Wir stellen vor: SEOntology: Die Zukunft der SEO im Zeitalter der künstlichen Intelligenz

Es wurde viel über die bemerkenswerten Möglichkeiten der Generativen KI (GenAI) gesagt, und einige von uns haben sich auch sehr deutlich zu den Risiken geäußert, die mit der Nutzung dieser transformativen Technologie verbunden sind.
Der Aufstieg der GenAI stellt erhebliche Herausforderungen für die Qualität von Informationen, den öffentlichen Diskurs und das offene Internet im Allgemeinen dar. Die Fähigkeit der GenAI, Inhalte vorherzusagen und zu personalisieren, kann leicht missbraucht werden, um zu manipulieren, was wir sehen und womit wir interagieren.
Wie die SEO-Branche generative KI nutzen und verbessern kann
Suchmaschinen mit generativer KI tragen zum allgemeinen Chaos bei, und anstatt den Menschen dabei zu helfen, die Wahrheit zu finden und sich eine unvoreingenommene Meinung zu bilden, neigen sie (zumindest in ihrer gegenwärtigen Implementierung) dazu, Effizienz über Genauigkeit zu stellen, wie eine aktuelle Studie von Jigsaw, einer Tochtergesellschaft von Google, zeigt.
Trotz des Hypes um SEO-Alligator-Partys und Content-Kobolde hat unsere Generation von Vermarktern und SEO-Experten jahrelang auf eine positivere Webumgebung hingearbeitet.
Wir haben den Marketingschwerpunkt von der Manipulation des Publikums auf die Vermittlung von Wissen verlagert, um den Beteiligten letztlich dabei zu helfen, fundierte Entscheidungen zu treffen.
Die Erstellung einer Ontologie für SEO ist ein Community-geführtes Unterfangen, das perfekt zu unserer laufenden Mission passt, die Interaktion zwischen Mensch und GenKI zu gestalten, zu verbessern und Richtungen vorzugeben, die sie wirklich voranbringen und gleichzeitig die Ersteller von Inhalten und das Internet als gemeinsame Ressource für Wissen und Wohlstand bewahren.
Ein kurzer Überblick über traditionelle SEO-Praktiken und ihre Entwicklung
Traditionelle SEO-Praktiken in den frühen 2010er Jahren konzentrierten sich stark auf die Keyword-Optimierung. Dazu gehörten Taktiken wie Keyword-Stuffing, Link-Schemata und die Erstellung von minderwertigem Inhalt, der in erster Linie für Suchmaschinen bestimmt war.
Seitdem hat sich SEO zu einem benutzerzentrierteren Ansatz entwickelt. Das Hummingbird-Update (2013) markierte Googles Übergang zur semantischen Suche, die darauf abzielt, den Kontext und die Absicht hinter Suchanfragen zu verstehen und nicht nur die Schlüsselwörter.
Diese Entwicklung hat dazu geführt, dass SEO-Profis ihren Schwerpunkt mehr auf Themencluster und -entitäten als auf einzelne Schlüsselwörter legen. Dadurch können Inhalte besser auf mehrere Benutzeranfragen antworten.
Entitäten sind eindeutige Elemente wie Personen, Orte oder Dinge, die von Suchmaschinen als einzelne Konzepte erkannt und verstanden werden.
Durch die Erstellung von Inhalten, die diese Entitäten klar definieren und sich auf sie beziehen, können Unternehmen ihre Sichtbarkeit auf verschiedenen Plattformen verbessern, nicht nur bei herkömmlichen Websuchen.
Dieser Ansatz knüpft an das umfassendere Konzept der entitätsbasierten SEO an, das sicherstellt, dass die mit einem Unternehmen verbundene Entität im gesamten Web klar definiert ist.
Von statischen Inhalten zu semantischen Daten
Heute werden statische Inhalte, die ein gutes Ranking in den Suchmaschinen erzielen sollen, ständig transformiert und mit semantischen Daten angereichert.
Dabei geht es darum, Informationen so zu strukturieren, dass sie nicht nur für Menschen, sondern auch für Maschinen verständlich sind.
Dieser Übergang ist von entscheidender Bedeutung für die Bereitstellung von Knowledge Graphs und KI-generierten Antworten, wie sie beispielsweise von Google AIO oder Bing Copilot angeboten werden und den Benutzern direkte Antworten und Links zu relevanten Websites liefern.
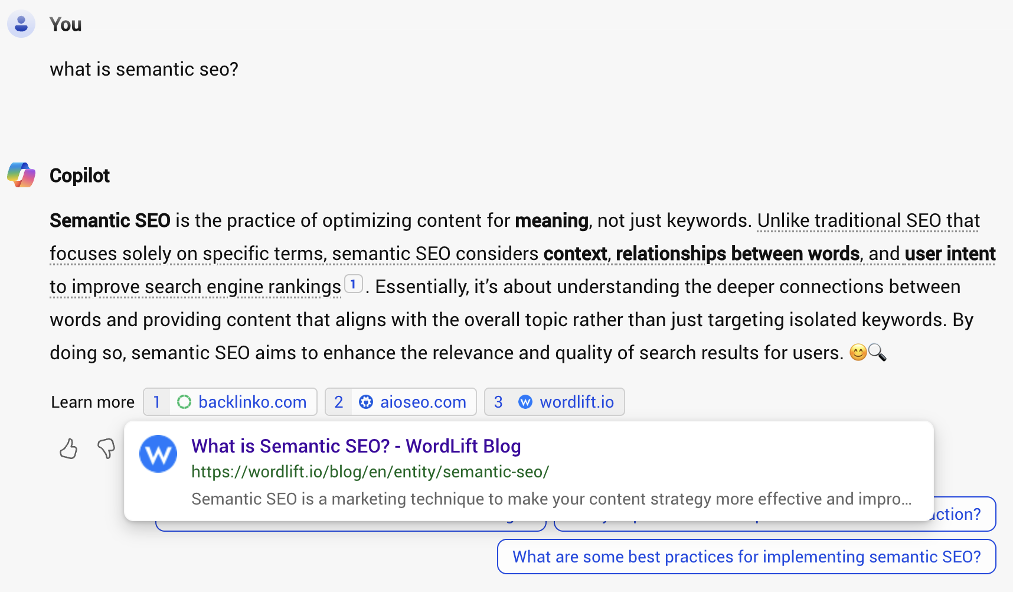 Screenshot von Bing Copilot, August 2024
Screenshot von Bing Copilot, August 2024Je weiter wir voranschreiten, desto wichtiger wird es, Inhalte mithilfe der semantischen Suche und des Entitätsverständnisses abzustimmen.
Unternehmen werden ermutigt, ihre Inhalte so zu strukturieren, dass sie für Suchmaschinen leicht verständlich und indizierbar sind. Auf diese Weise wird die Sichtbarkeit über mehrere digitale Oberflächen hinweg, wie etwa bei der Sprach- und visuellen Suche, verbessert.
Der Einsatz von KI und Automatisierung in diesen Prozessen nimmt zu und ermöglicht dynamischere Interaktionen mit Inhalten und personalisierte Benutzererlebnisse.
Ob es uns gefällt oder nicht, KI wird uns helfen, Optionen schneller zu vergleichen, mühelos tiefgehende Suchvorgänge durchzuführen und Transaktionen durchzuführen ohne über eine Website zu gehen.
Automatisierung und KI in der SEO
Die Zukunft von SEO ist vielversprechend. Der Markt für SEO-Dienstleistungen wird voraussichtlich von 75,13 Milliarden US-Dollar im Jahr 2023 auf 88,91 Milliarden US-Dollar im Jahr 2024 wachsen – eine atemberaubende durchschnittliche jährliche Wachstumsrate von 18,3 % (laut The Business Research Company) –, da er sich an die Integration zuverlässiger KI- und semantischer Technologien anpasst.
Diese Innovationen unterstützen die Schaffung dynamischerer und reaktionsschnellerer Webumgebungen, die den Bedürfnissen und Verhaltensweisen der Benutzer optimal gerecht werden.
Allerdings verlief der Weg nicht ohne Herausforderungen, insbesondere in großen Unternehmen. Die Implementierung von KI-Lösungen, die sowohl erklärbar als auch strategisch auf die Unternehmensziele ausgerichtet sind, war eine komplexe Aufgabe.
