Strukturierte Daten im Jahr 2024: Schlüsselmuster enthüllen die Zukunft der KI-Entdeckung [Datenstudie]
![Strukturierte Daten im Jahr 2024: Schlüsselmuster enthüllen die Zukunft der KI-Entdeckung [Datenstudie]](https://behmaster.ir/wp-content/uploads/2024/12/601607-strukturierte-daten-im-jahr-2024-schlusselmuster-enthullen-die-zukunft-der-ki-entdeckung-datenstudie.png)
Die strukturierte Datenlandschaft hat im Jahr 2024 einen erheblichen Wandel erfahren, der durch den Aufstieg der KI-gestützten Suche, die wachsende Bedeutung maschinenlesbarer Inhalte und die Notwendigkeit, große Sprachmodelle auf Faktendaten zu verankern, vorangetrieben wird.
Nach neuesten Erkenntnissen Web-Almanach des HTTP-ArchivsDie Analyse strukturierter Daten auf 16,9 Millionen Websites zeigt eine deutliche Verlagerung von der traditionellen SEO-Implementierung hin zur ausgefeilteren Entwicklung von Wissensgraphen, die KI-Erkennungssysteme unterstützen.
Während Google im Jahr 2023 bestimmte Rich-Suchergebnisse wie FAQs und HowTos einstellte, führte es gleichzeitig eine beispiellose Anzahl neuer strukturierter Datentypen ein, darunter Fahrzeuglisten, Kursinformationen, Ferienwohnungen, Profilseiten und 3D-Produktmodelle.
Im Februar 2024 wurde die Unterstützung für Produktvarianten und GS1 Digital Link erweitert, gefolgt vom Beta-Start strukturierter Datenkarussells im März.
Diese rasante Entwicklung signalisiert ein ausgereiftes Ökosystem, in dem strukturierte Daten nicht nur der Sichtbarkeit der Suche dienen, sondern auch die Grundlage für sachliche KI-Reaktionen, das Training von Sprachmodellen und verbesserte digitale Produkterlebnisse bilden.
Analyse und Methodik
Die in diesem Artikel vorgestellten Erkenntnisse basieren auf der Ausgabe 2024 des Kapitels „Strukturierte Daten“ des Web Almanac des HTTP-Archivs. Der Jahresbericht analysiert den Zustand des Webs, indem er die Implementierung strukturierter Daten auf 16,9 Millionen Websites bewertet. Diese Datensätze Sind öffentlich abfragbar auf BigQuery in Tabellen im `httparchive.all.*` Tabellen für das Datum date = '2024-06-01' und verlässt sich auf Tools wie WebPageTest, Lighthouse und Wappalyzer, um Metriken zu strukturierten Datenformaten, Akzeptanztrends und Leistung zu erfassen.
Trends bei der Einführung strukturierter Daten
Die Analyse zeigt ein überzeugendes Wachstum bei den wichtigsten strukturierten Datenformaten:
- JSON-LD erreicht eine Akzeptanzrate von 41 % ( 7 % im Jahresvergleich).
- RDFa bleibt mit einer Präsenz von 66 % ( 3 % im Jahresvergleich) führend.
- Die Implementierung von Open Graph steigt auf 64 % ( 5 % im Jahresvergleich).
- Die Nutzung des Meta-Tags X (Twitter) steigt auf 45 % ( 8 % im Jahresvergleich).
Diese weit verbreitete Akzeptanz zeigt, dass Unternehmen in strukturierte Daten investieren, nicht nur für die Sichtbarkeit in der Suche, sondern auch, um KI und Crawlern zu ermöglichen, ihre digitalen Erfahrungen zu verstehen und zu verbessern.
KI-Erkennungs- und Wissensdiagramme
Die Beziehung zwischen strukturierten Daten und KI-Systemen entwickelt sich auf komplexe Weise.
Während viele generative KI-Suchmaschinen ihren Ansatz zur Nutzung strukturierter Daten noch entwickeln, scheinen etablierte Plattformen wie Bing Copilot, Google Gemini und spezialisierte Tools wie SearchGPT bereits den Wert entitätsbasierten Verständnisses zu demonstrieren, insbesondere für lokale Abfragen und Faktenvalidierung.
