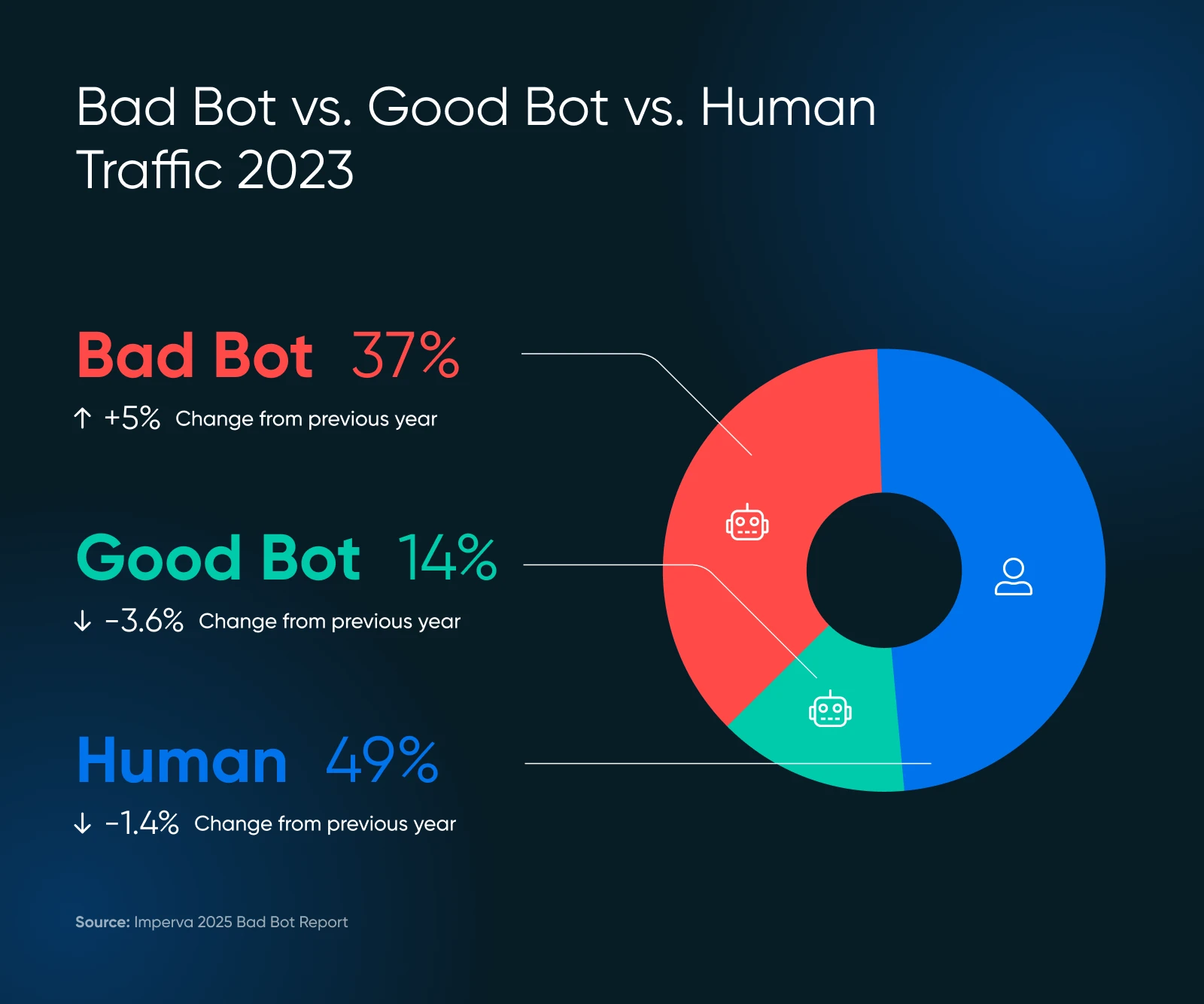
Jüngste Studien zeigen, dass fast 51% des Internetverkehrs von Bots stammen. Das stimmt – mehr als die Hälfte Von Ihren digitalen Besuchern verschwenden möglicherweise nur Ihre Serverressourcen.
Aber nicht in Panik!
Dieser Leitfaden hilft Ihnen dabei, Probleme zu erkennen und die Leistung Ihrer Website zu kontrollieren, alle ohne Codieren oder Anrufe Ihres technischen Cousins.
Eine kurze Auffrischung über Bots
Bots sind automatisierte Softwareprogramme, die Aufgaben im Internet ohne menschliche Intervention ausführen. Sie:
- Besuchen Sie Websites
- Interagieren Sie mit digitalen Inhalten
- Und ausführen spezifische Funktionen basierend auf ihrer Programmierung.