Der Aufbau einer effektiven KI beinhaltet die Zusammenführung relevanter Daten und deren Umwandlung in umsetzbares Wissen.
Dadurch kann sich ein Unternehmen von seinen Konkurrenten unterscheiden, die ähnliche Sprachmodelle oder Entwicklungsmuster verwenden, wie etwa Konversationsagenten oder durch Abruf erweiterte Generation-Copiloten, und steigert so sein einzigartiges Wertangebot.
Einführung in die SEOntologie und ihre Bedeutung in der aktuellen digitalen Landschaft
Was ist eine Ontologie für SEO in Laiensprache?
Stellen Sie sich eine Ontologie als eine riesige Bedienungsanleitung zur Beschreibung bestimmter Konzepte vor. In der SEO-Welt haben wir es mit viel Fachjargon zu tun, nicht wahr? Aktualität, Backlinks, EEAT, strukturierte Daten – das kann verwirrend sein!
Eine Ontologie für SEO ist eine große Vereinbarung darüber, was all diese Begriffe bedeuten. Es ist wie ein gemeinsames Wörterbuch, aber noch besser. Dieses Wörterbuch definiert nicht nur jedes Wort. Es zeigt auch, wie sie alle miteinander verbunden sind und zusammenwirken. So können „Abfragen“ mit „Suchabsicht“ und „Webseiten“ verknüpft werden, was erklärt, welche Rolle sie alle in einer erfolgreichen SEO-Strategie spielen.
Stellen Sie es sich so vor, als würden Sie einen großen Knoten aus SEO-Praktiken und -Begriffen entwirren und diese in eine klare, geordnete Karte verwandeln – das ist die Macht der Ontologie!
Schema.org ist zwar ein hervorragendes Beispiel für ein verknüpftes Vokabular, konzentriert sich jedoch auf die Definition bestimmter Attribute einer Webseite, wie Inhaltstyp oder Autor. Es hilft Suchmaschinen hervorragend dabei, unsere Inhalte zu verstehen. Aber wie steht es mit der Art und Weise, wie wir Links zwischen Webseiten erstellen?
Was ist mit der Abfrage, nach der eine Webseite am häufigsten gesucht wird? Dies sind entscheidende Elemente unserer täglichen Arbeit, und eine Ontologie kann auch dafür ein gemeinsamer Rahmen sein. Betrachten Sie es als einen Spielplatz, auf dem jeder willkommen ist, auf GitHub Beiträge zu leisten, ähnlich wie sich das Vokabular von Schema.org weiterentwickelt.
Die Idee einer Ontologie für SEO besteht darin, Schema.org mit einer Erweiterung zu erweitern, ähnlich wie GS1 es mit seinem Vokabular getan hat. Ist es also eine Datenbank? Ein Rahmenwerk für die Zusammenarbeit oder was? Es ist all das zusammen. Die SEO-Ontologie funktioniert wie ein kollaborative Wissensdatenbank.
Es fungiert als zentraler Knotenpunkt, an dem jeder sein Fachwissen einbringen kann, um wichtige SEO-Konzepte und deren Zusammenhänge zu definieren. Durch die Schaffung eines gemeinsamen Verständnisses dieser Konzepte spielt die SEO-Community eine entscheidende Rolle bei Gestaltung der Zukunft menschenzentrierter KI-Erlebnisse.
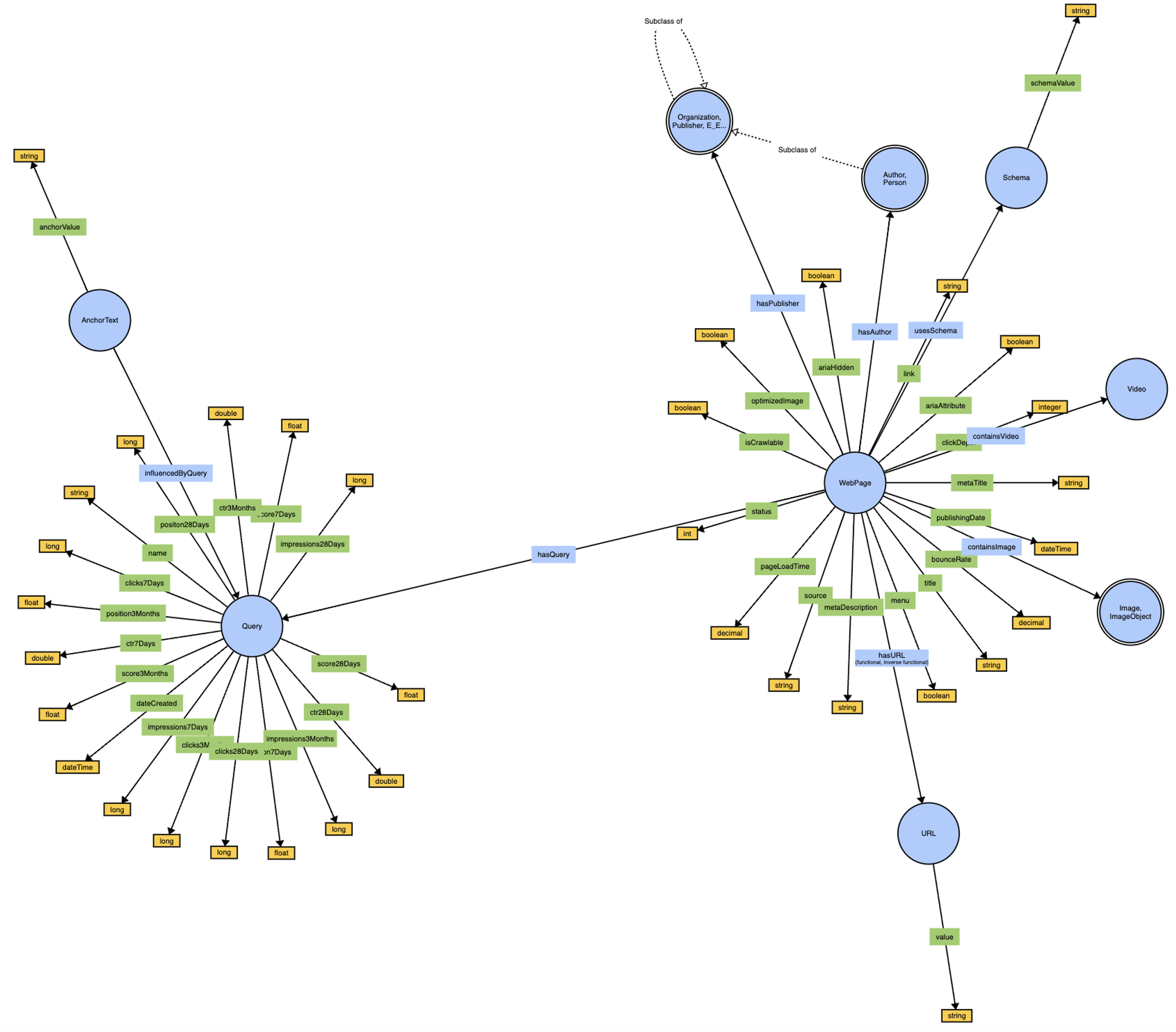
Screenshot von WebVowl, August 2024SEOntology – eine Momentaufnahme (eine interaktive Visualisierung finden Sie hier).
Die Herausforderung der Dateninteroperabilität in der SEO-Branche
Beginnen wir im Kleinen und betrachten die Vorteile einer gemeinsamen Ontologie anhand eines praktischen Beispiels (hier ist eine Folie aus der Präsentation von Emilija Gjorgjevska beim diesjährigen ZagrebSEOSummit).
 Bild von Emilija Gjorgjevskas, ZagrebSEOSummit, August 2024
Bild von Emilija Gjorgjevskas, ZagrebSEOSummit, August 2024Stellen Sie sich vor, Ihre Kollegin Valentina verwendet eine Chrome-Erweiterung, um Daten aus der Google Search Console (GSC) in Google Sheets zu exportieren. Die Daten enthalten Spalten wie „ID“, „Query“ und „Impressionen“ (siehe links). Aber Valentina arbeitet mit Jan zusammen, der eine Business-Ebene mit denselben GSC-Daten erstellt. Und hier liegt das Problem: Jan verwendet eine andere Namenskonvention („UID“, „Name“, „Impressionen“ und „Klicks“).
