Wie strukturierte Daten KI-Snippets formen und Ihre Sichtbarkeitsquote erhöhen

Wenn Konversations-KIs wie ChatGPT, Perplexity oder Google AI Mode Snippets oder Antwortzusammenfassungen generieren, schreiben sie nicht von Grund auf neu, sondern wählen aus, was Webseiten bieten, komprimieren und stellen sie neu zusammen. Wenn Ihre Inhalte nicht SEO-freundlich und indexierbar sind, gelangen sie überhaupt nicht in die generative Suche. Die Suche, wie wir sie kennen, ist heute eine Funktion der künstlichen Intelligenz.
Was aber, wenn Ihre Seite sich nicht in maschinenlesbarer Form „anbietet“? Hier kommen strukturierte Daten ins Spiel, nicht nur als SEO-Auftrag, sondern als Gerüst für die KI, um zuverlässig die „richtigen Fakten“ auszuwählen. In unserer Community herrschte einige Verwirrung, und in diesem Artikel werde ich Folgendes tun:
- Gehen Sie kontrollierte Experimente auf 97 Webseiten durch und zeigen Sie, wie strukturierte Daten die Snippet-Konsistenz und die Kontextrelevanz verbessern.
- Ordnen Sie diese Ergebnisse unserem semantischen Rahmen zu.
Viele haben mich in den letzten Monaten gefragt, ob LLMs strukturierte Daten verwenden, und ich habe immer wieder wiederholt, dass ein LLM keine strukturierten Daten verwendet, da es keinen direkten Zugriff auf das World Wide Web hat. Ein LLM verwendet Tools, um das Web zu durchsuchen und Webseiten abzurufen. Seine Tools profitieren in den meisten Fällen stark von der Indizierung strukturierter Daten.
 Bild vom Autor, Oktober 2025
Bild vom Autor, Oktober 2025In unseren ersten Ergebnissen erhöhen strukturierte Daten die Snippet-Konsistenz und verbessern die Kontextrelevanz in GPT-5. Es deutet auch auf eine Verlängerung der Wirksamkeit hin Wortlim Umschlag – Dies ist eine versteckte GPT-5-Anweisung, die entscheidet, wie viele Wörter Ihr Inhalt in einer Antwort erhält. Stellen Sie es sich als eine Quote für Ihre KI-Sichtbarkeit vor, die erweitert wird, wenn der Inhalt umfangreicher und besser typisiert ist. Sie können mehr über dieses Konzept lesen, das ich zuerst auf LinkedIn vorgestellt habe.
Warum das jetzt wichtig ist
- Wordlim-Einschränkungen: KI-Stacks arbeiten mit strengen Token-/Zeichenbudgets. Mehrdeutigkeit verschwendet Budget; getippte Fakten bewahren es.
- Begriffsklärung und Begründung: Schema.org reduziert den Suchraum des Modells („Dies ist ein Rezept/Produkt/Artikel“) und macht die Auswahl sicherer.
- Wissensgraphen (KG): Schema speist häufig KGs, die KI-Systeme bei der Beschaffung von Fakten konsultieren. Dies ist die Brücke von Webseiten zur Argumentation von Agenten.
Meine persönliche These ist, dass wir strukturierte Daten als Befehlsschicht für KI behandeln wollen. Das ist nicht der Fall „Rang für dich“, es stabilisiert, was KI über Sie sagen kann.
Experimentdesign (97 URLs)
Obwohl die Stichprobengröße klein war, wollte ich sehen, wie die Abrufschicht von ChatGPT tatsächlich funktioniert, wenn sie über die eigene Schnittstelle und nicht über die API verwendet wird. Zu diesem Zweck habe ich GPT-5 gebeten, eine Reihe von URLs von verschiedenen Arten von Websites zu durchsuchen und zu öffnen und die Rohantworten zurückzugeben.
Sie können GPT-5 (oder ein beliebiges KI-System) mithilfe einer einfachen Meta-Eingabeaufforderung dazu auffordern, die wörtliche Ausgabe seiner internen Tools anzuzeigen. Nachdem ich sowohl die Such- als auch die Abrufantworten für jede URL gesammelt hatte, führte ich einen Agent WordLift-Workflow aus [disclaimer, our AI SEO Agent] um jede Seite zu analysieren, zu prüfen, ob sie strukturierte Daten enthält und, wenn ja, die spezifischen erkannten Schematypen zu identifizieren.