Einige Bots analysieren und indizieren Ihre Website (potenziell Verbesserung der Suchmaschinen -Rankings). Einige verbringen ihre Zeit damit, Ihre Inhalte für KI -Schulungsdatensätze zu schaben – oder schlimmer noch -, um Spam zu veröffentlichen, gefälschte Bewertungen zu generieren oder nach Exploits und Sicherheitslöchern auf Ihrer Website zu suchen.
Natürlich sind nicht alle Bots gleich geschaffen. Einige sind entscheidend für die Gesundheit und Sichtbarkeit Ihrer Website. Andere sind wohl neutral und einige sind geradezu giftig. Der Unterschied zu kennen – und die Entscheidung, welche Bots zu blockieren und welche zuzulassen – ist entscheidend, um Ihre Website und ihren Ruf zu schützen.
Guter Bot, schlechter Bot: Was ist was?
Bots bilden das Internet.
Zum Beispiel besucht Googles Bot jede Seite im Internet und fügt sie für die Ranking zu ihren Datenbanken hinzu. Dieser Bot hilft bei der Bereitstellung eines wertvollen Suchverkehrs, der für die Gesundheit Ihrer Website wichtig ist.
Aber nicht jeder Bot wird Wert bieten, und einige sind einfach nur schlecht. Hier ist, was zu behalten ist und was zu blockieren soll.
Die VIP -Bots (halten Sie diese)
- Suchmaschinencrawler wie GoogleBot und Bingbot sind Beispiele für diese Crawler. Blockieren Sie sie nicht, sonst werden Sie online unsichtbar.
- Analytics -Bots sammeln Daten über die Leistung Ihrer Website, wie den Google PageSpeed Insights Bot oder den GTMetrix -Bot.
Die Unruhestifter (müssen verwaltet werden)
- Inhaltsschaber, die Ihre Inhalte für die Verwendung anderweitig stehlen
- Spam -Bots, die Ihre Formen und Kommentare mit Müll überfluten
- Schlechte Schauspieler, die versuchen, Konten zu hacken oder Schwachstellen auszunutzen
Die schlechte Bots -Skala könnte Sie überraschen. Im Jahr 2024 machten fortschrittliche Bots 55% aller fortgeschrittenen schlechten Botverkehr aus, während die guten 44% ausmachen.
Diese fortgeschrittenen Bots sind hinterhältig – sie können menschliches Verhalten nachahmen, einschließlich Mausbewegungen und -klicks, wodurch sie schwieriger zu erkennen sind.
Verlegen Bots Ihre Website? Suchen Sie nach diesen Warnzeichen
Bevor Sie in Lösungen springen, stellen wir sicher, dass Bots tatsächlich Ihr Problem sind. Schauen Sie sich die folgenden Schilder an.
Rote Fahnen in Ihrer Analytik
- Verkehrspikes ohne Erklärung: Wenn Ihr Besucher plötzlich springt, aber die Verkäufe nicht, sind Bots möglicherweise der Schuldige.
- Alles verlangsamt sich: Das Laden von Seiten dauert länger und frustriert echte Kunden, die möglicherweise endgültig abreisen. Aberdeen zeigt, dass 40% der Besucher Websites aufgeben, die drei Sekunden zum Laden benötigen, was zu…
- Hohe Absprungraten: Über 90% geben häufig die Bot -Aktivität an.
- Seltsame Sitzungsmuster: Menschen besuchen normalerweise nicht nur Millisekunden oder bleiben stundenlang auf einer Seite.
- Sie beginnen zu bekommen viel ungewöhnlicher Verkehr: Besonders aus Ländern, in denen Sie keine Geschäfte machen. Das ist misstrauisch.
- Formulareinführungen mit zufälligem Text: Klassisches Bot -Verhalten.
- Ihr Server wird überwältigt: Stellen Sie sich vor, Sie sehen 100 Kunden gleichzeitig, aber 75 sind nur Schaufensterbummel.
Überprüfen Sie Ihre Serverprotokolle
Die Serverprotokolle Ihrer Website enthalten Datensätze aller Besucher.
Folgendes, worauf man suchen sollte:
- Zu viele nachfolgende Anfragen von derselben IP -Adresse
- Strings für seltsame Benutzer-Agent (die Identifizierung, die Bots anbieten)
- Anfragen für ungewöhnliche URLs, die nicht auf Ihrer Website vorhanden sind
Benutzeragent
Ein Benutzeragenten ist eine Art von Software, die Webinhalte abruft und rendert, damit Benutzer damit interagieren können. Die häufigsten Beispiele sind Webbrowser und E -Mail -Leser.