Nun skalieren Sie dieses Szenario hoch. Stellen Sie sich vor, Sie arbeiten mit N verschiedene Datenpartner, Tools und Teammitglieder, die alle unterschiedliche Sprachen verwenden. Der Aufwand, diese unterschiedlichen Namenskonventionen ständig zu übersetzen und abzustimmen, wird zu einem großen Hindernis für eine effektive Datenzusammenarbeit.
Beim Versuch, alles zusammenarbeiten zu lassen, geht ein erheblicher Mehrwert verloren. Hier kommt eine SEO-Ontologie ins Spiel. Sie ist eine gemeinsame Sprache, die für dasselbe Konzept über verschiedene Tools, Partner und Sprachen hinweg einen gemeinsamen Namen bietet.
Da ständige Übersetzungen und Abstimmungen nicht mehr erforderlich sind, vereinfacht eine SEO-Ontologie die Datenzusammenarbeit und erschließt den wahren Wert Ihrer Daten.
Die Entstehung der SEOntologie
Im letzten Jahr waren wir Zeugen der zunehmenden Verbreitung von KI-Agenten und der breiten Akzeptanz von Retrieval Augmented Generation (RAG) in all seinen verschiedenen Formen (Modular, Graph RAG usw.).
RAG stellt einen wichtigen Fortschritt in der KI-Technologie dar und behebt eine wesentliche Einschränkung herkömmlicher großer Sprachmodelle (LLMs), indem es ihnen den Zugriff auf externes Wissen ermöglicht.
Traditionell sind LLMs wie Bibliotheken mit einem Buch – begrenzt durch ihre Trainingsdaten. RAG erschließt ein riesiges Netzwerk an Ressourcen, sodass LLMs umfassendere und genauere Antworten liefern können.
RAGs verbessern die sachliche Genauigkeit und das Kontextverständnis und können so Verzerrungen reduzieren. Obwohl RAGs vielversprechend sind, gibt es vor allem im Unternehmenssektor Herausforderungen in Bezug auf Datensicherheit, Genauigkeit, Skalierbarkeit und Integration.
Für eine erfolgreiche Umsetzung benötigt die RAG hochwertige, strukturierte Daten die leicht zugänglich und skalierbar sind.
Wir gehörten zu den Ersten, die im Kontext der Inhaltserstellung und SEO-Automatisierung mit KI-Agenten und RAG auf Basis des Knowledge Graph experimentierten.
 Screenshot von Agent WordLift, August 2023
Screenshot von Agent WordLift, August 2023Wissensgraphen (KGs) gewinnen in der RAG-Entwicklung tatsächlich an Bedeutung
GraphRAG von Microsoft und Lösungen wie LlamaIndex sind ein Beispiel dafür. Baseline RAG hat Probleme, Informationen aus unterschiedlichen Quellen zu verknüpfen, und behindert so Aufgaben, die ein ganzheitliches Verständnis großer Datensätze erfordern.
KG-gestützte RAG-Ansätze wie der von LlamaIndex in Verbindung mit WordLift angebotene gehen auf dieses Problem ein, indem sie aus Website-Daten einen Wissensgraphen erstellen und diesen zusammen mit dem LLM verwenden, um die Antwortgenauigkeit, insbesondere bei komplexen Fragen, zu verbessern.
 Bild vom Autor, August 2024
Bild vom Autor, August 2024Wir haben über ein Jahr lang Arbeitsabläufe mit Kunden aus unterschiedlichen Branchen getestet.
Von der Keyword-Recherche für große Redaktionsteams bis hin zur Erstellung von Fragen und Antworten für E-Commerce-Websites, vom Content Bucketing bis hin zum Entwurf der Gliederung eines Newsletters oder der Überarbeitung bestehender Artikel haben wir verschiedene Strategien getestet und dabei einiges gelernt:
1. RAG wird überbewertet
Es ist einfach eines von vielen Entwicklungsmustern, die das Ziel höherer Komplexität erreichen. Ein RAG (oder Graph RAG) soll Ihnen helfen, Zeit bei der Suche nach einer Antwort zu sparen. Es ist brillant, löst aber keine Marketingaufgaben, die ein Team täglich bewältigen muss. Sie müssen sich auf die Daten und das Datenmodell konzentrieren.
Es gibt zwar gute und schlechte RAGs, aber der entscheidende Unterschied besteht oft im „R“-Teil der Gleichung: dem Abruf. In erster Linie unterscheidet der Abruf eine schicke Demo von einer realen Anwendung, und hinter einem guten RAG stehen immer gute Daten. Daten sind jedoch nicht einfach nur Daten (oder Grafikdaten).
Es basiert auf einem kohärenten Datenmodell, das für Ihren Anwendungsfall sinnvoll ist. Wenn Sie eine Suchmaschine für Weine erstellen, müssen Sie den besten Datensatz erhalten und die Daten anhand der Funktionen modellieren, auf die sich ein Benutzer bei der Suche nach Informationen verlässt.
Daten sind also wichtig, aber das Datenmodell ist noch wichtiger. Wenn Sie einen KI-Agenten erstellen, der Dinge in Ihrem Marketing-Ökosystem erledigen muss, Sie müssen die Daten entsprechend modellierenSie möchten die Essenz von Webseiten und Inhaltsressourcen darstellen.
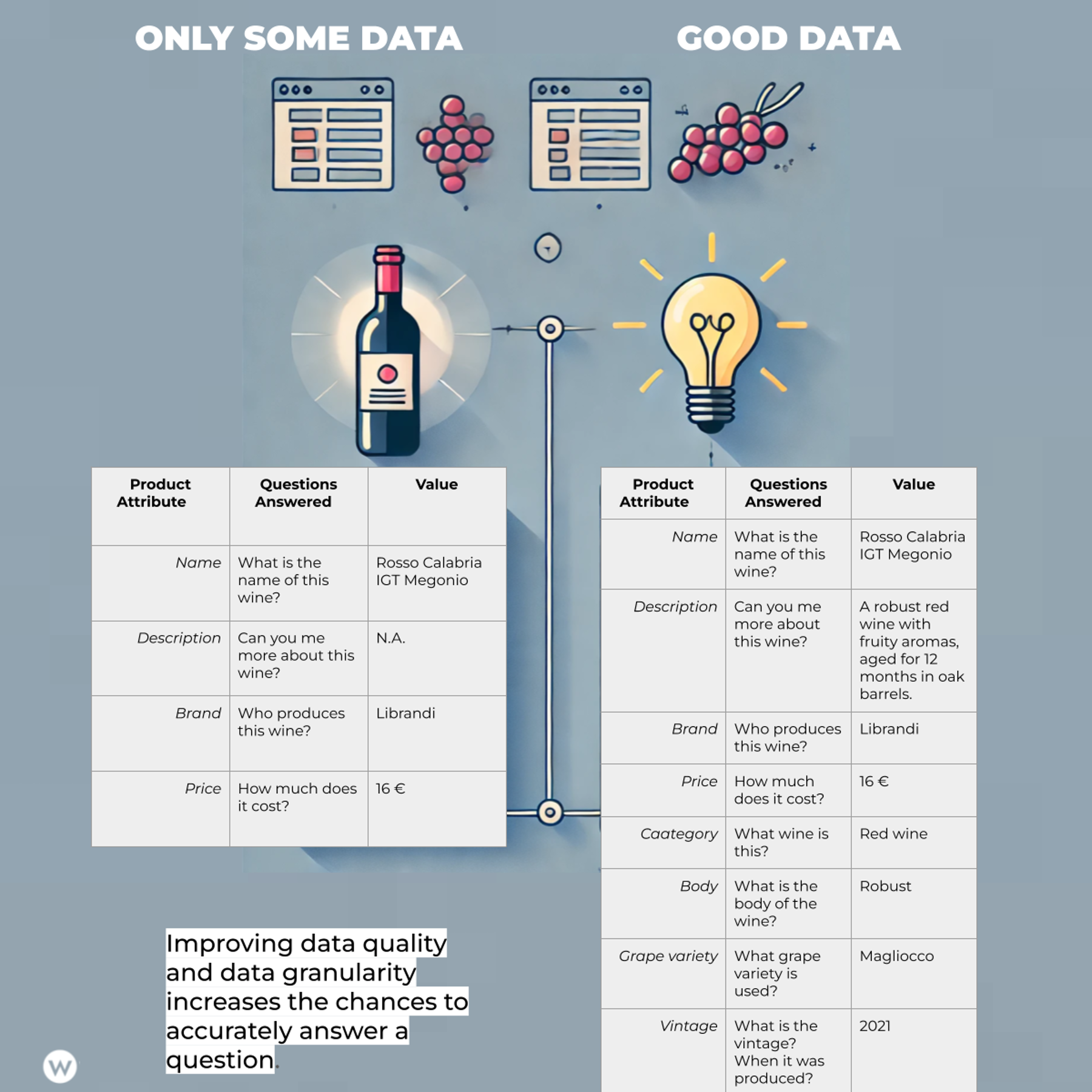 Bild vom Autor, August 2024
Bild vom Autor, August 20242. Nicht jeder ist gut im Auffordern
Eine Aufgabe schriftlich auszudrücken ist schwierig. Prompt Engineering bewegt sich mit Volldampf in Richtung Automatisierung (hier ist mein Artikel über den Übergang von Prompt zu Prompt-Programmierung für r SEO), da nur wenige Experten die Eingabeaufforderung schreiben können, die uns zum erwarteten Ergebnis führt.