Schulung und Entitätsverständnis
Generative KI-Suchmaschinen werden auf riesigen Datensätzen trainiert, die strukturierte Datenmarkierungen enthalten, und beeinflussen dadurch, wie sie:
- Entitäten (Produkte, Standorte, Organisationen) erkennen und kategorisieren.
- Bodenreaktionen. Wir sehen dies in Systemen wie DataGemma, die strukturierte Daten verwenden, um Antworten auf überprüfbare Fakten zu stützen.
- Beziehungen zwischen verschiedenen Datenpunkten verstehen. Dies wird besonders deutlich, wenn schema.org zur Aggregation von Datensätzen aus maßgeblichen Quellen weltweit verwendet wird.
- Prozessspezifische Abfragetypen wie lokale Unternehmens- und Produktsuchen.
Dieses Training prägt die Art und Weise, wie KI-Systeme Anfragen interpretieren und darauf reagieren, insbesondere sichtbar in:
- Lokale Geschäftsabfragen, bei denen Entitätsattribute mit strukturierten Datenmustern übereinstimmen.
- Produktabfragen, die vom Händler bereitgestellte strukturierte Daten widerspiegeln.
- Knowledge-Panel-Informationen, die mit Entitätsdefinitionen übereinstimmen.
Suchmaschinenintegration
Verschiedene Plattformen zeigen den Einfluss strukturierter Daten durch:
- Traditionelle Suche: Umfangreiche Ergebnisse und Wissenspanels, die direkt auf strukturierten Daten basieren.
- KI-Suchintegration:
- Bing Copilot zeigt verbesserte Ergebnisse für strukturierte Entitäten.
- Google Gemini spiegelt Wissensdiagramminformationen wider.
- Spezialisierte Engines wie Perplexity.ai demonstrieren das Verständnis von Entitäten bei Standortabfragen.
- Neuestes Google-Experiment eines in die SERP integrierten KI-Verkaufsassistenten für Einkaufsanfragen (Das ist riesig! Hier ist auf X, entdeckt von SERP Alert).
 WordLifts Entity Knowledge Graph Panel in der Google-Suche – Gründungsjahr. WordLifts Entity Knowledge Graph Panel in der Google-Suche – Gründungsjahr. |  Die Frage „Wann wurde WordLift gegründet?“ zu Google Gemini. Die Frage „Wann wurde WordLift gegründet?“ zu Google Gemini. |
Hier ist ein Beispiel für Zwillinge und Google-Suche das gleiche Faktoid teilen.
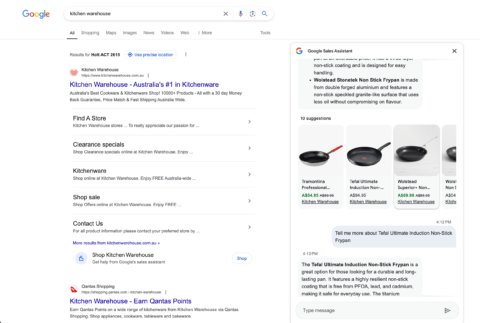 KI-Verkaufsassistent über einen „Shop“-CTA auf Marken-Sitelinks.
KI-Verkaufsassistent über einen „Shop“-CTA auf Marken-Sitelinks.Datenvalidierung und -verifizierung
Strukturierte Daten bieten Überprüfungsmechanismen durch:
- Wissensgraphen: Systeme wie Data Commons von Google nutzen strukturierte Daten zur Faktenüberprüfung.
- Trainingssets: Schema.org-Markup erstellt zuverlässige Trainingsbeispiele für die Entitätserkennung.
- Validierungspipelines: Tools zur Inhaltserstellung wie WordLift verwenden strukturierte Daten, um KI-Ausgaben zu überprüfen.
Der Hauptunterschied besteht darin, dass strukturierte Daten die LLM-Antworten nicht direkt beeinflussen, sondern KI-Suchmaschinen durch Folgendes prägen:
- Trainingsdaten, die strukturiertes Markup enthalten.
- Entitätsklassendefinitionen, die das Verständnis erleichtern.
- Integration mit herkömmlichen Rich-Suchergebnissen.