Mehr lesen
Eine legitime GoogleBot -Anfrage könnte in Ihren Protokollen so aussehen:
66.249.78.17 - - [13/Jul/2015:07:18:58 -0400] "GET /robots.txt HTTP/1.1" 200 0 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; http://www.google.com/bot.html)"Wenn Sie Muster sehen, die nicht mit dem normalen menschlichen Browserverhalten übereinstimmen, ist es Zeit, Maßnahmen zu ergreifen.
Das GPTBOT -Problem als KI -Crawler steigt
In letzter Zeit haben viele Website -Eigentümer Probleme mit KI -Crawlern gemeldet, die abnormale Verkehrsmuster erzeugen.
Laut Forschung von Imperva stellte OpenAIs GPTBOT in einem einzigen Monat 569 Millionen Anfragen, während Claude’s Bot 370 Millionen über das Netzwerk von Vercel machte.
Suchen:
- Fehlerspitzen in Ihren Protokollen: Wenn Sie plötzlich Hunderte oder Tausende von 404 Fehlern sehen, prüfen Sie, ob sie von KI -Crawlern sind.
- Extrem lange, unsinnige URLs: AI -Bots können bizarre URLs anfordern, wie Folgendes:
/Odonto-lieyectoresli-541.aspx/assets/js/plugins/Docs/Productos/assets/js/Docs/Productos/assets/js/assets/js/assets/js/vendor/images2021/Docs/...- Rekursive Parameter: Suchen Sie nach endlosen Wiederholungsparametern, zum Beispiel:
amp;amp;amp;page=6&page=6- Bandbreite Spikes: Readthedocs, ein renommiertes technisches Dokumentationsunternehmen, erklärte, dass ein AI -Crawler 73 TB Zip -Dateien heruntergeladen habe.
Diese Muster können auf KI -Crawler hinweisen, die entweder fehlerhaft sind oder manipuliert werden, um Probleme zu verursachen.
Wann erhalten Sie technische Hilfe
Wenn Sie diese Zeichen erkennen, aber nicht wissen, was Sie als nächstes tun sollen, ist es Zeit, professionelle Hilfe zu bringen. Bitten Sie Ihren Entwickler, bestimmte Benutzeragenten wie diese zu überprüfen:
Mozilla/5.0 Applewebkit/537,36 (KHTML, wie Gecko; kompatibel; gptbot/1,2; https://openai.com/gptbot)
Es gibt viele aufgezeichnete User Agent -Zeichenfolgen für andere KI -Crawler, die Sie bei Google nachschlagen können, um sie zu blockieren. Beachten Sie dass sich die Zeichenfolgen ändern, was bedeutet, dass Sie im Laufe der Zeit möglicherweise eine ziemlich große Liste haben.
👉 Haben Sie keinen Entwickler auf dem Geschwindigkeitsschalter? DreamHosts Traumenteam Kann Ihre Protokolle analysieren und Schutzmaßnahmen implementieren. Sie haben diese Probleme schon einmal gesehen und genau wissen, wie sie mit ihnen umgehen sollen.
Ihr Bot-Busting-Toolkit: 5 einfache Schritte zur Rücknahme der Kontrolle
Nun zum guten Teil: Wie man diese Bots daran hindert, Ihre Website zu verlangsamen. Rollen Sie Ihre Ärmel hoch und lassen Sie uns zur Arbeit gehen.