Dies stellt mehrere Herausforderungen für die Gestaltung der Benutzererfahrung autonomer Agenten dar. Jakon Nielsen hat sich sehr deutlich zu den negativen Auswirkungen von Eingabeaufforderungen auf die Benutzerfreundlichkeit von KI-Anwendungen geäußert:
„Ein großer Nachteil bei der Benutzerfreundlichkeit besteht darin, dass Benutzer sehr wortgewandt sein müssen, um den erforderlichen Prosatext für die Eingabeaufforderungen zu schreiben.“
Sogar in den reichen westlichen Ländern zeigen Statistiken von Nielsen, dass nur 10 % der Bevölkerung können KI voll nutzen!
| Einfache Eingabeaufforderung mithilfe einer Gedankenkette (CoT) | Anspruchsvollere Eingabeaufforderung durch Kombination von Graph-of-Thought (GoT) und Chain-of-Knowledge (CoK) |
| „Erklären Sie Schritt für Schritt, wie man die Fläche eines Kreises mit einem Radius von 5 Einheiten berechnet.“ | „Geben Sie mithilfe der Techniken Graph-of-Thought (GoT) und Chain-of-Knowledge (CoK) eine umfassende Erklärung zur Berechnung der Fläche eines Kreises mit einem Radius von 5 Einheiten. Ihre Antwort sollte: Beginnen Sie mit einem GoT-Diagramm, das die wichtigsten Konzepte und ihre Beziehungen visuell darstellt, einschließlich: Kreis Radius Fläche Pi (π) Formel für Kreisfläche Folgen Sie dem GoT-Diagramm mit einer CoK-Aufschlüsselung, die: a) jedes Konzept im Diagramm definiert b) die Beziehungen zwischen diesen Konzepten erklärt c) den historischen Kontext für die Entwicklung der Kreisflächenformel bietet Präsentieren Sie einen schrittweisen Berechnungsprozess, einschließlich: a) Angabe der Formel für die Fläche eines Kreises b) Erklärung der Rolle jeder Komponente in der Formel c) Anzeige der Ersetzung von Werten d) Durchführen der Berechnung e) Runden des Ergebnisses auf eine entsprechende Anzahl Dezimalstellen Schließen Sie mit praktischen Anwendungen dieser Berechnung in realen Szenarien ab. Stellen Sie während Ihrer Erklärung sicher, dass jeder Schritt logisch auf den vorherigen folgt, sodass eine klare Argumentationskette von den grundlegenden Konzepten bis zum Endergebnis entsteht.“ Diese verbesserte Eingabeaufforderung bezieht GoT ein, indem sie eine visuelle Darstellung der Konzepte und ihrer Beziehungen verlangt. Sie verwendet auch CoK, indem sie nach Definitionen, historischem Kontext und Verbindungen zwischen Ideen fragt. Die schrittweise Aufschlüsselung und die realen Anwendungen verbessern die Tiefe und Praktikabilität der Erklärung noch weiter.“ |
3. Sie müssen Workflows erstellen, um den Benutzer anzuleiten
Die Lektion ist, dass wir detaillierte Standardarbeitsanweisungen (SOP) und schriftliche Protokolle, die die Schritte und Prozesse beschreiben, um Konsistenz, Qualität und Effizienz bei der Ausführung bestimmter Optimierungsaufgaben sicherzustellen.
Wir können empirische Beweise für den Aufstieg von Prompt-Bibliotheken sehen, wie sie den Benutzern anthropischer Modelle angeboten wird, oder für den unglaublichen Erfolg von Projekten wie AIPRM.
In der Praxis haben wir gelernt, dass der geschäftliche Mehrwert durch eine Reihe von CI-Schritten entsteht, die dem Benutzer dabei helfen, den Kontext, in dem er navigiert, in eine konsistente Aufgabendefinition zu übersetzen.
Wir können uns Marketingaufgaben wie die Durchführung einer Keyword-Recherche als Standardarbeitsanweisung vorstellen, die den Benutzer durch mehrere Schritte führt (so stellen wir uns die SOP zur Keyword-Ermittlung mit Agent WordLift vor)
4. Der große Wandel zu Just-in-Time-UX
Im traditionellen UX-Design sind Informationen vorbestimmt und können in Hierarchien, Taxonomien und vordefinierten UI-Mustern organisiert werden. Da KI zur Schnittstelle zur komplexen Informationswelt wird, erleben wir einen Paradigmenwechsel.
UI-Topologien verschwinden tendenziell und die Interaktion zwischen Mensch und KI bleibt überwiegend dialogisch. Just-in-time-unterstützte Workflows können dem Benutzer helfen, einen Workflow zu kontextualisieren und zu verbessern.
- Sie müssen Denken Sie an die Schaffung von Geschäftswertkonzentrieren Sie sich auf die Interaktive Reise des Benutzers und Erleichterung der Interaktion durch die Erstellung einer UX im Handumdrehen. Taxonomien bleiben ein strategischer Vorteil, sie arbeiten jedoch im Hintergrund, während der Benutzer von einer Aufgabe zur nächsten teleportiert wird, wie Yannis Paniaras von Microsoft kürzlich treffend beschrieben hat.
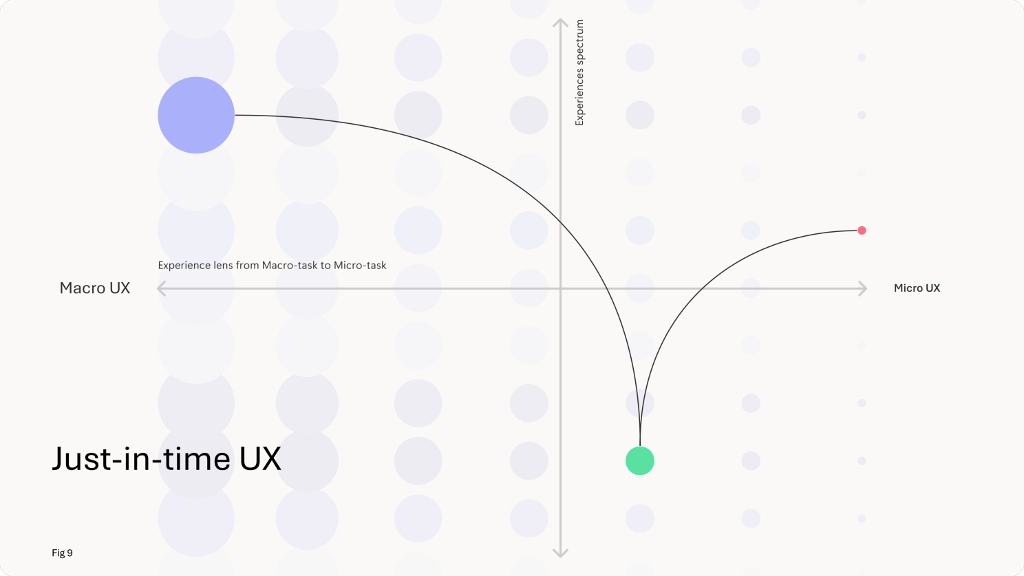 Bild aus „Der Wandel hin zu Just-In-Time-UX: Wie KI das Benutzererlebnis verändert“ von Yannis Paniaras, August 2024
Bild aus „Der Wandel hin zu Just-In-Time-UX: Wie KI das Benutzererlebnis verändert“ von Yannis Paniaras, August 20245. Von Agenten über RAG (und GraphRAG) bis hin zum Reporting
Da der Benutzer einen geschäftlichen Einfluss benötigt und RAG nur einen Teil der Lösung darstellt, verschiebt sich der Schwerpunkt schnell von allgemeineren Fragen und dem Beantworten von Benutzermustern zu erweiterten mehrstufigen Arbeitsabläufen.