Durch diese beiden Schritte wurde ein Datensatz mit 97 URLs erstellt, der mit Schlüsselfeldern versehen war:
- has_sd → Wahr/Falsch-Flag für strukturierte Datenpräsenz.
- schema_classes → der erkannte Typ (z. B. Rezept, Produkt, Artikel).
- search_raw → das Snippet im „Suchstil“, das darstellt, was das KI-Suchtool angezeigt hat.
- open_raw → eine Fetcher-Zusammenfassung oder ein struktureller Überblick über die Seite durch GPT-5.
Mithilfe eines „LLM-as-a-Judge“-Ansatzes, der auf Gemini 2.5 Pro basiert, habe ich dann den Datensatz analysiert, um drei Hauptmetriken zu extrahieren:
- Konsistenz: Verteilung der Search_raw-Snippet-Längen (Boxplot).
- Kontextbezogene Relevanz: Schlüsselwort- und Feldabdeckung in open_raw nach Seitentyp (Rezept, E-Kommunikation, Artikel).
- Qualitätsfaktor: ein konservativer 0–1-Index, der das Vorhandensein von Schlüsselwörtern, grundlegende NER-Hinweise (für E-Commerce) und Schema-Echos in der Suchausgabe kombiniert.
Die versteckte Quote: Auspacken“Wortlim”
Während ich diese Tests durchführte, fiel mir ein weiteres subtiles Muster auf, das erklären könnte, warum strukturierte Daten zu konsistenteren und vollständigeren Snippets führen. In der Abrufpipeline von GPT-5 gibt es eine interne Anweisung, die informell als „wordlim“ bekannt ist: eine dynamische Quote, die bestimmt, wie viel Text von einer einzelnen Webseite in eine generierte Antwort gelangen kann.
Auf den ersten Blick wirkt es wie eine Wortbegrenzung, ist aber anpassungsfähig. Je reichhaltiger und besser typisiert der Inhalt einer Seite ist, desto mehr Platz erhält sie im Synthesefenster des Modells.
Aus meinen laufenden Beobachtungen:
- Unstrukturierter Inhalt (z. B. ein Standard-Blogbeitrag) hat in der Regel etwa 200 Wörter.
- Strukturierter Inhalt (z. B. Produkt-Markup, Feeds) umfasst etwa 500 Wörter.
- Umfangreiche, maßgebliche Quellen (APIs, Forschungsarbeiten) können mehr als 1.000 Wörter umfassen.
Das ist nicht willkürlich. Das Limit hilft KI-Systemen:
- Fördern Sie die quellenübergreifende Synthese statt Copy-Paste.
- Vermeiden Sie Urheberrechtsprobleme.
- Halten Sie die Antworten prägnant und lesbar.
Doch es eröffnet auch eine neue SEO-Grenze: Ihre strukturierten Daten erhöhen effektiv Ihre Sichtbarkeitsquote. Wenn Ihre Daten nicht strukturiert sind, sind Sie auf das Minimum begrenzt; Wenn dies der Fall ist, gewähren Sie der KI mehr Vertrauen und mehr Raum für die Präsentation Ihrer Marke.
Obwohl der Datensatz noch nicht groß genug ist, um in allen Branchen statistisch signifikant zu sein, sind die ersten Muster bereits klar – und umsetzbar.