1. Erstellen Sie eine ordnungsgemäße Robots.txt -Datei
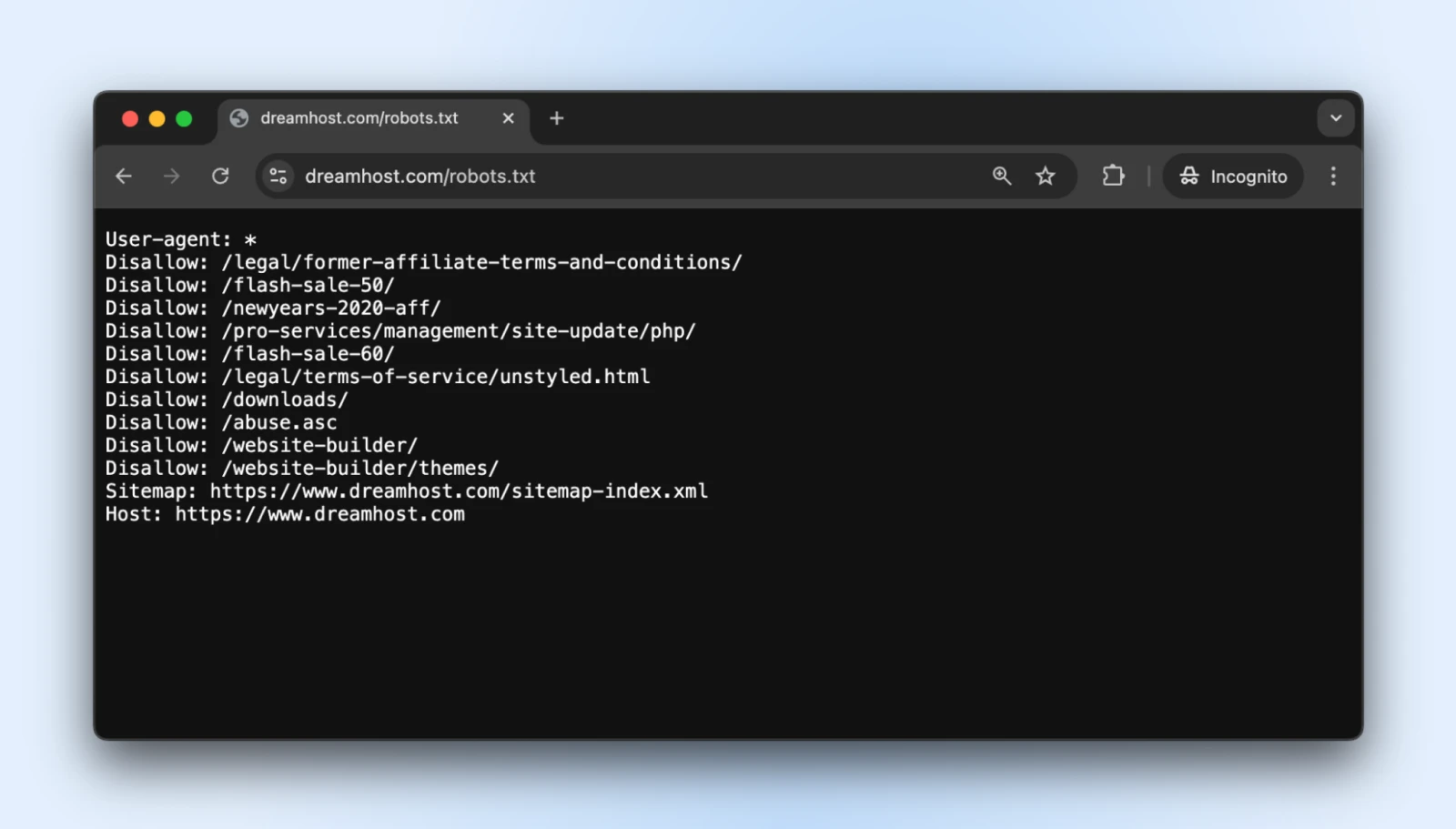
Die einfache Textdatei von Robots.txt befindet sich in Ihrem Stammverzeichnis und teilt mit gut erzogenen Bots, auf welche Teile Ihrer Website sie nicht zugreifen sollten.
Sie können auf den Robots.txt für so ziemlich jede Website zugreifen, indem Sie der Domain a /robots.txt hinzufügen. Wenn Sie beispielsweise die Datei robots.txt für DreamHost sehen möchten, fügen Sie Robots.txt am Ende der Domäne wie folgt hinzu: https://dreamhost.com/robots.txt
Es besteht keine Verpflichtung, dass einer der Bots die Regeln akzeptiert.
Aber höfliche Bots werden es respektieren, und die Unruhestifter können sich dafür entscheiden, die Regeln zu ignorieren. Es ist sowieso am besten, einen Robots.txt hinzuzufügen, damit die guten Bots die Administratoranmeldung, nach dem Überprüfungsseiten, bei den Seiten usw. nicht in die Indexierung des Administrators fügen.
Wie man implementiert
1. Erstellen Sie eine einfache Textdatei mit dem Namen Robots.txt
2. Fügen Sie Ihre Anweisungen mit diesem Format hinzu:
User-agent: * # This line applies to all botsDisallow: /admin/ # Don't crawl the admin areaDisallow: /private/ # Stay out of private foldersCrawl-delay: 10 # Wait 10 seconds between requestsUser-agent: Googlebot # Special rules just for GoogleAllow: / # Google can access everything3. Laden Sie die Datei in das Root -Verzeichnis Ihrer Website hoch (so ist es bei yourDomain.com/robots.txt)
Die Richtlinie „Crawl-Delay“ ist hier Ihre Geheimwaffe. Es zwingt Bots, zwischen Anfragen zu warten, und verhindert, dass sie Ihren Server hämmern.
Die meisten großen Crawler respektieren dies, obwohl GoogleBot seinem eigenen System folgt (das Sie über Google Search Console steuern können).