Das größte Problem ist jedoch, welches Ergebnis der Benutzer benötigt. Wenn wir die Komplexität erhöhen, um die wichtigsten Geschäftsziele zu erreichen, reicht es nicht aus, beispielsweise „Ihre Daten abzufragen“ oder „mit Ihrer Website zu chatten“.
Ein Kunde möchte beispielsweise einen Bericht über die thematische Konsistenz der Inhalte auf der gesamten Website (dieses Konzept haben wir kürzlich als SiteRadus im massiven Datenleck von Google entdeckt), einen Überblick über die saisonalen Trends in Hunderten bezahlter Kampagnen oder eine abschließende Überprüfung der Optimierungsmöglichkeiten im Zusammenhang mit der Optimierung des Google Merchant Feed.
Sie müssen verstehen, wie das Geschäft funktioniert und für welche Leistungen Sie bezahlen. Welche konkreten Maßnahmen könnten das Geschäft voranbringen? Welche Fragen müssen beantwortet werden?
Dies ist der Beginn der Entwicklung eines enormen KI-gestützten Berichterstellungstools.
Wie kann ein Wissensgraph (KG) mit einer Ontologie zur KI-Ausrichtung, zum Langzeitgedächtnis und zur Inhaltsvalidierung gekoppelt werden?
Die drei Leitprinzipien hinter SEOntology:
- Interoperabilität von SEO-Daten um die Erstellung von Wissensgraphen zu erleichtern und gleichzeitig unnötige Crawls und die Abhängigkeit von Anbietern zu reduzieren;
- SEO-Know-how in KI-Agenten einbringen mithilfe einer domänenspezifischen Sprache.
- Gemeinsam Austausch von Wissen und Taktiken zur Verbesserung der Auffindbarkeit Und Missbrauch von Generativer KI verhindern.
Wenn Sie bei Ihrer SEO-Automatisierungsaufgabe mit mindestens zwei Datenquellen arbeiten, erkennen Sie bereits den Vorteil der Verwendung von SEOntology.
SEOntology als „das USB-C für SEO/Crawling-Daten“
Standardisierung von Daten über Content-Assets, Produkte, Benutzersuchverhalten und SEO-Erkenntnisse ist strategischDas Ziel besteht darin, eine „gemeinsame Darstellung“ des Webs als Kommunikationskanal zu haben.
Machen wir einen Schritt zurück. Wie stellt eine Suchmaschine eine Webseite dar? Das ist hier unser Ausgangspunkt. Können wir standardisieren, wie ein Crawler aus einer Website extrahierte Daten darstellt? Welche Vorteile bietet die Einführung von Standards?
Praktische Anwendungsfälle
Integration mit Botify und dynamischer interner Verlinkung
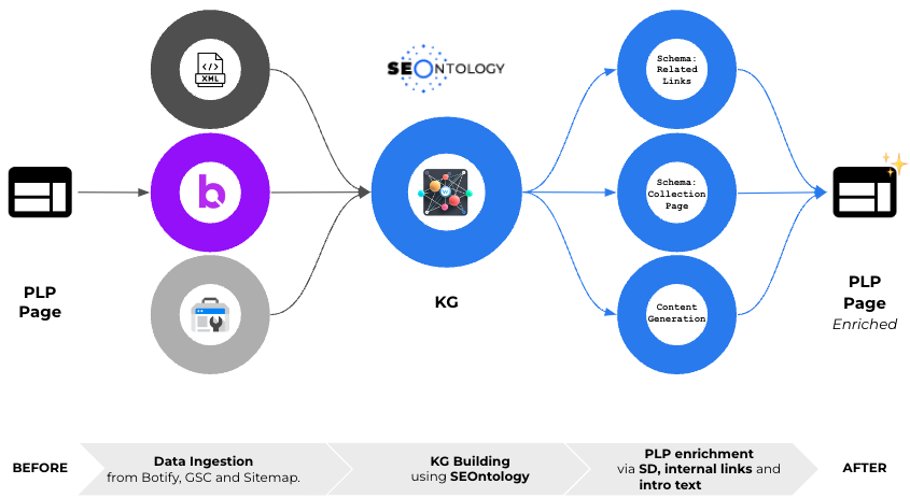
In den letzten Monaten haben wir eng mit dem Botify-Team zusammengearbeitet, um etwas Spannendes zu schaffen: einen Knowledge Graph, der auf den Crawl-Daten von Botify basiert und durch SEOntology erweitert wurde. Diese Zusammenarbeit eröffnet neue Möglichkeiten für die SEO-Automatisierung und -Optimierung.
Vorhandene Daten mit SEOntology nutzen
Und das ist das Coole daran: Wenn Sie Botify bereits verwenden, können wir diese Goldmine an Daten anzapfen, die Sie gesammelt haben. Sie brauchen dafür keine zusätzlichen Crawls oder zusätzliche Arbeit. Wir verwenden die Botify Query Language (BQL), um die benötigten Daten mit SEOntology zu extrahieren und zu transformieren.
Stellen Sie sich SEOntology als universellen Übersetzer für SEO-Daten vor. Es nimmt die komplexen Informationen von Botify und wandelt sie in ein Format um, das nicht nur maschinenlesbar, sondern auch maschinenverständlich ist. Auf diese Weise können wir einen umfangreichen, vernetzten Knowledge Graph erstellen, der mit wertvollen SEO-Erkenntnissen gefüllt ist.
Was das für Sie bedeutet
Sobald wir diesen Knowledge Graph haben, können wir einige ziemlich erstaunliche Dinge tun:
- Automatisierte strukturierte Daten: Wir können automatisch strukturierte Datenmarkierungen für Ihre Produktlistenseiten (PLPs) generieren. Dies hilft Suchmaschinen, Ihren Inhalt besser zu verstehen, und verbessert möglicherweise Ihre Sichtbarkeit in den Suchergebnissen.
- Dynamische interne Verlinkung: Hier wird es wirklich interessant. Wir verwenden die Daten im Knowledge Graph, um intelligente, dynamische interne Links auf Ihrer gesamten Site zu erstellen. Lassen Sie mich erklären, wie das funktioniert und warum es so leistungsstark ist.
Im folgenden Diagramm können wir auch sehen, wie Daten von Botify mit Daten aus der Google Search Console kombiniert werden können.
Während Botify diese Daten in den meisten Implementierungen bereits in seine Crawl-Projekte importiert, können wir, wenn dies nicht der Fall ist, eine neue API-Anfrage auslösen und Klicks, Impressionen und Positionen von GSC in das Diagramm importieren.
Zusammenarbeit mit Advertools für Dateninteroperabilität
Ebenso haben wir mit dem brillanten Elias Dabbas, dem Erfinder von Advertools – einer unter Vermarktern beliebten Python-Bibliothek – zusammengearbeitet, um ein breites Spektrum an Marketingaufgaben zu automatisieren.
Unsere gemeinsamen Bemühungen zielen darauf ab, die Dateninteroperabilität zu verbessern und eine nahtlose Integration und einen nahtlosen Datenaustausch zwischen verschiedenen Plattformen und Tools zu ermöglichen.