Dadurch wird die Implementierung strukturierter Daten für die Sichtbarkeit sowohl auf herkömmlichen als auch auf KI-gestützten Suchplattformen immer wichtiger.
Während wir in diese neue Ära der KI-Erkennung eintreten, geht es bei der Investition in strukturierte Daten nicht mehr nur um SEO – Es geht darum, die semantische Schicht aufzubauen, die es Maschinen ermöglicht, wirklich zu verstehen und genau darzustellen, wer Sie sind.
Semantische SEO-Evolution: Von strukturierten Daten zu semantischen Daten
Die SEO-Praxis hat sich zu semantischem SEO weiterentwickelt und geht über die traditionelle Keyword-Optimierung hinaus, um semantisches Verständnis zu umfassen:
Entitätsbasierte Optimierung
- Konzentrieren Sie sich auf klare Entitätsdefinitionen und Beziehungen.
- Implementierung umfassender Entitätsattribute.
- Strategische Verwendung von sameAs-Eigenschaften zur Entitätsdisambiguierung.
Content-Netzwerke
- Entwicklung miteinander verbundener Content-Cluster.
- Klare Namensnennung und Urheberkennzeichnung.
- Definitionen von Rich-Media-Beziehungen.
Wichtige Implementierungsmuster in JSON-LD
Inhaltsveröffentlichung
Die Analyse strukturierter Datenmuster auf Millionen von Websites zeigt drei vorherrschende Implementierungstrends für Content-Publisher.
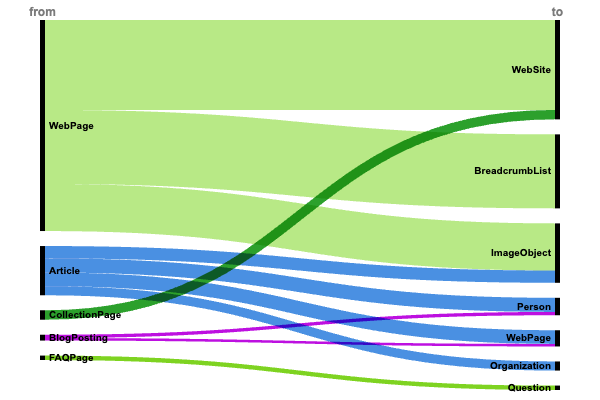 JSON-LD-Muster für Inhaltsverleger. (Bild vom Autor, November 2024)
JSON-LD-Muster für Inhaltsverleger. (Bild vom Autor, November 2024)Website-Struktur und Navigation ( 6 Millionen Implementierungen)
Die Dominanz der Beziehungen WebPage → isPartOf → WebSite (5,8 Millionen) und WebPage → Breadcrumb → BreadcrumbList (4,8 Millionen) zeigt, dass große Websites eine klare Site-Architektur und Navigationspfade priorisieren.
Die Site-Struktur bleibt die Grundlage der strukturierten Datenimplementierung, was darauf hindeutet, dass Suchmaschinen stark auf diese Signale angewiesen sind, um die Inhaltshierarchie zu verstehen.
Inhaltszuordnung und Autorität
Bei der Inhaltszuordnung zeichnen sich deutliche Muster ab:
- Artikel → Autor → Person (925.000).
- Artikel → Herausgeber → Organisation (597.000).
- BlogPosting → Autor → Person (217.000).
Dieser Fokus auf Urheberschaft und organisatorische Zuschreibung spiegelt die zunehmende Bedeutung von EEAT-Signalen und Inhaltsautorität in Suchalgorithmen wider.
Rich Media-Integration
Konsistente Implementierung von Bild-Markup über alle Inhaltstypen hinweg:
- WebPage → PrimaryImageOfPage → ImageObject (3 Millionen)
- Artikel → Bild → ImageObject (806.000)
Die hohe Häufigkeit von Medienbeziehungen zeigt, dass Verlage den Wert strukturierter visueller Inhalte sowohl für die Sichtbarkeit in der Suche als auch für das Benutzererlebnis erkennen.
Die Daten deuten darauf hin, dass Verlage über das grundlegende SEO-Markup hinausgehen und umfassende maschinenlesbare Inhaltsdiagramme erstellen, die sowohl die traditionelle Suche als auch neue KI-Erkennungssysteme unterstützen.