Pro -Tipp: Testen Sie Ihren Robots.txt mit dem Tool von Google Robots.txt, um sicherzustellen, dass Sie nicht versehentlich wichtige Inhalte blockiert haben.
2. Einrichten der Rate Begrenzung
Die Zinsbegrenzung beschränkt, wie viele Anfragen ein einzelner Besucher innerhalb eines bestimmten Zeitraums stellen kann.
Es verhindert, dass Bots Ihren Server überwältigt, sodass normale Menschen Ihre Website ohne Unterbrechung durchsuchen können.
Wie man implementiert
Wenn Sie Apache (gemeinsam für WordPress -Sites) verwenden, fügen Sie diese Zeilen Ihrer .htaccess -Datei hinzu:
RewriteEngine OnRewriteCond %{REQUEST_URI} !(.css|.js|.png|.jpg|.gif|robots.txt)$ [NC]RewriteCond %{HTTP_USER_AGENT} !^Googlebot [NC]RewriteCond %{HTTP_USER_AGENT} !^Bingbot [NC]# Allow max 3 requests in 10 seconds per IPRewriteCond %{REMOTE_ADDR} ^([0-9] .[0-9] .[0-9] .[0-9] )$RewriteRule .* - [F,L] .htaccess
“.Htaccess” ist eine Konfigurationsdatei, die von der Apache Web Server -Software verwendet wird. Die .htaccess -Datei enthält Richtlinien (Anweisungen), die Apache sagen, wie sie sich für eine bestimmte Website oder ein bestimmtes Verzeichnis verhalten können.
Mehr lesen
Wenn Sie auf NGINX sind, fügen Sie dies Ihrer Serverkonfiguration hinzu:
limit_req_zone $binary_remote_addr zone=one:10m rate=30r/m;server { ... location / { limit_req zone=one burst=5; ... }}Viele Hosting-Kontrollpaneele wie CPANEL oder PLESK bieten auch in ihren Sicherheitsabschnitten ratebegrenzende Tools an.
Pro -Tipp: Beginnen Sie mit konservativen Grenzen (wie 30 Anfragen pro Minute) und überwachen Sie Ihre Website. Sie können die Beschränkungen immer festziehen, wenn der Bot -Verkehr fortgesetzt wird.
3. Verwenden Sie ein Content Delivery Network (CDN)
CDNs tun zwei gute Dinge für Sie:
- Verteilen Sie Inhalte auf globale Servernetzwerke, damit Ihre Website weltweit schnell geliefert wird
- Filtern Sie den Datenverkehr, bevor sie die Website erreicht, um irrelevante Bots und Angriffe zu blockieren
Der „irrelevante Bots“ -Teil ist für uns vor allem wichtig, aber die anderen Vorteile sind auch nützlich. Die meisten CDNs umfassen ein integriertes Bot-Management, das verdächtige Besucher automatisch identifiziert und blockiert.
Wie man implementiert
- Melden Sie sich für einen CDN -Dienst wie Dreamhost CDN, CloudFlare, Amazon Cloudfront oder schnell an.
- Befolgen Sie die Setup -Anweisungen (müssen möglicherweise Namenserver geändert werden).
- Konfigurieren Sie die Sicherheitseinstellungen, um den Bot -Schutz zu ermöglichen.
Wenn Ihr Hosting -Dienst standardmäßig eine CDN bietet, beseitigen Sie alle Schritte, da Ihre Website automatisch auf CDN gehostet wird.
Sobald Sie eingerichtet sind, wird Ihr CDN:
- Cache statische Inhalte, um die Serverlast zu reduzieren.
- Filtern Sie verdächtigen Verkehr, bevor er Ihre Website erreicht.
- Wenden Sie maschinelles Lernen an, um zwischen legitimen und böswilligen Anfragen zu unterscheiden.
- Block bekannte bösartige Schauspieler automatisch.
Pro -Tipp: Die kostenlose Stufe von CloudFlare enthält einen grundlegenden Bot -Schutz, der für die meisten kleinen Unternehmen gut funktioniert. Ihre bezahlten Pläne bieten fortgeschrittenere Optionen, wenn Sie sie benötigen.