Im ersten Notebook, das im SEOntology GitHub-Repository verfügbar ist, zeigt Elias, wie wir mühelos Attribute für die WebPage-Klasse erstellen können, darunter Titel, Metabeschreibung, Bilder und Links. Auf dieser Grundlage können wir komplexe Elemente wie interne Verlinkungsstrategien einfach modellieren. Hier sehen Sie die Struktur:
- Interne Links
- AnkerTextInhalt
- NoFollow
- Link
Wir können auch ein Flag hinzufügen, wenn die Seite bereits Schema-Markup verwendet:
- verwendetSchema
Formalisierung unserer Erkenntnisse aus der Analyse der durchgesickerten Google-Suchdokumente
Obwohl wir bei der Ableitung von Taktiken oder kleinen Intrigen aus dem massiven Datenleck bei Google äußerst vorsichtig sein wollen und uns durchaus bewusst sind, dass Google jeden potenziellen Missbrauch dieser Informationen schnell verhindern wird, gibt es eine große Menge an Informationen, die – basierend auf dem, was wir gelernt haben – dazu verwendet werden können, die Darstellung unserer Webinhalte und die Organisation unserer Marketingdaten zu verbessern.
Trotz dieser Einschränkungen bietet das Leck wertvolle Erkenntnisse zur Verbesserung der Darstellung von Webinhalten und der Organisation von Marketingdaten. Um den Zugriff auf diese Erkenntnisse zu demokratisieren, habe ich ein Google Leak Reporting-Tool entwickelt, das diese Informationen SEO-Profis und digitalen Vermarktern leicht zugänglich machen soll.
Besonders aufschlussreich war beispielsweise das Verständnis des Klassifizierungssystems von Google und seiner Segmentierung von Websites in verschiedene Taxonomien. Diese Taxonomien – wie „Verticals4“, „Geo“ und „Products_Services“ – spielen eine entscheidende Rolle bei der Suchrangfolge und -relevanz. Jede Taxonomien hat einzigartige Attribute, die beeinflussen, wie Websites und Inhalte in Suchergebnissen wahrgenommen und eingestuft werden.
Durch den Einsatz von SEOntology können wir einige dieser Attribute übernehmen, um die Website-Darstellung zu verbessern.
Halten Sie jetzt einen Moment inne und stellen Sie sich vor, Sie würden die komplexen SEO-Daten, die Sie täglich mit Tools wie Moz, Ahrefs, Screaming Frog, Semrush und vielen anderen verwalten, in ein interaktives Diagramm umwandeln. Stellen Sie sich jetzt einen autonomen KI-Agenten wie Agent WordLift an Ihrer Seite vor.
Dieser Agent verwendet neurosymbolische KI, einen hochmodernen Ansatz, der neuronale Lernfähigkeiten mit symbolischem Denken kombiniert, um SEO-Aufgaben wie das Erstellen und Aktualisieren interner Links zu automatisieren. Dies rationalisiert Ihren Arbeitsablauf und führt zu einem bisher unerreichten Maß an Präzision und Effizienz.
SEOntology dient als Rückgrat dieser Vision und bietet ein strukturiertes Framework, das den nahtlosen Austausch und die Wiederverwendung von SEO-Daten über verschiedene Plattformen und Tools hinweg ermöglicht. Durch die Standardisierung der Darstellung und Verknüpfung von SEO-Daten stellt SEOntology sicher, dass wertvolle Erkenntnisse, die aus einem Tool gewonnen werden, problemlos von anderen angewendet und genutzt werden können. Beispielsweise könnten Daten zur Keyword-Performance von SEMrush in Content-Optimierungsstrategien in WordLift einfließen – und das alles in einer einheitlichen, interoperablen Umgebung. Dies maximiert nicht nur den Nutzen vorhandener Daten, sondern beschleunigt auch die Automatisierungs- und Optimierungsprozesse, die für effektives Marketing entscheidend sind.
SEO-Know-how in KI-Agenten einbringen
Während wir einen neuen agentenbasierten Ansatz für SEO und digitales Marketing entwickeln, dient uns SEOntology als domänenspezifische Sprache (DSL) zur Kodierung von SEO-Fähigkeiten in KI-Agenten. Sehen wir uns ein praktisches Beispiel an, wie das funktioniert.
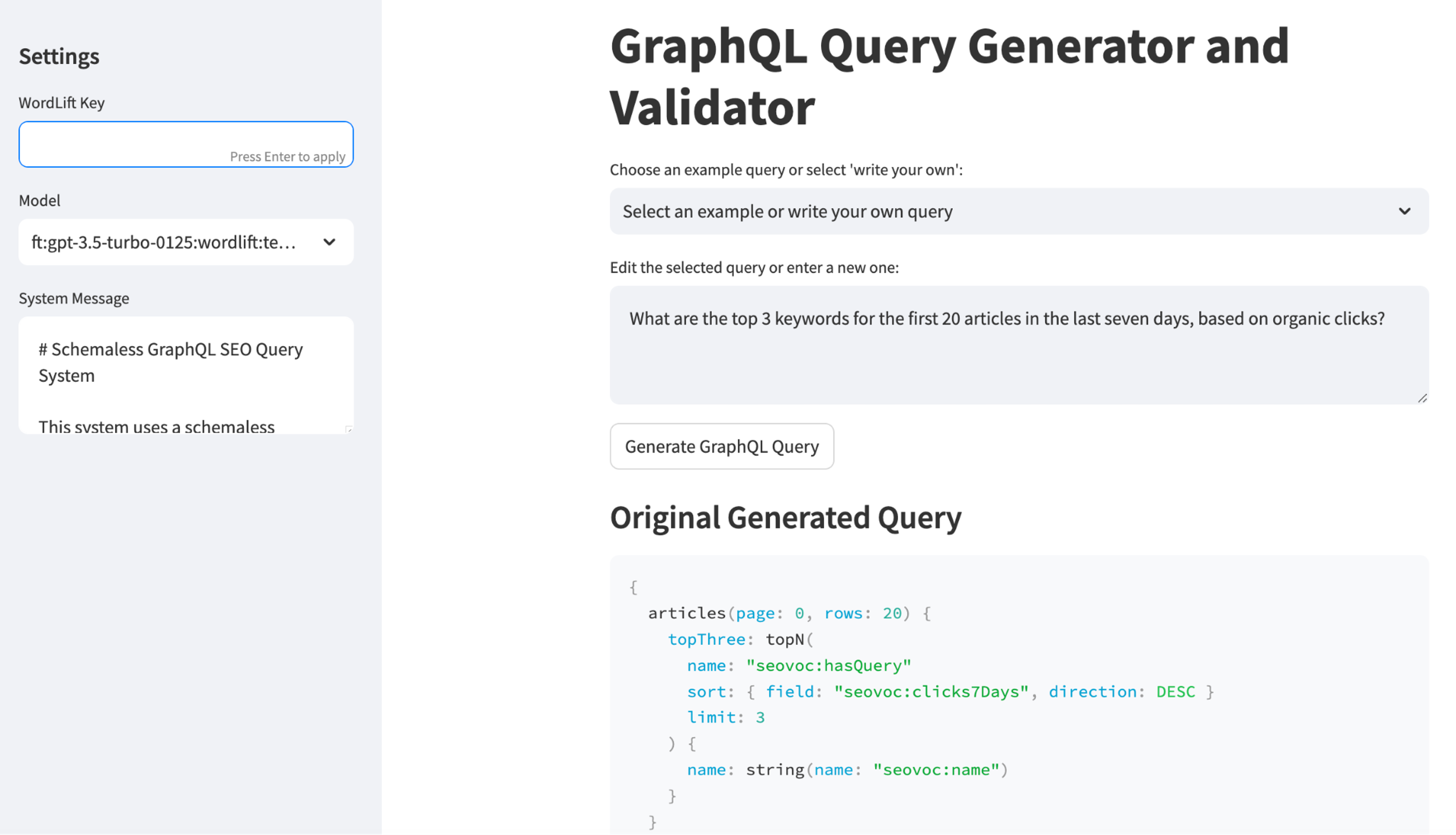 Screenshot von WordLift, August 2024
Screenshot von WordLift, August 2024Wir haben ein System entwickelt, das KI-Agenten auf die organische Suchleistung einer Website aufmerksam macht, bling eine neue Art der Interaktion zwischen SEO-Profis und KI. So funktioniert der Prototyp:
Systemkomponenten
- Wissensgraph: Speichert mit SEOntology codierte Daten der Google Search Console (GSC).
- LL.M.: Übersetzt natürlichsprachliche Abfragen in GraphQL und analysiert Daten.
- KI-Agent: Bietet Erkenntnisse basierend auf den analysierten Daten.