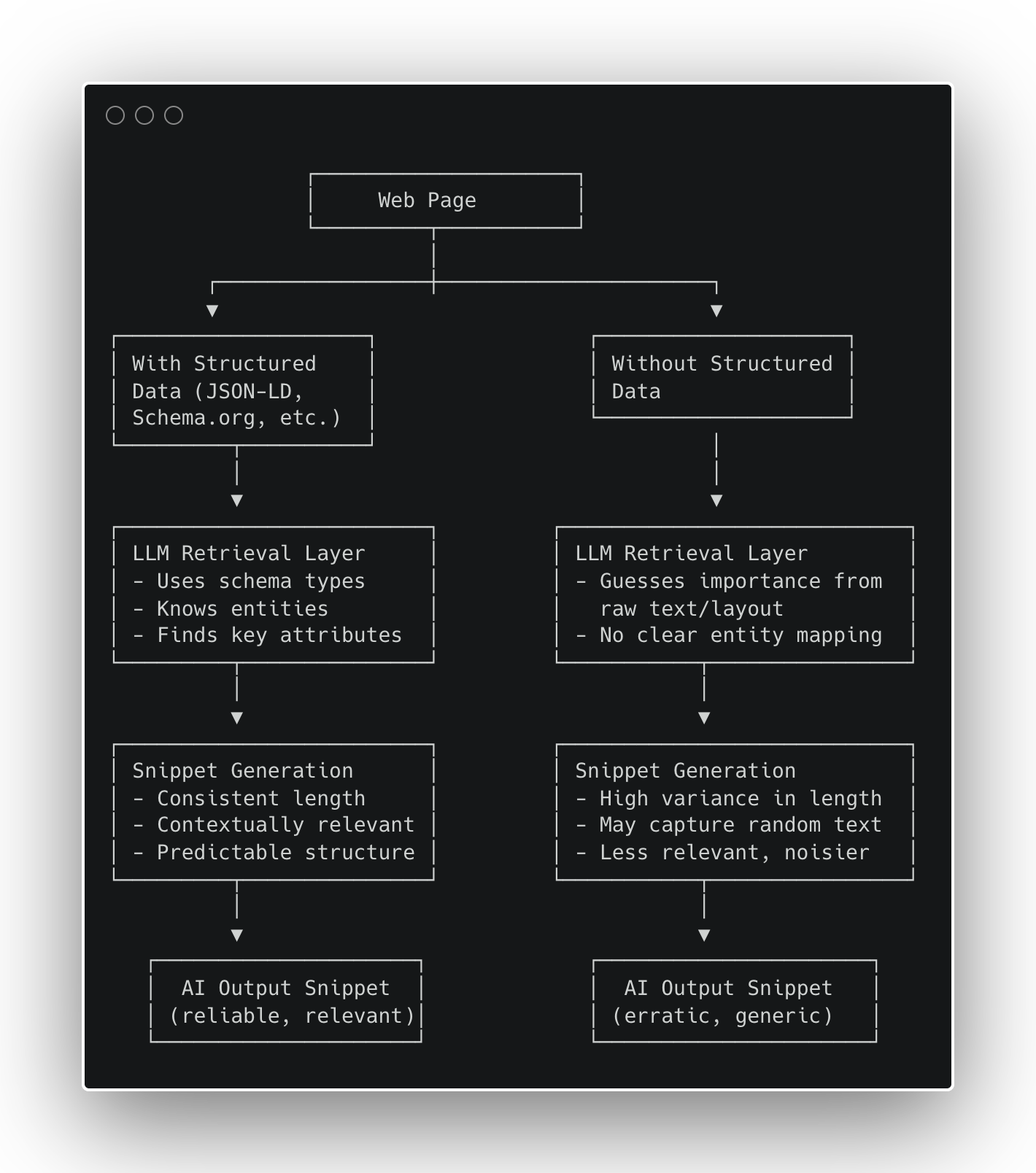 Abbildung 1 – Wie sich strukturierte Daten auf die Generierung von KI-Snippets auswirken (Bild vom Autor, Oktober 2025)
Abbildung 1 – Wie sich strukturierte Daten auf die Generierung von KI-Snippets auswirken (Bild vom Autor, Oktober 2025)Ergebnisse
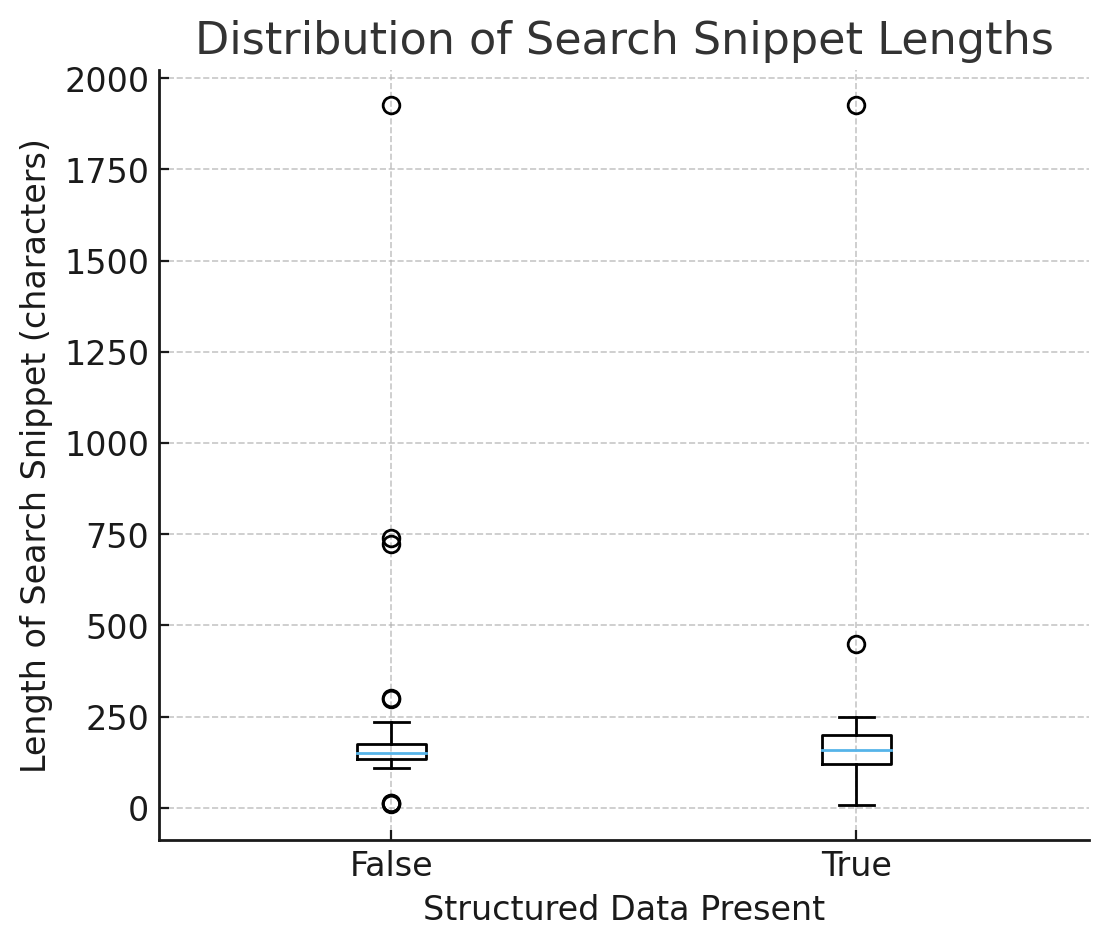 Abbildung 2 – Verteilung der Such-Snippet-Längen (Bild vom Autor, Oktober 2025)
Abbildung 2 – Verteilung der Such-Snippet-Längen (Bild vom Autor, Oktober 2025)1) Konsistenz: Snippets sind mit Schema besser vorhersehbar
Im Boxplot der Such-Snippet-Längen (mit vs. ohne strukturierte Daten):
- Die Mediane sind ähnlich → das Schema macht Snippets im Durchschnitt nicht länger/kürzer.
- Der Spread (IQR und Whiskers) ist enger, wenn has_sd = True → weniger unregelmäßige Ausgabe, vorhersehbarere Zusammenfassungen.
Interpretation: Strukturierte Daten erhöhen die Länge nicht; es verringert die Unsicherheit. Modelle verwenden standardmäßig getippte, sichere Fakten, anstatt sie anhand von beliebigem HTML zu erraten.
2) Kontextrelevanz: Schema-Guides-Extraktion
- Rezepte: Mit Rezept Schema, Fetch-Zusammenfassungen enthalten weitaus wahrscheinlicher Zutaten und Schritte. Klarer, messbarer Lift.