Lokales Geschäft und Einzelhandel
Die Analyse der Implementierung strukturierter Daten lokaler Unternehmen zeigt drei kritische Mustergruppen, die das standortbasierte Markup dominieren.
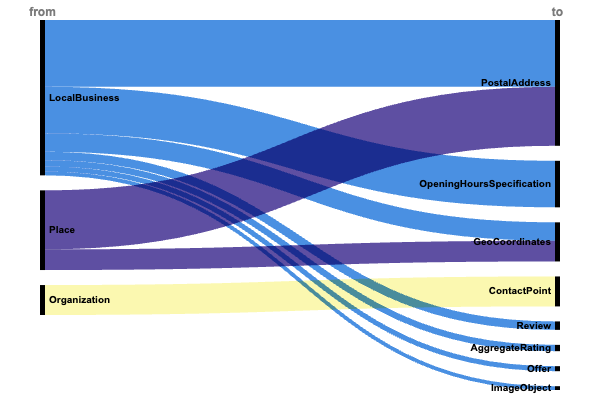 JSON-LD-Muster für lokale Unternehmen und den Einzelhandel. (Bild vom Autor, November 2024)
JSON-LD-Muster für lokale Unternehmen und den Einzelhandel. (Bild vom Autor, November 2024)Standort und Erreichbarkeit ( 1,4 Millionen Implementierungen)
Die hohe Akzeptanz physischer Standortmarkierungen zeigt deren grundlegende Bedeutung:
- LocalBusiness → Adresse → Postadresse (745.000).
- Ort → Adresse → Postadresse (658.000).
- Organisation → contactPoint → ContactPoint (334.000).
- LocalBusiness → OpeningHoursSpecification (519.000).
Die starke Präsenz dieser grundlegenden Betriebsdetails legt nahe, dass sie zentrale Ranking-Faktoren für die Sichtbarkeit in der lokalen Suche sind.
Geografische Präzision
Die aussagekräftige Implementierung von Geokoordinaten zeigt den Fokus auf den genauen Standort:
- Ort → Geo → GeoKoordinaten (231.000).
- LocalBusiness → Geo → GeoKoordinaten (205.000).
Dieser doppelte Standortansatz (Adresse Koordinaten) zeigt, dass Suchmaschinen eine präzise geografische Positionierung für die lokale Suchgenauigkeit schätzen.
Vertrauenssignale
Eine kleinere, aber bemerkenswerte Mustergruppe konzentriert sich auf die Reputation:
- LocalBusiness → Bewertung → Bewertung (94.000)
- LocalBusiness → aggregatRating → AggregateRating (70.000)
- LocalBusiness → Fotos → ImageObject (42.000)
- LocalBusiness → machtAngebot → Angebot (56.000)
Diese vertrauensbildenden Elemente werden zwar seltener implementiert, schaffen aber umfassendere lokale Geschäftseinheiten, die sowohl die Sichtbarkeit bei der Suche als auch die Entscheidungsfindung der Benutzer unterstützen.
E-Commerce (erweiterte Liste)
Die Analyse strukturierter E-Commerce-Daten zeigt ausgefeilte Implementierungsmuster, die sich auf die Produkterkennung und Conversion-Optimierung konzentrieren.
 JSON-LD-Muster für E-Commerce-Websites. (Bild vom Autor, November 2024)
JSON-LD-Muster für E-Commerce-Websites. (Bild vom Autor, November 2024)Kernproduktinformationen ( 4,7 Millionen Implementierungen)
Die Dominanz des grundlegenden Produkt-Markups zeigt seine grundlegende Bedeutung:
- Produkt → Angebote → Angebot (3,1 Millionen).
- Angebot → Verkäufer → Organisation (2,2 Millionen).
- Produkt → mainEntityOfPage → WebPage (1,5 Millionen).
Diese hohe Akzeptanzrate der Kernproduktbeziehungen zeigt, dass sie eine entscheidende Rolle bei der Produktfindung und Händlersichtbarkeit spielen.
Vertrauen und sozialer Beweis
Signifikante Implementierung von bewertungsbezogenem Markup:
- Produkt → Rezension → Rezension (490.000).