Mensch-Agent-Interaktion
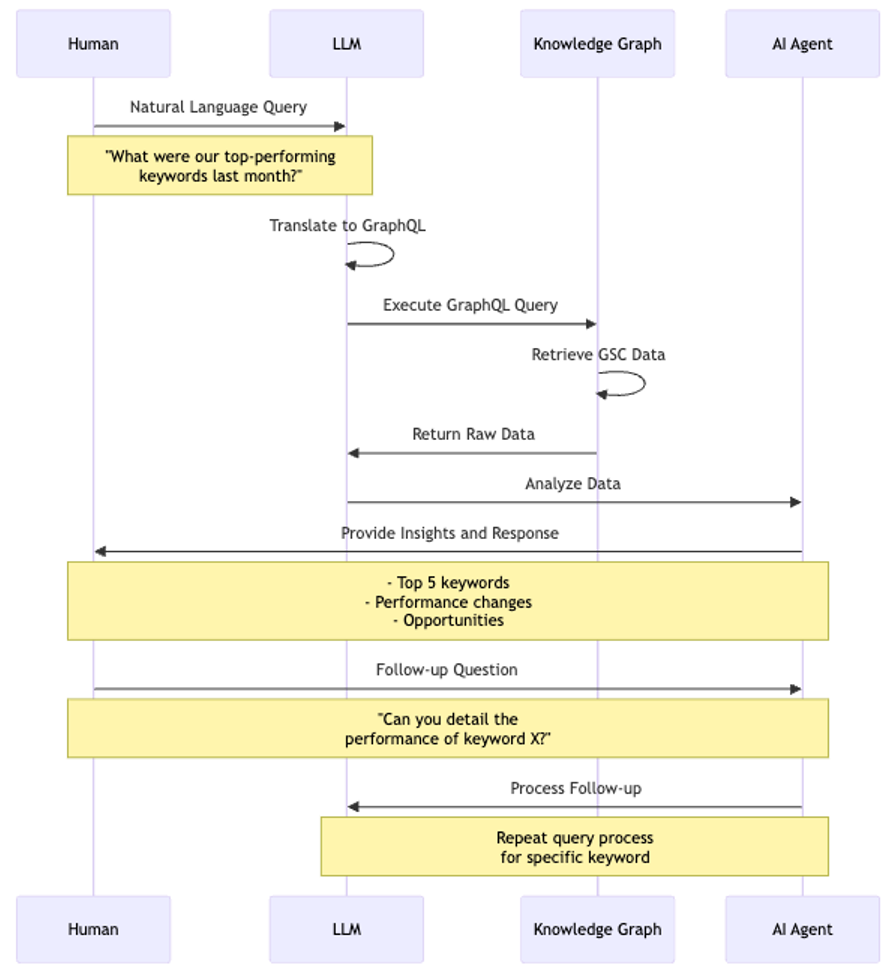 Bild vom Autor, August 2024
Bild vom Autor, August 2024Das Diagramm veranschaulicht den Ablauf einer typischen Interaktion. Das macht diesen Ansatz so wirkungsvoll:
- Natürliche Sprachschnittstelle: SEO-Experten können Fragen in einfacher Sprache stellen, ohne komplexe Abfragen zu konstruieren.
- Kontextuelles Verständnis: Der LLM versteht SEO-Konzepte und ermöglicht daher differenziertere Fragen und Antworten.
- Aufschlussreiche Analyse: Der KI-Agent ruft nicht nur Daten ab; er bietet auch umsetzbare Erkenntnisse, beispielsweise:
- Identifizieren der Keywords mit der besten Leistung.
- Hervorhebung wesentlicher Leistungsänderungen.
- Vorschläge zur Optimierung.
- Interaktive Erkundung: Benutzer können Folgefragen stellen und so die SEO-Leistung dynamisch untersuchen.
Indem wir SEO-Wissen durch SEOntology kodieren und Leistungsdaten integrieren, erstellen wir KI-Agenten, die kontextbezogene, differenzierte Unterstützung bei SEO-Aufgaben bieten können. Dieser Ansatz schließt die Lücke zwischen Rohdaten und umsetzbaren Erkenntnissen und macht fortgeschrittene SEO-Analysen für Fachleute auf allen Ebenen zugänglicher.
Dieses Beispiel zeigt, wie uns eine Ontologie wie SEOntology dabei helfen kann, agentenbasierte SEO-Tools zu entwickeln, die komplexe Aufgaben automatisieren, dabei aber die menschliche Aufsicht beibehalten und qualitativ hochwertige Ergebnisse sicherstellen. Es ist ein Blick in die Zukunft der SEO, in der KI die menschliche Expertise ergänzt, anstatt sie zu ersetzen.
Human-In-The-Loop (HTIL) und kollaborativer Wissensaustausch
Lassen Sie es uns ganz klar sagen: Während KI SEO und Suche revolutioniert, sind Menschen das schlagende Herz unserer Branche. Wenn wir tiefer in die Welt der SEOntologie und KI-gestützter Workflows eintauchen, ist es wichtig zu verstehen, dass Human-in-the-Loop (HITL) nicht nur ein schickes Add-on ist – es ist die Grundlage von allem, was wir bauen.
Der Kern der Entwicklung von SEOntology besteht darin, unser kollektives SEO-Know-how auf Maschinen zu übertragen und gleichzeitig sicherzustellen, dass wir als Menschen fest am Steuer sitzen. Es geht nicht darum, der KI die Schlüssel zu übergeben; es geht darum Wir lehren es, der ultimative Co-Pilot auf unserer SEO-Reise zu sein.
Von Menschen gesteuerte KI: Das unersetzliche menschliche Element
SEOntology ist mehr als ein technisches Framework – es ist ein Katalysator für kollaborativen Wissensaustausch, der das menschliche Potenzial in der SEO betont. Unser Engagement geht über Code und Algorithmen hinaus und zielt darauf ab, Fähigkeiten und Kompetenzen von Vermarktern und SEO-Profis der neuen Generation zu fördern und zu erweitern.
Warum? Weil die wahre Kraft der KI in der SEO durch menschliche Einsicht, unterschiedliche Perspektiven und Erfahrungen aus der Praxis freigesetzt wird. Nach jahrelanger Arbeit mit KI-Workflows ist mir klar geworden, dass agentenbasierte SEO grundsätzlich auf den Menschen ausgerichtet ist. Wir ersetzen Fachwissen nicht, wir verstärken es.
Wir liefern effizientere und vertrauenswürdigere Ergebnisse, indem wir Spitzentechnologie mit menschlicher Kreativität, Intuition und ethischem Urteilsvermögen kombinieren. Dieser Ansatz schafft Vertrauen bei Kunden innerhalb unserer Branche und im gesamten Internet.
Hier bleibt der Mensch unersetzlich:
- Geschäftsanforderungen verstehen: KI kann Zahlen verarbeiten, aber das differenzierte Verständnis der Geschäftsziele erfahrener SEO-Experten nicht ersetzen. Wir brauchen Experten, die Kundenziele in umsetzbare SEO-Strategien umsetzen können.
- Identifizieren von Clienteinschränkungen: Jedes Unternehmen ist einzigartig und hat seine Grenzen und Möglichkeiten. Es bedarf menschlicher Einsicht, um diese Einschränkungen zu bewältigen und maßgeschneiderte SEO-Ansätze zu entwickeln, die innerhalb realer Parameter funktionieren.
- Entwicklung hochmoderner Algorithmen: Die Algorithmen hinter unseren KI-Tools kommen nicht aus dem Nichts. Wir brauchen brillante Köpfe, die hochmoderne Algorithmen entwickeln, aus menschlichem Input lernen und sich kontinuierlich verbessern.
- Entwicklung robuster Systeme: Hinter jedem reibungslos funktionierenden KI-Tool steht ein Team von Softwareentwicklern, die dafür sorgen, dass unsere Systeme schnell, sicher und zuverlässig sind. Diese menschliche Expertise sorgt dafür, dass unsere KI-Assistenten wie gut geölte Maschinen laufen.
- Leidenschaft für ein besseres Web: Im Mittelpunkt von SEO steht das Engagement, das Internet zu einem besseren Ort zu machen. Wir brauchen Leute, die Tim Berners‘ – Lees Vision teilen – Leute, die mit Leidenschaft das Web der Daten weiterentwickeln und das digitale Ökosystem für alle verbessern wollen.