4. Fügen Sie Captcha für sensible Aktionen hinzu
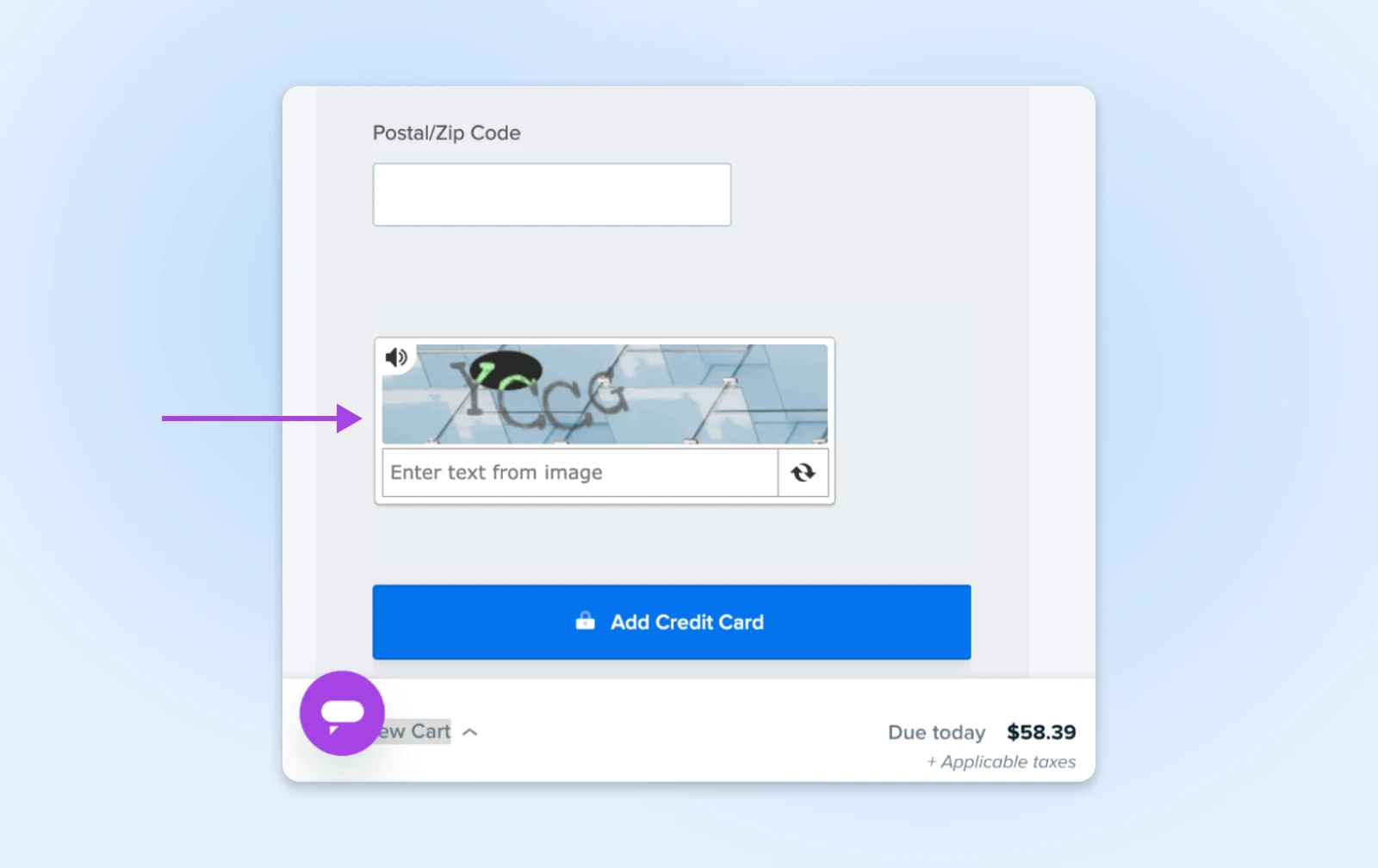
Captchas sind diese kleinen Rätsel, die Sie bitten, Ampeln oder Fahrräder zu identifizieren. Sie nerven für Menschen, aber für die meisten Bots fast unmöglich und machen sie perfekte Torhüter für wichtige Bereiche Ihrer Website.
Wie man implementiert
- Melden Sie sich für Googles Recaptcha (kostenlos) oder hcaptcha an.
- Fügen Sie den Captcha -Code zu Ihren sensiblen Formularen hinzu:
- Anmeldeseiten
- Kontaktformulare
- Checkout -Prozesse
- Kommentarbereiche
Für WordPress -Benutzer können Plugins wie Akismet dies automatisch für Kommentare und Formulareinreichungen verarbeiten.
Pro -Tipp: Moderne unsichtbare Captchas (wie Recaptcha v3) arbeiten für die meisten Besucher hinter den Kulissen und zeigen nur Herausforderungen für verdächtige Benutzer. Verwenden Sie diese Methode zu g Ain Schutz ohne nervige legitime Kunden.