- Produkt → aggregatRating → AggregateRating (201.000).
- Rezension → RezensionBewertung → Bewertung (110.000).
Die starke Präsenz von Bewertungsmarkierungen deutet darauf hin, dass Social Proof für die E-Commerce-Konvertierung weiterhin von entscheidender Bedeutung ist.
Erweiterter Produktkontext
Die Implementierung umfassender Produktattribute zeigt einen Fokus auf detaillierte Produktinformationen:
- Produkt → Marke → Marke (315.000).
- Produkt → AdditionalProperty → PropertyValue (253.000).
- Produkt → Bild → ImageObject (182.000).
- Angebot → Versanddetails → AngebotVersanddetails (151.000).
- Angebot → Preisspezifikation → Preisspezifikation (42.000).
- AggregateOffer → Angebote → Angebot (69.000).
Dieser mehrschichtige Ansatz für Produktattribute schafft umfassende Produkteinheiten, die sowohl die Sichtbarkeit bei der Suche als auch die Entscheidungsfindung des Benutzers unterstützen.
Zukunftsausblick
Die Rolle strukturierter Daten geht über ihre traditionelle Funktion als SEO-Tool für p hinaus mit Rich Snippets und spezifischen Suchfunktionen. Im Zeitalter der KI-Erkennung werden strukturierte Daten zu einem entscheidenden Faktor für das maschinelle Verständnis und verändern die Art und Weise, wie Inhalte im Web interpretiert und verknüpft werden. Dieser Wandel treibt die Branche voran Denken Sie über die Google-zentrierte Optimierung hinauswobei strukturierte Daten als Kernkomponente eines semantischen und KI-integrierten Webs betrachtet werden.
Strukturierte Daten bilden das Gerüst für die Erstellung miteinander verbundener, maschinenlesbarer Frameworks, die für neue KI-Anwendungen wie Konversationssuche, Wissensgraphen und (Graph) Retrieval-Augmented Generation (GraphRAG oder RAG)-Systeme von entscheidender Bedeutung sind. Diese Entwicklung erfordert einen doppelten Ansatz: die Nutzung umsetzbarer Schematypen für unmittelbare SEO-Vorteile (Rich Results) und gleichzeitig die Investition in umfassende, beschreibende Schemata, die ein breiteres Datenökosystem aufbauen.
Die Zukunft liegt in der Schnittstelle zwischen strukturierten Daten, semantischer Modellierung und KI-gesteuerten Content-Discovery-Systemen. Durch die Übernahme einer ganzheitlicheren Sichtweise können Unternehmen von der Verwendung strukturierter Daten als taktische SEO-Ergänzung zur Positionierung als strategische Ebene zur Förderung von KI-Interaktionen und zur Sicherstellung der Auffindbarkeit auf verschiedenen Plattformen übergehen.
Credits und Danksagungen
Diese Analyse wäre ohne die engagierte Arbeit des HTTP-Archivteams und der Web Almanac-Mitwirkenden nicht möglich. Besonderer Dank geht an:
- Nurullah Demir für die Datenanalyse.
- James Gallagher für die Bearbeitung.
- Jarno van Driel und Ryan Levering für ihre Expertenbewertung.
- Barry Pollard dafür, dass er alles andere bestens orchestriert hat.
Das vollständige Web Almanac Structured Data-Kapitel bietet noch tiefere Einblicke in die sich entwickelnde Landschaft der strukturierten Datenimplementierung.
Auf dem Weg in eine KI-gestützte Zukunft wird die strategische Bedeutung strukturierter Daten weiter zunehmen.
Weitere Ressourcen:
- Was ist Schema-Markup und warum ist es wichtig für SEO?
- Warum es jetzt an der Zeit ist, Schema-Markup einzuführen
- SEO im Zeitalter der KI
Ausgewähltes Bild: Koto Amatsukami/Shutterstock
![SEO-Auswirkungen des KI-Modus von Google | Studie zum Benutzerverhalten im KI-Modus [Teil 2]](https://behmaster.ir/wp-content/uploads/2025/10/637921-seo-auswirkungen-des-ki-modus-von-google-studie-zum-benutzerverhalten-im-ki-modus-teil-2-260x150.png)