- Ausrichtung der Gemeinschaft und Resilienz: Wir müssen uns zusammentun, um das Verhalten der Suchmaschinengiganten zu analysieren und belastbare Strategien zu entwickeln. Es geht darum, unsere Probleme innovativ zu lösen, als Individuen und als kollektive Kraft. Das ist es, was ich an der SEO-Branche immer geliebt habe!
Die Reichweite von SEOntology erweitern
Bei der Weiterentwicklung von SEOntology agieren wir nicht isoliert, sondern bauen auf bestehenden Standards auf, insbesondere Schema.org, und orientieren uns am erfolgreichen Modell des GS1 Web Vocabulary.
SEOntology als Erweiterung von Schema.org
Schema.org hat sich zum De-facto-Standard für strukturierte Daten im Web entwickelt und bietet ein gemeinsames Vokabular, das Webmaster zum Markieren ihrer Seiten verwenden können.
Obwohl Schema.org ein breites Spektrum an Konzepten abdeckt, geht es nicht tief in SEO-spezifische Elemente ein. Hier kommt SEOntology ins Spiel.
Eine Erweiterung von Schema.org, wie beispielsweise SEOntology, ist im Wesentlichen ein ergänzendes Vokabular, das dem Kernvokabular von Schema.org neue Typen, Eigenschaften und Beziehungen hinzufügt.
Dadurch können wir die Kompatibilität mit vorhandenen Schema.org-Implementierungen aufrechterhalten und gleichzeitig SEO-spezifische Konzepte einführen, die im Kernvokabular nicht abgedeckt sind.
Lernen vom GS1-Webvokabular
Das GS1 Web Vocabulary bietet ein hervorragendes Modell zum Erstellen einer erfolgreichen Erweiterung, die nahtlos mit Schema.org interagiert. GS1, eine globale Organisation, die Standards für Lieferketten entwickelt und pflegt, hat sein Web Vocabulary erstellt, um Schema.org für Anwendungsfälle im Bereich E-Commerce und Produktinformationen zu erweitern.
Das GS1 Web Vocabulary zeigt bereits seit Kurzem, wie branchenspezifische Erweiterungen die Schema-Auszeichnung beeinflussen und mit ihr interagieren können:
- Auswirkungen auf die reale Welt: Die Eigenschaft https://schema.org/Certification, die jetzt offiziell von Google übernommen wurde, stammt ursprünglich von GS1s https://www.gs1.org/voc/CertificationDetails. Dies zeigt, wie Erweiterungen die Entwicklung von Schema.org und Suchmaschinenfunktionen vorantreiben können.
Wir möchten einen ähnlichen Ansatz verfolgen, um Schema.org zu erweitern und zum Standardvokabular für SEO-bezogene Anwendungen zu werden, was möglicherweise zukünftige Suchmaschinenfunktionen, KI-gesteuerte Arbeitsabläufe und SEO-Praktiken beeinflusst.
So wie GS1 seinen Namespace (gs1:) beim Verweisen auf Schemabegriffe definiert hat, haben wir unseren Namespace (seovoc:) definiert und integrieren die Klassen, wenn möglich, in die Schema.org-Hierarchie.
Die Zukunft der SEOntologie
SEOntology ist mehr als nur ein theoretischer Rahmen; es ist ein praktisches Tool, das SEO-Experten und Tool-Herstellern in einem zunehmend KI-gesteuerten Ökosystem helfen soll.
So können Sie mit SEOntology interagieren und davon profitieren.
Wenn Sie SEO-Tools entwickeln:
- Dateninteroperabilität: Implementieren Sie SEOntology, um Daten in einem standardisierten Format zu exportieren und zu importieren. Dadurch wird sichergestellt, dass Ihre Tools problemlos mit anderen SEOntology-kompatiblen Systemen interagieren können.
- KI-fähige Daten: Indem Sie Ihre Daten gemäß SEOntology strukturieren, machen Sie sie für KI-gesteuerte Automatisierungen und Analysen zugänglicher.
Wenn Sie ein SEO-Profi sind:
- Beitrag zur Entwicklung: Genau wie bei Schema.org können Sie zur Entwicklung von SEOntology beitragen. Besuchen Sie das GitHub-Repository, um:
- Sprechen Sie Probleme mit neuen Konzepten oder Eigenschaften an, die Ihrer Meinung nach aufgenommen werden sollten.
- Schlagen Sie Änderungen an bestehenden Definitionen vor.
- Beteiligen Sie sich an Diskussionen über die zukünftige Ausrichtung von SEOntology.
- Implementieren Sie in Ihre Arbeit: Beginnen Sie mit der Verwendung von SEOntology-Konzepten in Ihren strukturierten Daten.
Wir vertrauen auf Open Source
SEOntology ist ein Open-Source-Projekt, das in die Fußstapfen erfolgreicher Projekte wie Schema.org und anderer gemeinsam genutzter verknüpfter Vokabulare tritt.
Alle Diskussionen und Entscheidungen werden öffentlich sein, sodass die Community bei der Ausrichtung von SEOntology mitreden kann. Sobald wir an Fahrt gewinnen, werden wir ein Komitee einrichten, das die Entwicklung steuert und regelmäßige Updates veröffentlicht.
Schlussfolgerung und zukünftige Arbeit
Die Zukunft des Marketings wird vom Menschen geleitet und nicht durch KI ersetzt. SEOntologie ist nicht nur ein weiteres Schlagwort – es ist ein Schritt in diese Zukunft. SEO ist von strategischer Bedeutung für die Entwicklung von Praktiken des aktiven Marketings.
Bei SEO geht es nicht mehr um Rankings; es geht darum, intelligente, adaptive Inhalte und fruchtbare Dialoge mit unseren Stakeholdern über verschiedene Kanäle hinweg zu erstellen. Die Standardisierung von SEO-Daten und -Praktiken ist von strategischer Bedeutung, um eine nachhaltige Zukunft aufzubauen und in verantwortungsvolle KI zu investieren.
Sind Sie bereit, sich dieser Revolution anzuschließen?
Hinter der Arbeit von SEOntology stehen drei Leitprinzipien, die wir dem Leser klar machen müssen:
- Da KI semantische Daten benötigt, müssen wir SEO-Daten interoperabel machen und die Erstellung von Wissensgraphen für alle erleichtern. SEOntology ist das USB-C für SEO/Crawling-Daten. Die Standardisierung von Daten über Content-Assets und Produkte und darüber, wie Menschen Inhalte, Produkte und Informationen im Allgemeinen finden, ist wichtig. Dies ist das erste Ziel. Hier haben wir zwei praktische Anwendungsfälle. Wir haben einen Connector für WordLift, der Crawling-Daten vom Botify-Crawler erhält und Ihnen hilft, ein KG zu starten, das SEOntology als Datenmodell verwendet. Wir arbeiten auch mit Advertools, einem Open-Source-Crawler und SEO-Tool, um Daten mit SEOntology interoperabel zu machen;
- Während wir mit der Entwicklung einer neuen agentenbasierten Methode für SEO und digitales Marketing fortfahren, möchten wir SEO-Know-how mithilfe von SEOntology einbringen, einer domänenspezifischen Sprache, um SEO-Agenten (oder Multi-Agent-Systemen wie Agent WordLift) die SEO-Denkweise zu vermitteln. In diesem Zusammenhang wird die zum Erstellen dynamischer interner Links erforderliche Fähigkeit als Knoten in einem Wissensgraphen kodiert, und Gelegenheiten werden zu Auslösern zum Aktivieren von Workflows.
- Wir gehen davon aus, dass wir mit Human-in-the-Loop (HITL) arbeiten werden. Das bedeutet, dass die Ontologie zu einer Möglichkeit wird, gemeinsam Wissen und Taktiken auszutauschen, die dazu beitragen, die Auffindbarkeit zu verbessern und den Missbrauch generativer KI zu verhindern, der das Internet heute verschmutzt.
Projektübersicht
- SEOntology – Projektübersicht – WordLift
- Öffentliches Repository
- Thread auf X
- F&E-Arbeit
- 6125 K-LAM – Erweiterung großer Aktionsmodelle mit Wissensgraphen.docx
Weitere Ressourcen:
- KI hat die Funktionsweise der Suche verändert
- Nutzung generativer KI-Tools für SEO
- Wie Suchmaschinen funktionieren
Vorgestelltes Bild: tech_BG/Shutterstock