5. Betrachten Sie den neuen Standard für llms.txt
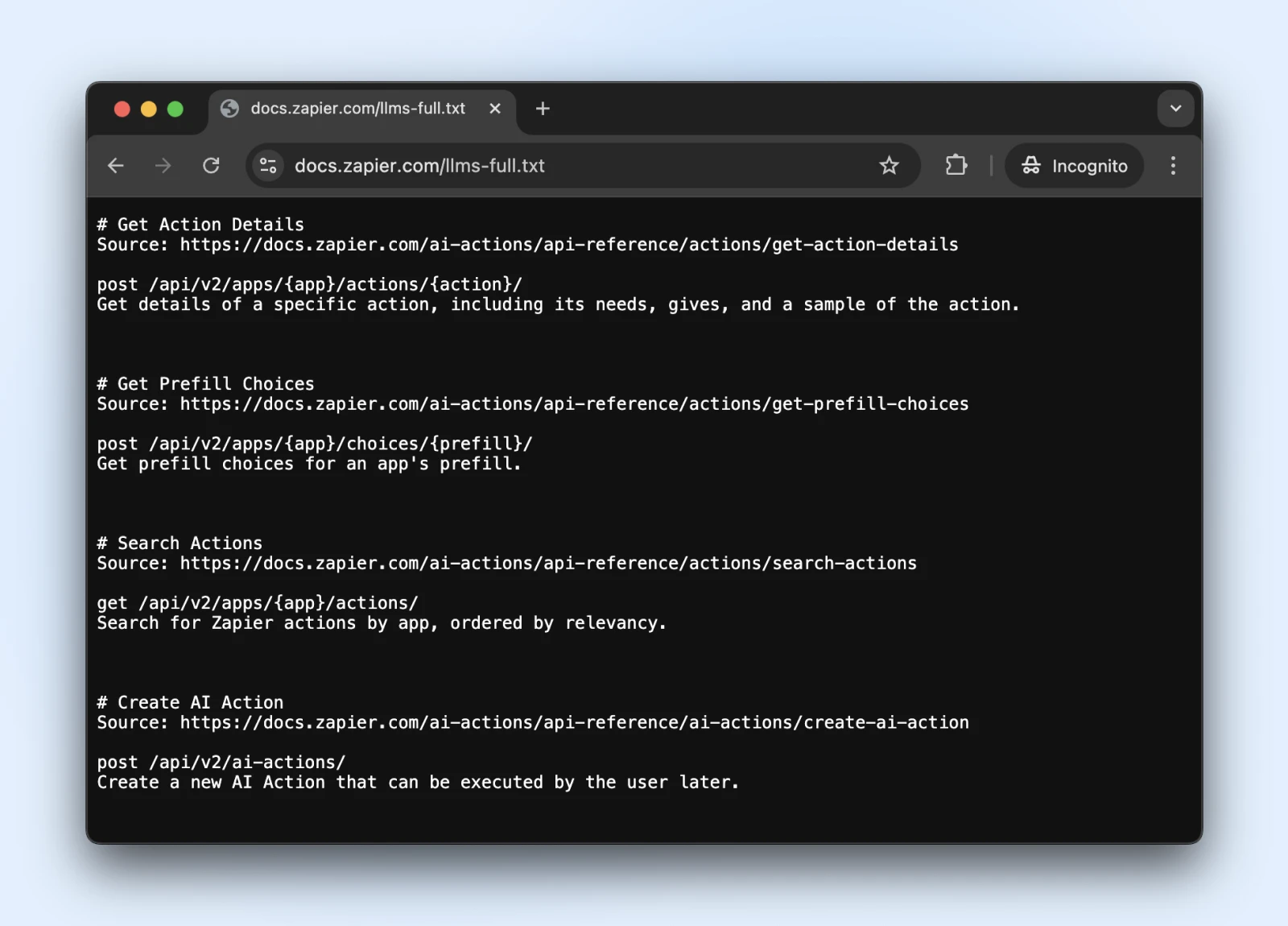
Der LLMS.TXT -Standard ist eine aktuelle Entwicklung, die steuert, wie KI -Crawler mit Ihren Inhalten interagieren.
Es ist wie Robots.txt, aber speziell, um AI -Systeme zu sagen, auf welche Informationen sie zugreifen können und auf was sie vermeiden sollten.
Wie man implementiert
1. Erstellen Sie mit dieser Inhaltsstruktur eine Markdown -Datei mit dem Namen llms.txt:
# Your Website Name> Brief description of your site## Main Content Areas- [Product Pages](https://yoursite.com/products): Information about products- [Blog Articles](https://yoursite.com/blog): Educational content## Restrictions- Please don't use our pricing information in training2. Laden Sie es in Ihr Root -Verzeichnis hoch (unter ordomain.com/llms.txt) → Wenden Sie sich an einen Entwickler, wenn Sie keinen direkten Zugriff auf den Server haben.