- E-Commerce: Das Suchtool gibt häufig JSON-LD-Felder wieder (z. B. Gesamtbewertung, Angebot, Marke) Beweise dafür, dass das Schema gelesen und angezeigt wird. Bei Abrufzusammenfassungen geht es eher um genaue Produktnamen als um generische Begriffe wie „Preis“, aber die Identitätsverankerung ist mit Schemata stärker.
- Artikel: Kleine, aber aktuelle Gewinne (Autor/Datum/Überschrift erscheinen eher).
3) Qualitätsfaktor (alle Seiten)
Durchschnitt der 0–1-Punktzahl über alle Seiten:
- Kein Schema → ~0,00
- Mit Schema → positiver Aufschwung, hauptsächlich angetrieben durch Rezepte und einige Artikel.
Selbst wenn die Mittelwerte ähnlich aussehen, kollabiert die Varianz mit dem Schema. In einer KI-Welt, die durch eingeschränkt wird Wortlim und Abrufaufwand ist eine geringe Varianz ein Wettbewerbsvorteil.
Über die Konsistenz hinaus: Umfangreichere Daten erweitern den Wordlim-Umschlag (frühes Signal)
Obwohl der Datensatz noch nicht groß genug für Signifikanztests ist, haben wir dieses sich abzeichnende Muster beobachtet:
Seiten mit umfangreicheren, aus mehreren Einheiten strukturierten Daten ergeben vor dem Abschneiden tendenziell etwas längere, dichtere Snippets.