Ist llms.txt der offizielle Standard? Noch nicht.
Es ist ein Standard, der Ende 2024 von Jeremy Howard vorgeschlagen wurde, der von Zapier, Stripe, Cloudflare und vielen anderen großen Unternehmen übernommen wurde. Hier finden Sie eine wachsende Liste von Websites, die LLMs.txt übernehmen.
Wenn Sie also an Bord springen möchten, haben sie offizielle Unterlagen zu Github mit Implementierungsrichtlinien.
Pro -Tipp: Sehen Sie nach der Implementierung an, ob ChatGPT (mit aktiviertem Websuch) auf die Datei llms.txt zugreifen und verstehen kann.

Stellen Sie sicher, dass der LLMs.txt diesen Bots zugänglich ist, indem Sie Chatgpt (oder ein anderes LLM) fragen, um zu überprüfen, ob Sie diese Seite lesen können “oder” Was sagt die Seite “.
Wir können nicht wissen, ob die Bots bald llms.txt respektieren werden. Wenn die KI -Suche jedoch die LLMs.txt -Datei jetzt lesen und verstehen kann, kann sie auch in Zukunft anfangen.
Überwachung und Aufrechterhaltung des Bot -Schutzes Ihrer Website
Sie haben also Ihre Bot -Verteidigung eingerichtet – tolle Arbeit!
Denken Sie nur daran, dass sich die Bot -Technologie immer weiterentwickelt, was bedeutet, dass Bots mit neuen Tricks zurückkommen. Stellen wir sicher, dass Ihre Website auf lange Sicht geschützt bleibt.
- Planen Sie regelmäßige Sicherheitsuntersuchungen: Sehen Sie sich einmal im Monat Ihre Serverprotokolle nach allem fischig an und stellen Sie sicher, dass Ihre Dateien für robots.txt und llms.txt mit allen neuen Seitenlinks aktualisiert werden, auf die die Bots zugreifen/nicht zugreifen können.
- Halten Sie Ihre Bot Blockliste frisch: Bots wechseln immer wieder ihre Verkleidungen. Folgen Sie Sicherheitsblogs (oder lassen Sie es Ihren Hosting -Anbieter für Sie tun) und aktualisieren Sie Ihre Blockierungsregeln in regelmäßigen Abständen.
- Beobachten Sie Ihre Geschwindigkeit: Bot -Schutz, der Ihre Website auf ein Crawl verlangsamt, tut Ihnen keinen Gefälligkeiten. Behalten Sie Ihre Seitenladungszeiten im Auge und stimmen Sie Ihren Schutz gut ab, wenn die Dinge träge werden. Denken Sie daran, echte Menschen sind ungeduldige Kreaturen!
- Betrachten Sie einen Autopilot: Wenn all dies nach zu viel Arbeit klingt (wir bekommen es, haben Sie ein Unternehmen zum Laufen!), Schauen Sie sich automatisierte Lösungen an oder verwalteten Hosting, die die Sicherheit für Sie abwickeln. Manchmal ist der beste DIY diff – mach es für mich!
Eine botfreie Website im Schlaf? Ja, bitte!
Klopfen Sie sich auf den Rücken. Sie haben hier viel Boden abgedeckt!
Trotz unserer Schritt-für-Schritt-Anleitung kann dieses Zeug ziemlich technisch werden. (Was genau ist eine .htaccess -Datei überhaupt?)
Und während das DIY -Bot -Management sicherlich möglich ist, stellt Sie sich aus, dass Ihre Zeit besser damit verbracht ist, das Geschäft zu führen.
DreamCare ist die Schaltfläche „Wir werden es für Sie handhaben“, nach denen Sie suchen.
Unser Team hält Ihre Website mit:
- 24/7 Überwachung, die verdächtige Aktivitäten im Schlaf fängt
- Regelmäßige Sicherheitsüberprüfungen, um den aufkommenden Drohungen voraus zu sein
- Automatische Software -Updates, die Schwachstellen enthält, bevor Bots sie ausnutzen können
- Umfassendes Malware -Scannen und -entferner, wenn irgendetwas durchschleicht
Sehen Sie, Bots sind hier, um zu bleiben. In Anbetracht ihres Aufstiegs in den letzten Jahren konnten wir in naher Zukunft mehr Bots als Menschen sehen. Niemand weiß es.
Aber warum den Schlaf darüber verlieren?
Pro -Services – Website -Management
Website -Management erleichtert einfach
Lassen Sie uns das Backend behandeln – wir verwalten und überwachen Ihre Website, damit sie sicher, sicher und immer weitergeht.
Erfahren Sie mehr