Hypothese: Typisierte, miteinander verknüpfte Fakten (z. B. Produkt Angebot Marke Gesamtbewertung oder Artikel Autor Veröffentlichungsdatum) helfen Modellen dabei, höherwertige Informationen zu priorisieren und zu komprimieren und so das nutzbare Token-Budget für diese Seite effektiv zu erweitern.
Seiten ohne Schema werden häufiger vorzeitig abgeschnitten, wahrscheinlich aufgrund von Unsicherheit über die Relevanz.
Nächster Schritt: Wir messen die Beziehung zwischen semantischem Reichtum (Anzahl unterschiedlicher Schema.org-Entitäten/Attribute) und effektiver Snippet-Länge. Wenn dies bestätigt wird, stabilisieren strukturierte Daten nicht nur Snippets, sondern erhöhen auch den Informationsdurchsatz bei konstanten Wortbeschränkungen.
Vom Schema zur Strategie: Das Playbook
Wir strukturieren Websites wie folgt:
- Entitätsdiagramm (Schema/GS1/Artikel/ …): Produkte, Angebote, Kategorien, Kompatibilität, Standorte, Richtlinien;
- Lexikalischer Graph: Geblockte Kopien (Pflegehinweise, Größenanleitungen, FAQs), die mit den Entitäten verknüpft sind.
Warum es funktioniert: Die Entitätsschicht bietet der KI ein sicheres Gerüst; Die lexikalische Ebene liefert wiederverwendbare, zitierfähige Beweise. Gemeinsam treiben sie Präzision unter die LupeWortlim Einschränkungen.
So übersetzen wir diese Erkenntnisse in ein wiederholbares SEO-Playbook für Marken, die unter Einschränkungen bei der KI-Erkennung arbeiten.
- Versenden Sie JSON-LD für Kernvorlagen
- Rezepte → Rezept (Zutaten, Anweisungen, Erträge, Zeiten).
- Produkte → Produkt Angebot (Marke, GTIN/SKU, Preis, Verfügbarkeit, Bewertungen).
- Artikel → Artikel/NewsArtikel (Überschrift, Autor, Datum der Veröffentlichung).
- Entität Lexikon vereinen
Halten Sie Spezifikationen, FAQs und Richtlinientexte gegliedert und mit Entitäten verknüpft. - Schnipseloberfläche härten
Fakten müssen in sichtbarem HTML und JSON-LD konsistent sein; Halten Sie kritische Fakten über der Falte und stabil. - Instrument
Verfolgen Sie die Varianz, nicht nur Durchschnittswerte. Vergleichen Sie die Schlüsselwort-/Feldabdeckung in Maschinenzusammenfassungen anhand einer Vorlage.
Abschluss
Strukturierte Daten ändern nichts an der durchschnittlichen Größe von KI-Snippets; es verändert ihre Sicherheit. Es stabilisiert Zusammenfassungen und prägt deren Inhalt. Bei GPT-5 besonders unter aggressiven Bedingungen Wortlim Unter bestimmten Bedingungen führt diese Zuverlässigkeit zu qualitativ hochwertigeren Antworten, weniger Halluzinationen und einer größeren Markensichtbarkeit in KI-generierten Ergebnissen.
Für SEOs und Produktteams ist die Erkenntnis klar: Behandeln Sie strukturierte Daten als Kerninfrastruktur. Wenn Ihren Vorlagen immer noch eine solide HTML-Semantik fehlt, Springen Sie nicht direkt zu JSON-LD: Zuerst die Fundamente reparieren. Beginnen Sie mit der Bereinigung Ihres Markups und legen Sie dann strukturierte Daten darüber, um semantische Genauigkeit und langfristige Auffindbarkeit zu erreichen. Bei der KI-Suche ist die Semantik der neue Oberflächenbereich.
Weitere Ressourcen:
- KI-Suchoptimierung: Machen Sie Ihre strukturierten Daten zugänglich
- CMO-Leitfaden zum Schema: Wie Ihr Unternehmen eine strukturierte Datenstrategie umsetzen kann
- SEO im Zeitalter der KI
Ausgewähltes Bild: TierneyMJ/Shutterstock
![SEO-Auswirkungen des KI-Modus von Google | Studie zum Benutzerverhalten im KI-Modus [Teil 2]](https://behmaster.ir/wp-content/uploads/2025/10/637921-seo-auswirkungen-des-ki-modus-von-google-studie-zum-benutzerverhalten-im-ki-modus-teil-2-260x150.png)



